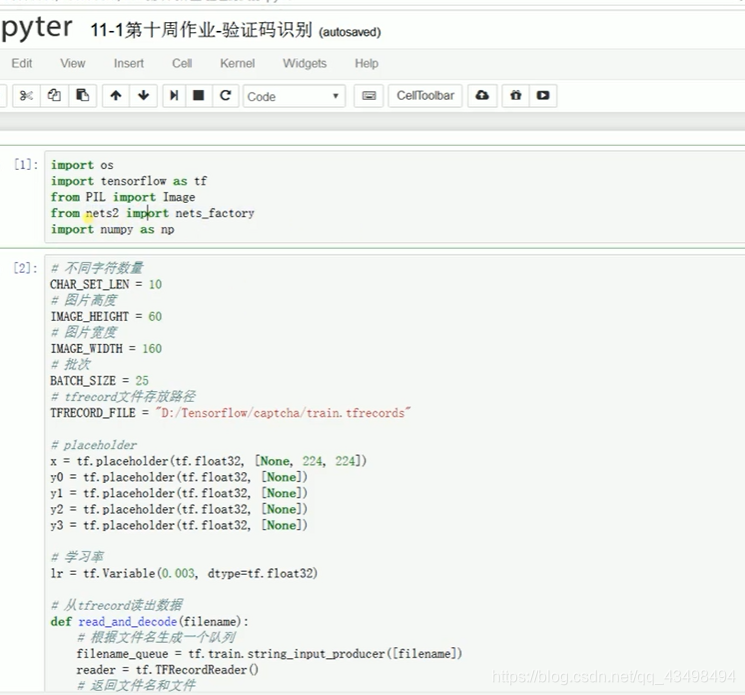
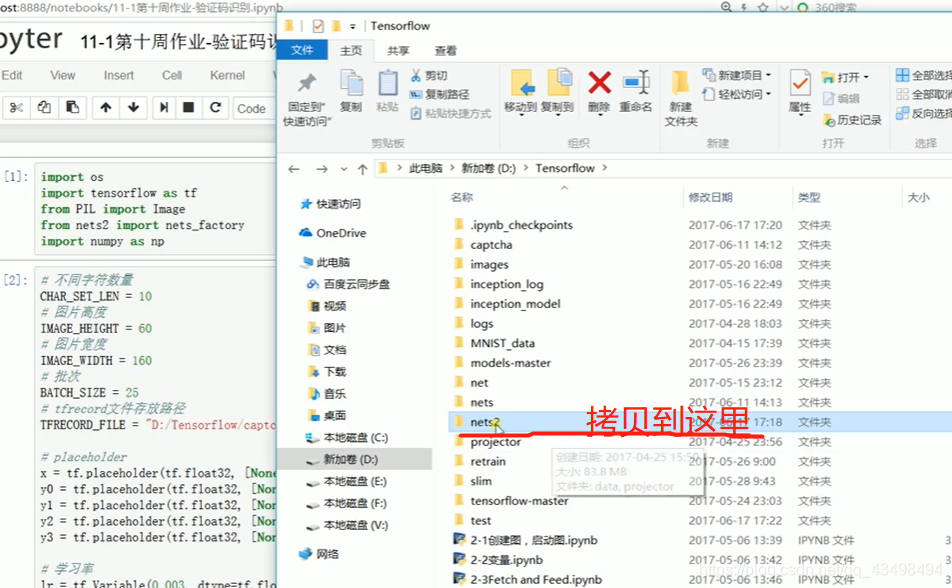
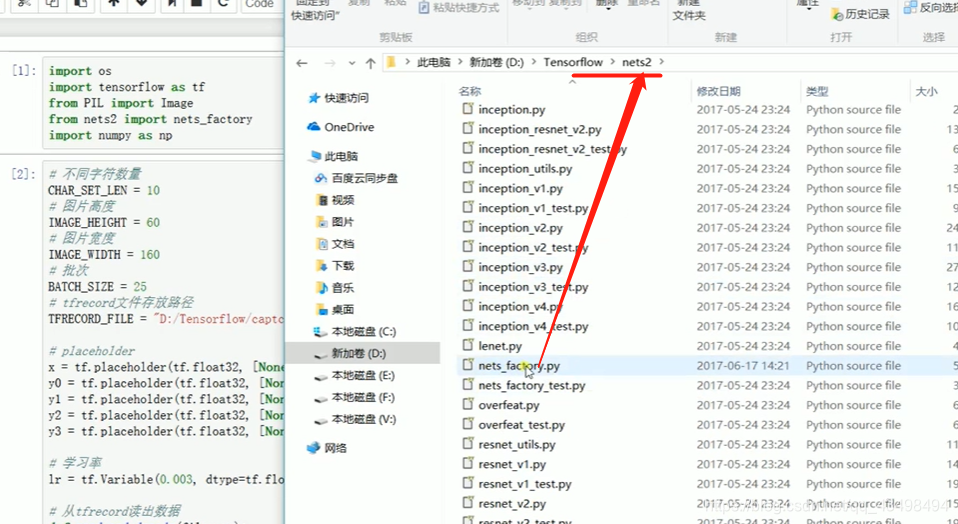
