







论文标题
论文作者、链接
作者:Yin, Yihang and Wang, Qingzhong and Huang, Siyu and Xiong, Haoyi and Zhang, Xiang
链接:https://arxiv.org/abs/2109.10259
代码:https://github.com/Somedaywilldo/AutoGCL
链接为arxiv的版本,本文已经被AAAI接收
Introduction逻辑(论文动机&现有工作存在的问题)
图神经网络GNN——现有的GNN往往是端到端的有监督模式——出现了无监督式的策略——对比学习的兴起(它们通常不能针对原始图的语义生成视图,也不能针对特定的图学习任务调整增强策略)——由于图像语义在各种变换下的不变性,图像数据增强被广泛用于生成对比视图——然而,在这里使用图谱数据增广可能是无效的,因为图上的转换可能会严重破坏其语义和特征——本文AutoGCL
论文核心创新点
提出了一个图对比学习框架,含有可学习的图谱视图生成器
联合训练策略
相关工作
图神经网络
将一个图谱记为,其中结点特征为
有
。本文聚焦于图分类任务,通过图神经网(GNN)。GNN通过聚合结点
及其邻居来生成结点级嵌入
。GNN的每一层都是一次聚合的迭代,在第
层之后嵌入的节点将信息聚合到其k-hop邻域内。第
层的GNN公式表示如下:
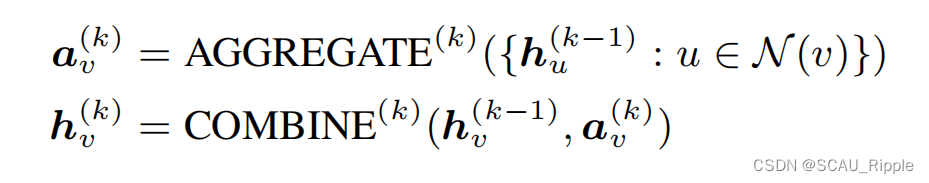
对于下游任务诸如图分类,图谱级特征通过READOUT函数和MLP获得,公式如下:

本文使用了两种GNN作为主干,GIN和ResGCN
图神经网络的预训练
图迁移学习的好处可能是有限的,并导致负迁移,因为来自不同领域的图实际上在结构、规模和节点/边缘属性方面存在很大差异。因此,以下许多工作开始探索另一种方法,即针对gnn预训练的对比学习
对比学习
可学习的数据增广
比起现有的对比学习模型,本文方法可以从原始图谱保存更多的语义结构信息。
论文方法

如何设计一个好的图视图生成器
一个理想的用于数据扩展和对比学习的图视图生成器应该满足以下特性:
(1)同时支持增广图拓扑结构以及结点特征。
(2)具有标签保持性,即增强图应保持原图的语义信息。
(3)适应不同的数据分布,可扩展到大型图。
(4)为对比多视图训练前提供足够的方差。
(5)它是端到端可微的,对于反向传播(BP)梯度快速计算足够有效。
本文的视图生成器包括:结点丢弃和特征掩膜,但又比这两种方法更为的灵活。
可学习的图谱视图生成器

视图生成器如上图所示。首先使用GIN来从结点特征获得结点嵌入。对于每一个结点,使用结点的嵌入结点特征来预测选择一个数据增广方法的概率。结点数据增广的方法包括:丢弃,保持和掩膜。本文使用gumbel-softamx从这些概率中采样,然后给每个节点分配一个增强操作。如果采用个GIN层作为嵌入层,那么将
记为结点
在第
层的隐藏状态,
记为结点
在第
层的嵌入。对于每一个结点
都有结点特征
,增广选择
以及应用数据增广的函数
。结点
的增广特征
通过以下公式获得:

