







参考别人的笔记: 【我是土堆 - PyTorch教程】学习随手记
1.神经网络的基本骨架 - nn.Module 的使用
其中最常用的是 Module 模块(为所有神经网络提供基本骨架)
具体可以去官网查看,torch.nn
import torch
from torch import nn
class Tudui(nn.Module): ##搭建的神经网络 Model继承了 Module类(父类)
# def __init__(self, *args, **kwargs) -> None:
# super().__init__(*args, **kwargs) #使用code--generater--override
def __init__(self): #初始化函数
super(Tudui,self).__init__() #调用父类的初始化函数
def forward(self,input): #前向传播(为输入和输出中间的处理过程),input为输入
output=input+1
return output
tudui=Tudui() #实例化
x=torch.tensor(1.0) #tensor类型的
output=tudui(x)
print(output) #tensor(2.)
2.卷积操作
Convolution Layers
Convolution Layers–CONV2D
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
print(input.shape) #torch.Size([5, 5]) 不符合卷积操作CONV2D的输入
print(kernel.shape) #torch.Size([3, 3])
#尺寸变换
# CONV2D 对由多个输入平面组成的输入信号应用 2D 卷积。
# input:尺寸要求是batch,几个通道,高,宽(4个参数)
# torch.reshape 函数,将输入改变为要求输入的维度
input=torch.reshape(input,[1,1,5,5]) #batch设置为1,1个通道
#weight:尺寸要求是输出,in_channels(groups一般为1),高,宽(4个参数)
kernel=torch.reshape(kernel,[1,1,3,3])
print(input.shape)
print(kernel.shape)
# 第二个属性:weight,权重或卷积核
#stride:可以为一个数或者一个元组,控制横向步进和纵向步进
output=F.conv2d(input,kernel,stride=1)
print(output)
output2=F.conv2d(input,kernel,stride=2)
print(output2)
#padding(填充)目的:充分利用边缘信息
# 在输入图像左右两边进行填充,决定填充有多大。可以为一个数或一个元组(分别指定高和宽,即纵向和横向每次填充的大小)。默认情况下不进行填充
# padding=1:将输入图像左右上下两边都拓展一个像素,空的地方默认为0
output3=F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
3.卷积层
图像为二维矩阵,所以讲解 nn.Conv2d
"""
Conv2d:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,
dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数讲解:
in_channels 输入通道数,彩色图像 in_channels 值为3
out_channels 输出通道数
kernel_size 卷积核大小
stride=1 卷积过程中的步进大小,控制横向步进和纵向步进
padding=0 在输入图像左右两边进行填充,决定填充有多大。
dilation=1 每一个卷积核对应位的距离
groups=1 一般设置为1,很少改动,改动的话为分组卷积
bias=True 通常为True,对卷积后的结果是否加减一个常数的偏置
padding_mode='zeros' 选择padding填充的模式
"""
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./datasets",train=False,transform=torchvision.transforms.ToTensor(),
download=True) #数据集
dataloader=DataLoader(dataset,batch_size=64) #数据加载器,一个批次是64张图片
#定义卷积神经网络
class Tu(nn.Module):
def __init__(self):
super(Tu,self).__init__()#父类的初始化
self.conv1=Conv2d(3,6,3,stride=1,padding=0) #定义卷积层
def forward(self,x):
x=self.conv1(x) #传入数据
return x
#初始化网络
snow=Tu()
print(snow)
writer=SummaryWriter("./logs")
step=0
for data in dataloader:
imgs,target=data
output=snow(imgs)
# print(imgs.shape)
# print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
# torch.Size([64, 6, 30, 30]) 需要变成--->[不确定,3,30,30] 用transformer显示图像,其通道数核大小最好保持一致
output=torch.reshape(output,[-1,3,30,30]) #改变output的形状 batchsize为-1,表示模糊形状,由touch计算
writer.add_images("output",output,step)
step+=1
writer.close()
4.最大池化的作用
Pooling layers
MaxPool:最大池化(下采样)
MaxUnpool:上采样
AvgPool:平均池化
AdaptiveMaxPool2d:自适应最大池化
MaxPool2d:
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./datasets",train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
#定义卷积神经网络
class Tu(nn.Module):
def __init__(self):
super(Tu,self).__init__() #父类初始化
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=False)
#kernel_size:池化核大小,stride默认等于池化核大小
#ceil_mode=true,使用ceil模式(向上取整),而不是floor(向下取整).只覆盖部分区域时,是否进行保留
def forward(self,input):
output=self.maxpool(input)
return output
snow=Tu()
writer=SummaryWriter("logs")
step=0
for data in dataloader:
imgs,target=data
output=snow(imgs)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step+=1
writer.close()
"""
为什么要进行最大池化?最大池化的作用是什么?