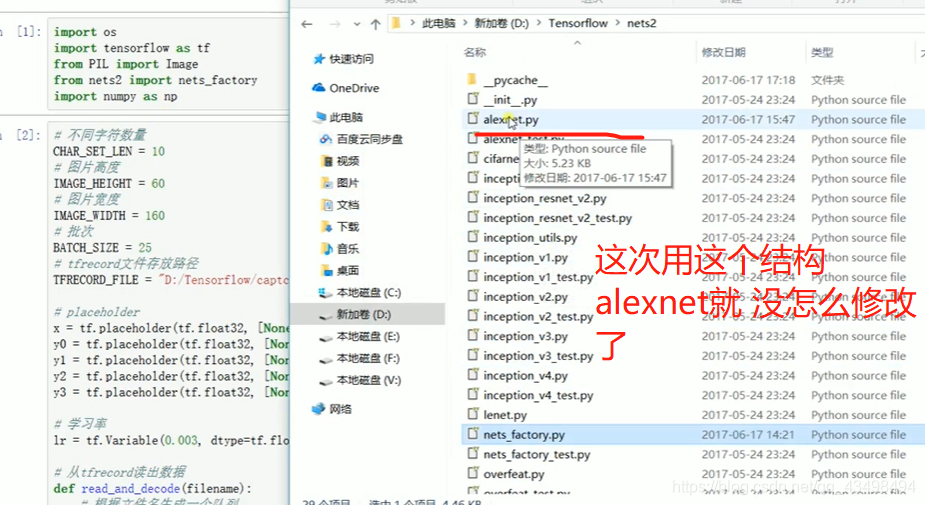
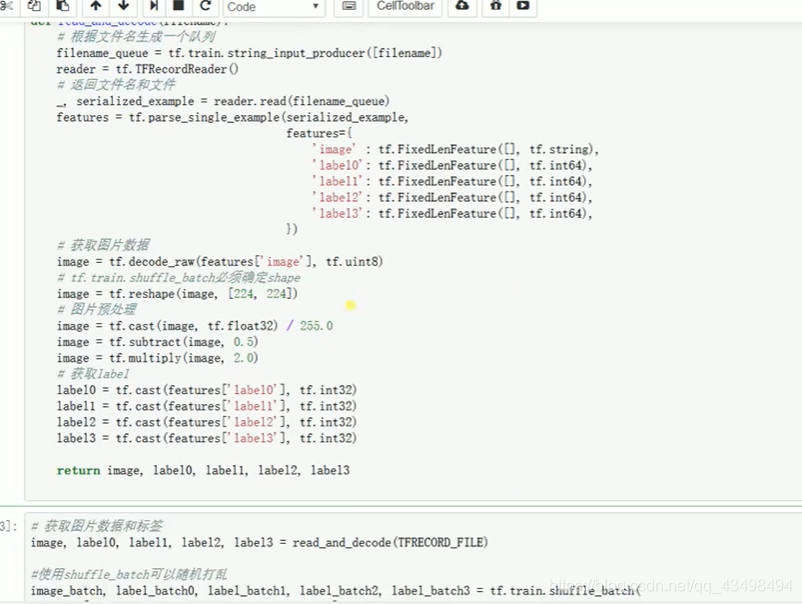
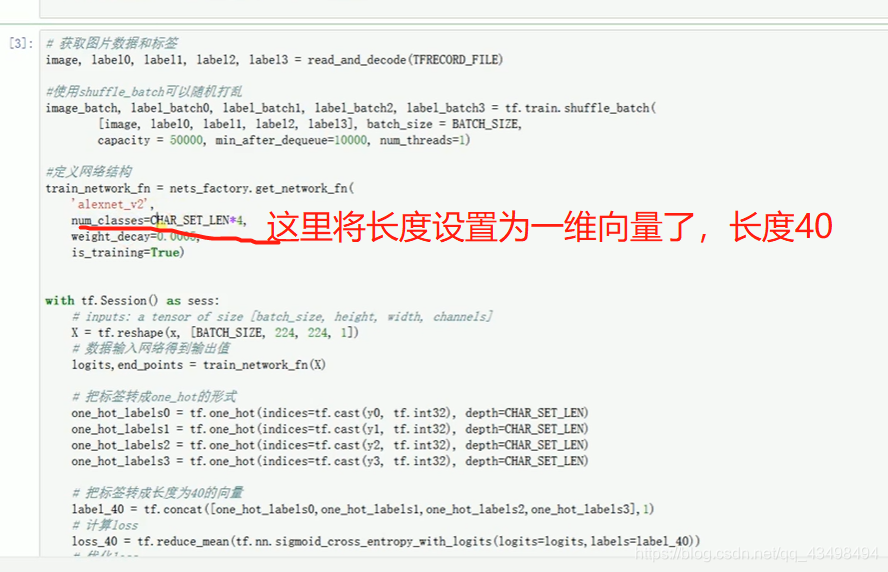