将最后一层的维度设为每个节点的可能增广次数。
记作选择某种数据增广的概率。
是通过gumbel-softmax得到的分布中采集的one-hot向量。增广应用函数
通过不同的操作结合结点
和
。对于增广后的图谱,边缘通过对所有的
使用操作
进行更新,当结点被移除时,边也被删除。由于边缘只是节点特征聚合的指导,不参与梯度计算,因此不需要以可微的方式更新。因此,视图生成器是端到端可微的。GIN嵌入层和gumbel-softmax可以有效地扩展到更大的图数据集和更多的扩展选择。
对比预训练策略
因为对比学习需要多视图,本文使用两个视图生成器和一个分类器。一个对比学习的好的视图一个最大化标签依赖的信息同时最小化互信息。
损失函数定义
总共含有三个损失函数:对比损失,相似性损失和分类损失。
对于对比损失,使用正则化温度参数以及交叉熵损失。相似性函数定义如下:
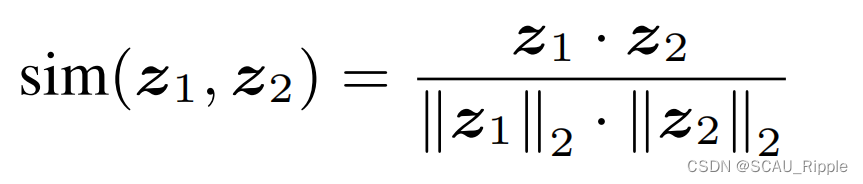
假设有一个数据batch由 个图谱组成。通过数据增广后得到2
个图谱视图,将同一个图谱增广后得到的两个图谱作为正样本对。用
作为指示函数。将正样本对
的对比损失记作
,一个batch的对比损失为
,温度参数为
,则有:

这个相似性损失用来最小化视图之间的互信息。在视图生成的过程中,有一个采样的状态矩阵,表示每个节点对应的增强操作(见图1)。对于图谱
,将增广的视图结果记作
,则相似性损失
为:
![]()
对于分类损失,直接使用交叉熵衡量。对于一个图样本其类标为
,将数据增广结果记为
并且分类器记为
,则分类损失
为:
![]()
在半监督训练前任务中使用来鼓励视图生成器生成保留标签的增强。
简单的训练策略
对于无监督学习和迁移学习任务,使用一个简单的训练策略。因为现阶段只知道预训练过程中保存的标签,因此将不会被使用,因为这个损失仅仅鼓励视图变得不同,这是没有意义的,会生成无用深知有害的样本视图。本文将只训练视图生成器以及分类器,来最小化
。
本文注意到生成的视图的质量不等同于原始数据的质量。在最小化的过程中,不仅仅是两个增广视图之间最小化,而且对原始数据也进行最小化。通过在嵌入空间中使得原始数据以及增广之间的距离缩小,鼓励视图生成器保存与标签相关的信息。具体细节在算法1中描述。

联合训练策略
针对半监督学习,本文提出了一个联合训练策略,交替进行对比学习和有监督学习策略。这种情况下的效果比简单训练策略要好。
在无监督训练阶段,先固定一个视图生成器,然后通过对比学习训练分类器。在有监督学习,使用有标签的数据同时训练视图生成器和分类器。通过同时优化和
,这两个视图生成器被鼓励生成保留标签的增强,但视图之间彼此足够不同。无监督训练阶段和有监督训练阶段交替重复。
作者发现在图对比学习中,预训练/精调策略会在精调阶段出现过拟合情况。而将最小化过多可能会对精调阶段产生负面影响。作者推测,将
最小化太多会使靠近决策边界的数据点彼此过于靠近,从而使分类器更难将它们分离。因为无论如何训练GNN分类器,由于不同类的数据分布之间的自然重叠,仍然存在误分类的样本。但是在对比训练前的状态下,分类器并不知道被拉到一起的样本是否真的来自同一个类。
因此,本文的半监督学习策略是:交替最小化和
+
。从而使两个视图生成器在保持标签相关信息的同时减少互信息。然而,由于我们只有一小部分标记数据来训练视图生成器,所以使用原始数据仍然是有益的,就像简单训练策略一样。具体细节在算法2中描述。

消融实验设计
针对两个视图生成器的消融
训练策略的消融
超参的消融
一句话总结
感觉框架不是很新,但是这个训练策略还是蛮新颖的,不过看了一遍下来,我给忘了分类器是分的什么类了?追加:分类器是半监督学习的时候用的,需要有标签的数据
论文好句摘抄(个人向)
(1)have shown impressive representational power in various domains
(2)Blessed by the invariance of image semantics under various transformation, image data augmentation has been widely used to generative contrastive views















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