答:最大池化的目的是保留输入的特征,同时把数据量减小(数据维度变小),对于整个网络来说,进行计算的参数变少,会训练地更快
例如:1080p的视频为输入图像,经过池化可以得到720p,也能满足绝大多数需求,传达视频内容的同时,文件尺寸会大大缩小
池化一般跟在卷积后,卷积层是用来提取特征的,池化不影响通道数,池化后一般再进行非线性激活
"""
5.非线性激活
Non-linear Activations (weighted sum, nonlinearity)
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 非线性变换:给我们网络中引入一些非线性特征,非线性越多,才能训练出符合各种曲线或特征的模型(提高泛化能力)
#ReLU :小于0的数返回0,大于0的数保持不变
# sigmoid
input=torch.tensor([[1,-0.5],
[-1,3]])
print(input.shape)
dataset=torchvision.datasets.CIFAR10("./datasets",train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
writer=SummaryWriter("logs")
step=0
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.relu1=ReLU()
# 参数:inplace:True 会对原值进行改变,若input=-1,则input值变为=0
# inplace:False(默认值) 不会对原值进行改变,若input=-1,则output=0,input的值保持不变
self.sigmoid1=Sigmoid()
def forward(self,input):
output=self.sigmoid1(input)
return output
snow=Tudui()
for data in dataloader:
imgs,targets=data
output=snow(imgs)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step+=1
writer.close()
6.线性层及其他层介绍
Linear Layers
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./datasets",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.liner1=Linear(196608,10)
def forward(self,input):
output=self.liner1(input)
return output
snow=Tudui() #实例化,创建对象
for data in dataloader:
imgs,target=data
print(imgs.shape) #torch.Size([64, 3, 32, 32]) ,batch_size=64,通道数等于3,照片尺寸是32*32
#output=torch.reshape(imgs,[1,1,1,-1]) #以指定尺寸进行变换
output=torch.flatten(imgs) #变成1行,摊平
print(output.shape) #torch.Size([1, 1, 1, 196608]) ,batch_size=1,通道数设置为1,展成一行,最后一个数就是照片的大小(size)
output=snow(output)
print(output.shape)
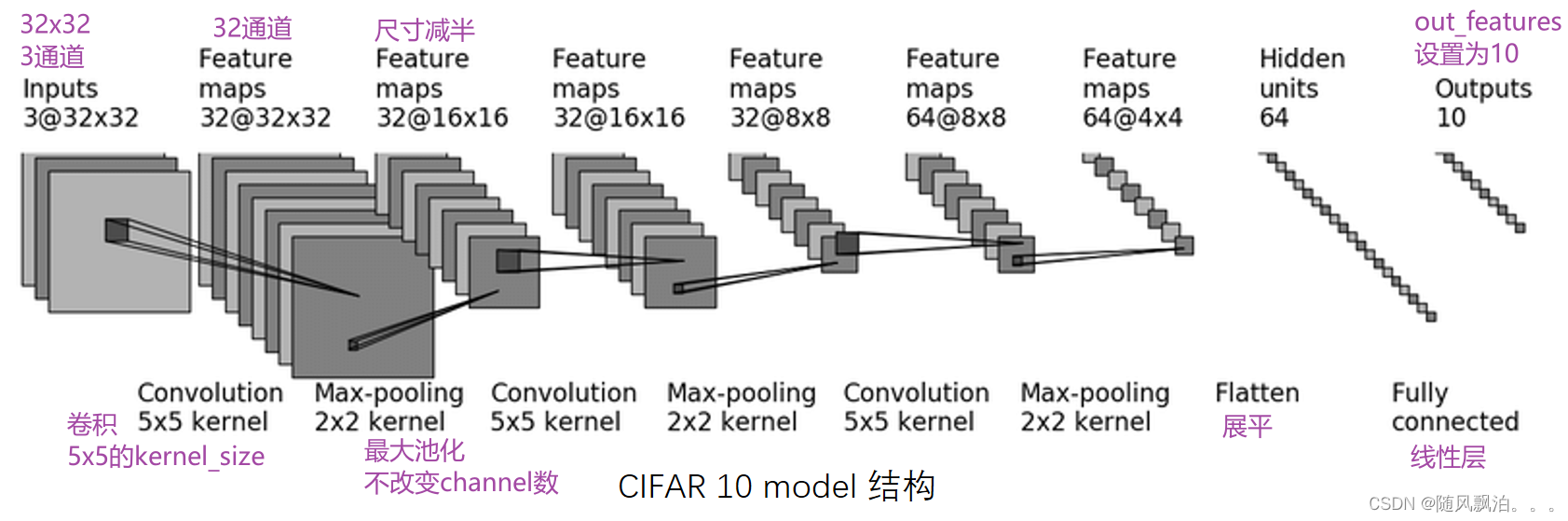
7.
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module): #搭建模型
def __init__(self):
super(Tudui,self).__init__()
# self.conv1=Conv2d(3,32,5,padding=2,stride=1)
# #padding=2,stride=1 通过公式计算而来,根据输入输出的高和宽分别计算
# self.maxpool=MaxPool2d(2)
# self.conv2=Conv2d(32,32,5,padding=2,stride=1)
# self.maxpool2=MaxPool2d(2)
# self.conv3=Conv2d(32,64,5,padding=2)
# self.maxpool3=MaxPool2d(2)
# self.flatten=Flatten()#展平
# self.liner1=Linear(1024,64)
# self.liner2=Linear(64,10)
self.module1=Sequential( #把上述的步骤进行简单化
Conv2d(3, 32, 5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(), # 展平,
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,input):
# input=self.conv1(input)
# input=self.maxpool(input)
# input=self.conv2(input)
# input=self.maxpool2(input)
# input=self.conv3(input)
# input=self.maxpool3(input)
# input=self.flatten(input)
# input=self.liner1(input)
# input=self.liner2(input)
output=self.module1(input)
return output
tudui=Tudui()
print(tudui)
input=torch.ones((64,3,32,32)) #对搭建的模型进行检验
output=tudui(input)
print(output.shape)
#可视化
writer=SummaryWriter("./logs")
writer.add_graph(tudui,input)
writer.close()















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