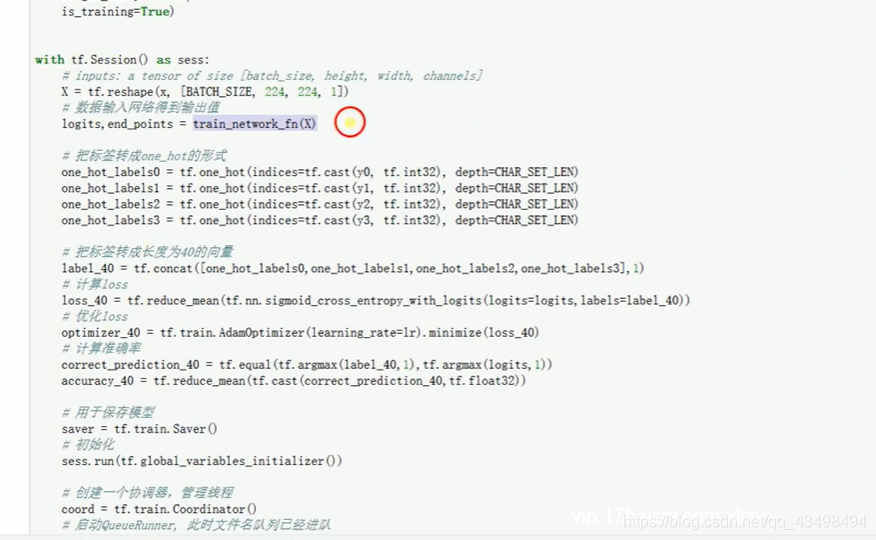
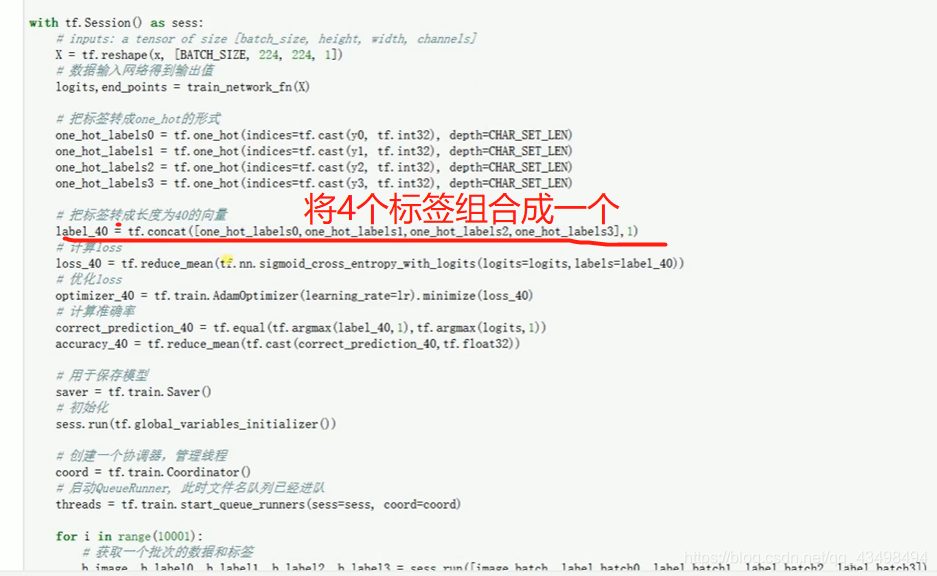
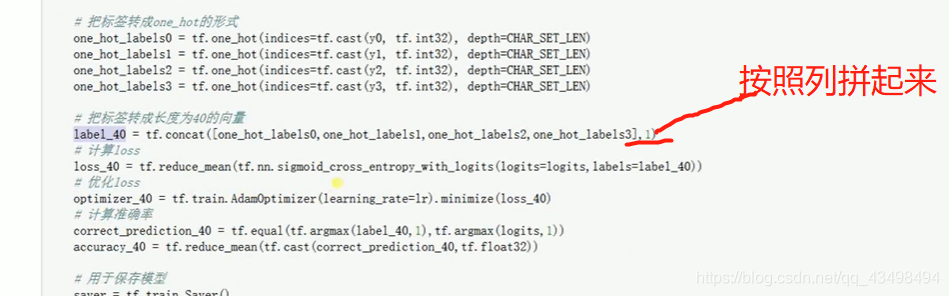
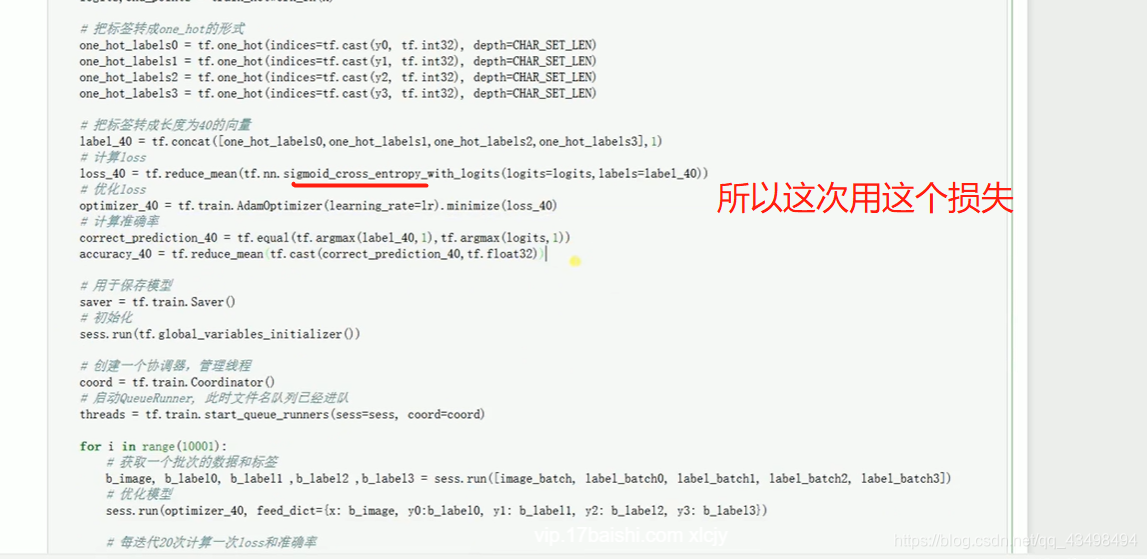
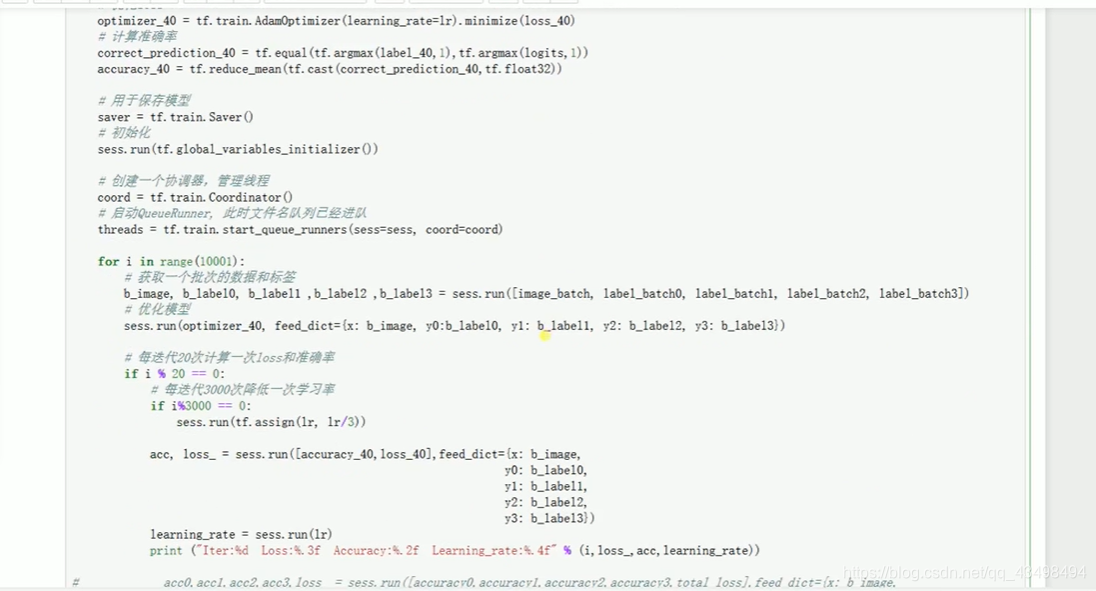
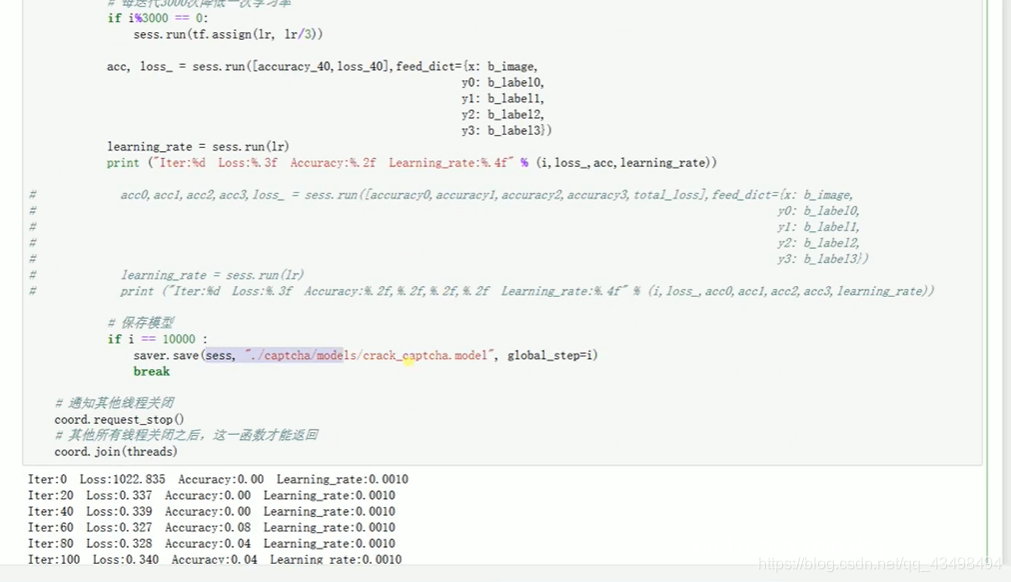
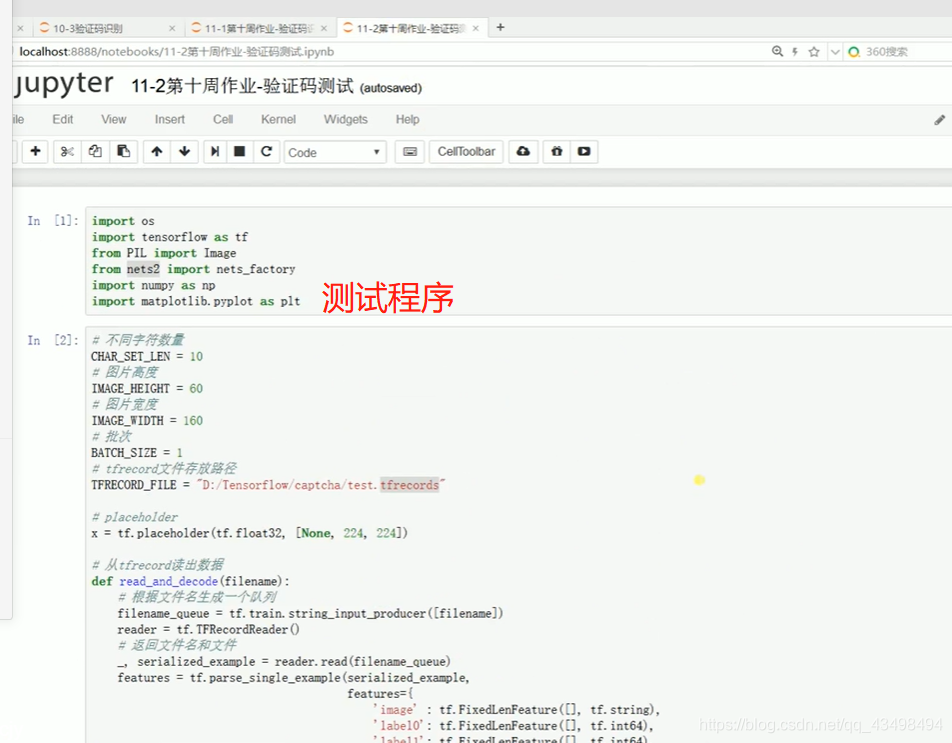
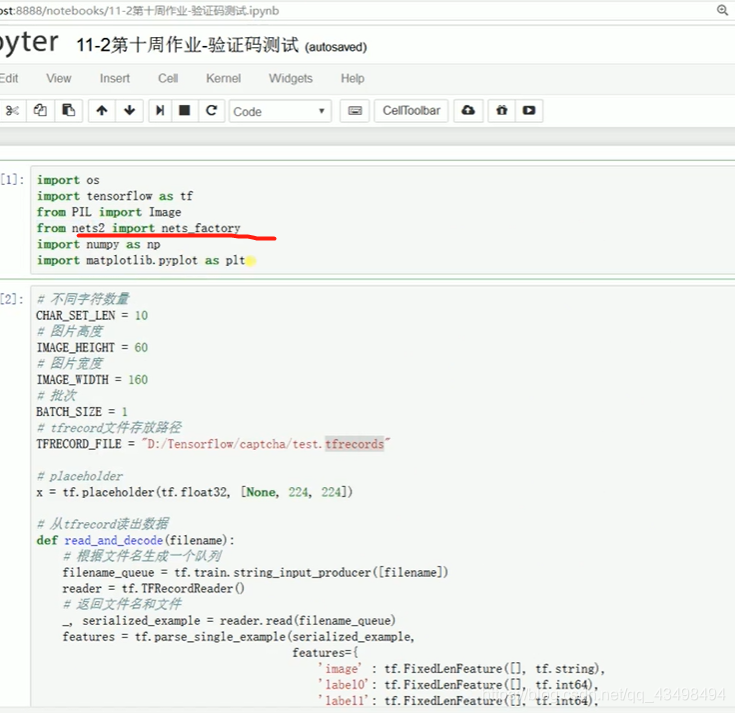
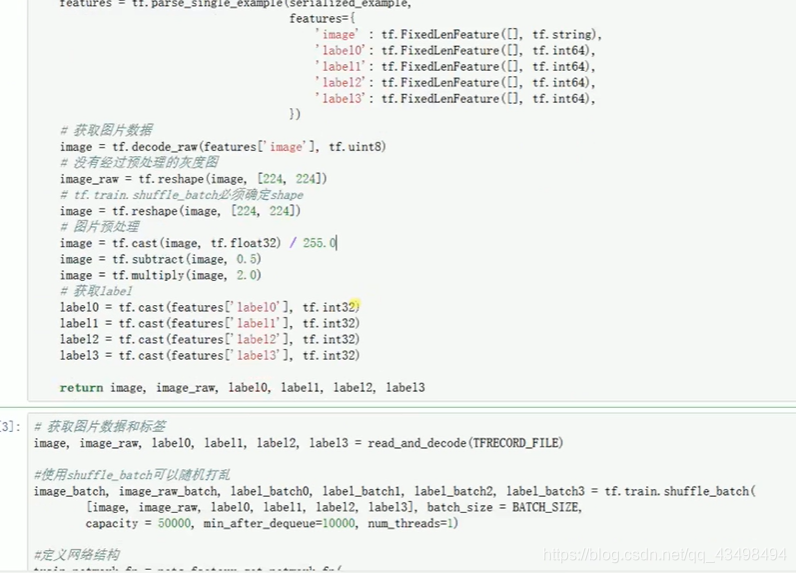
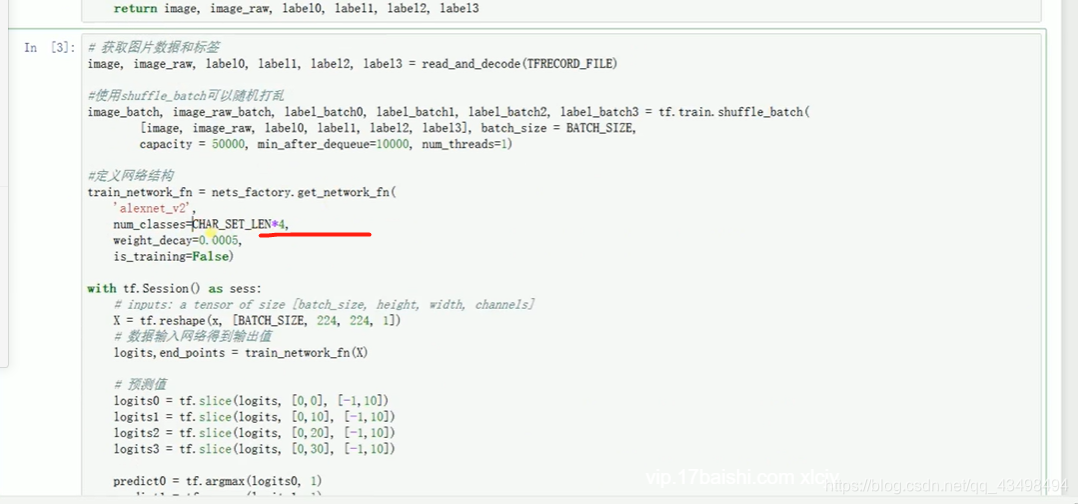
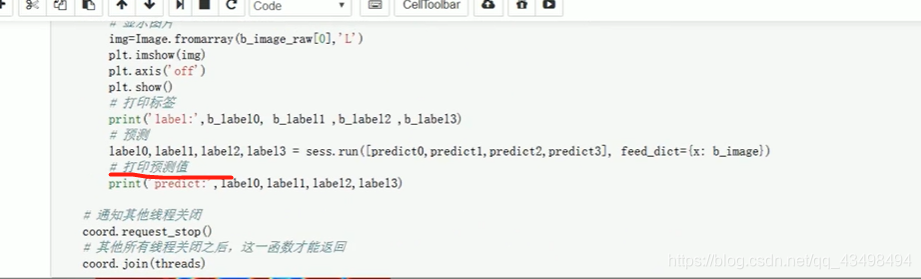
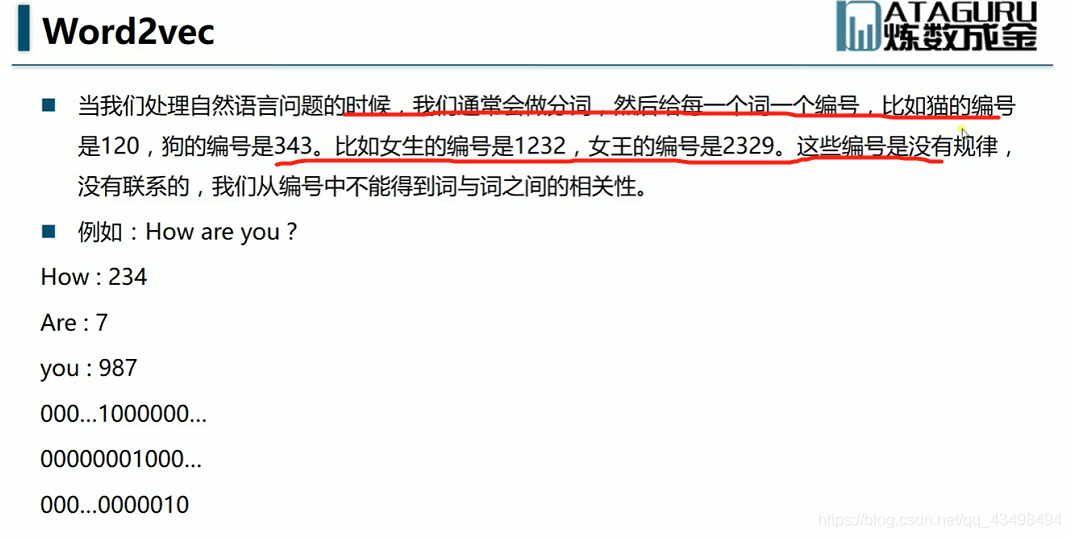
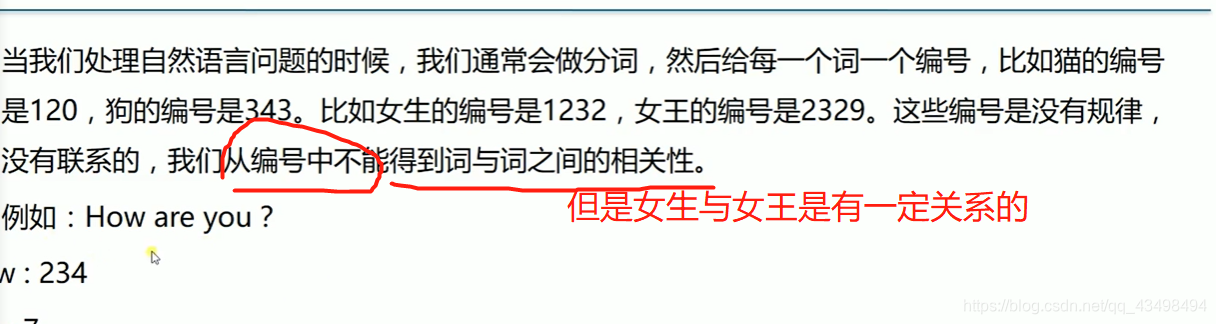
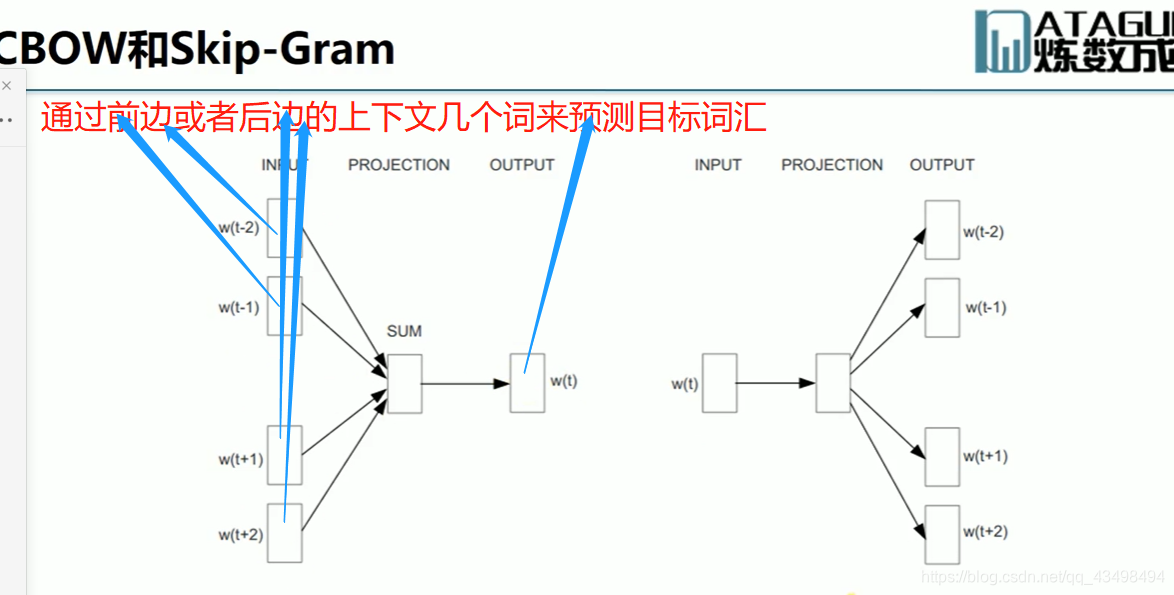
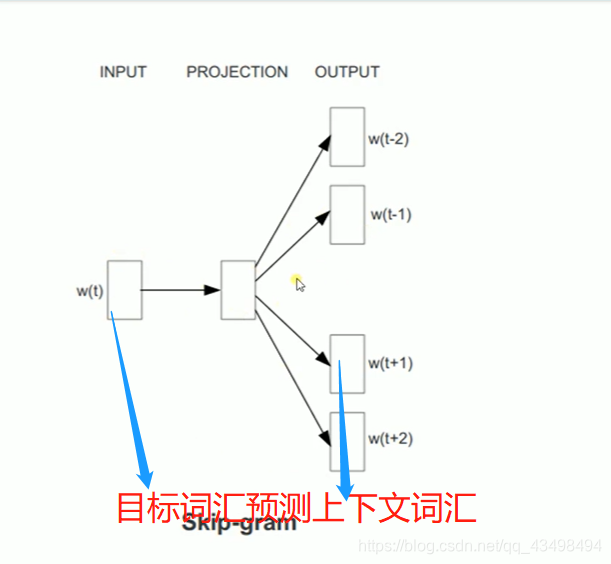
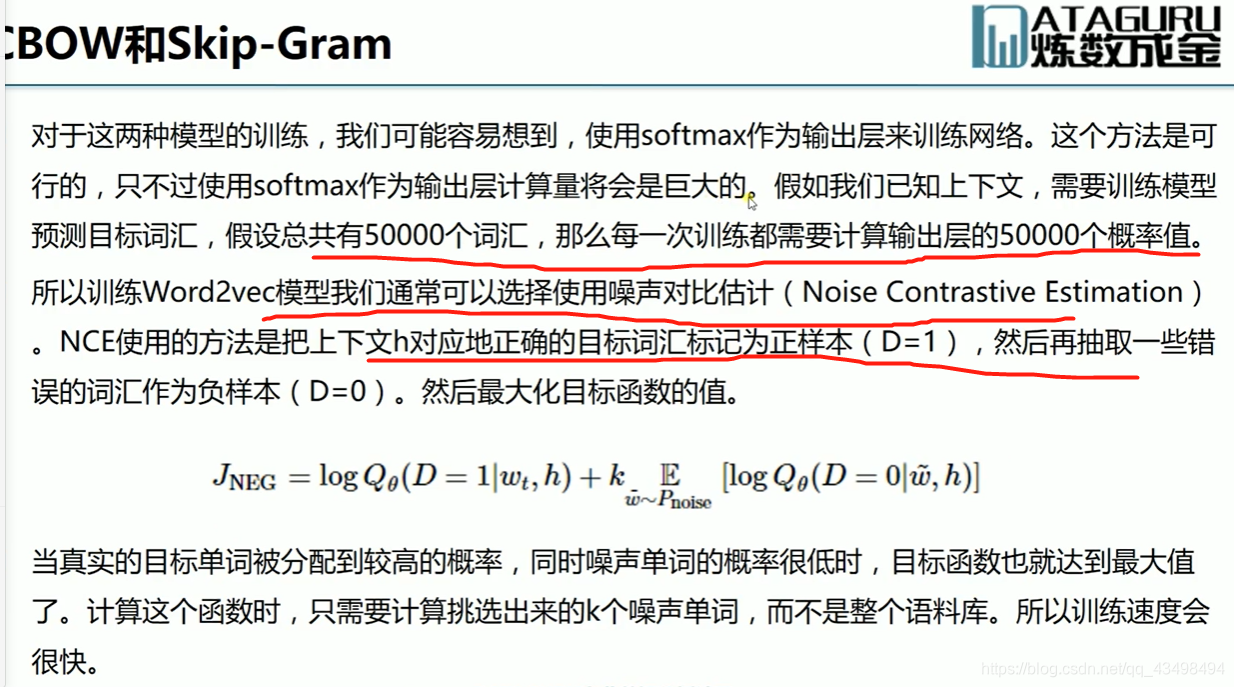
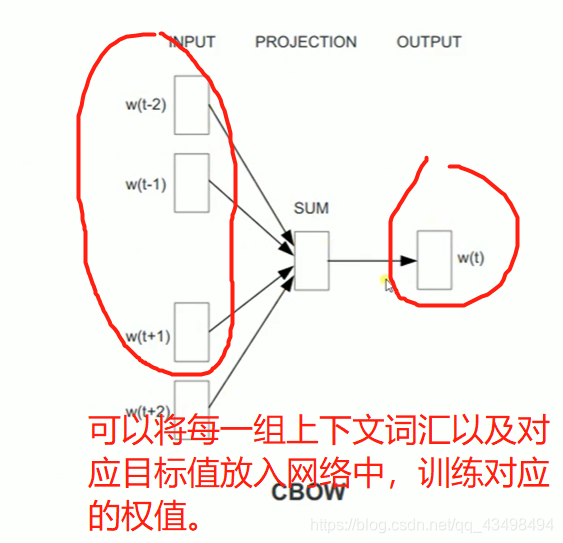
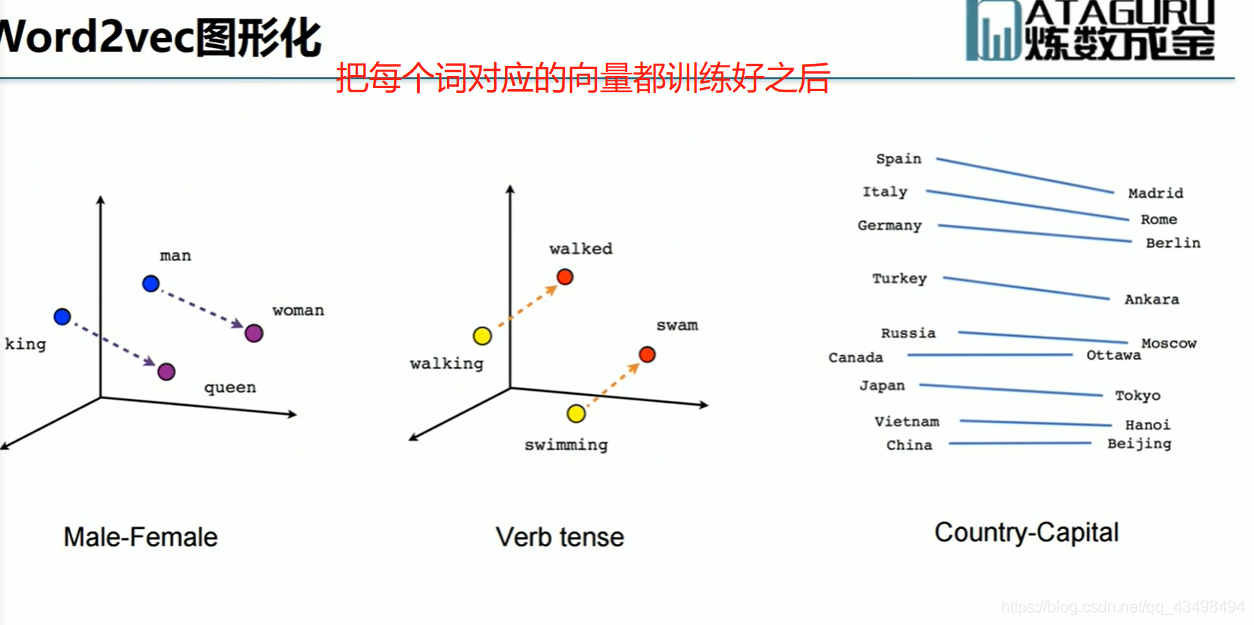
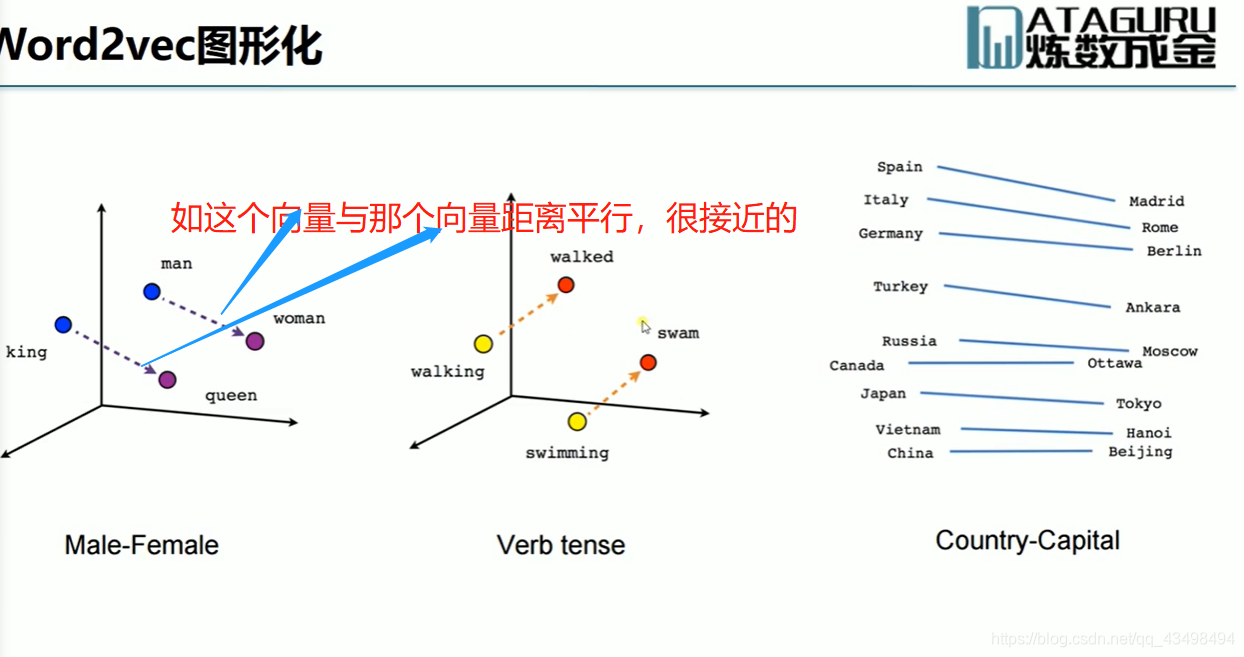
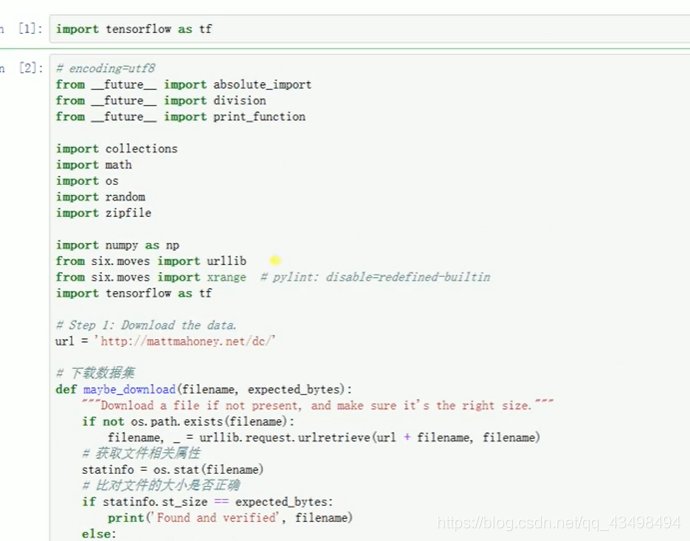
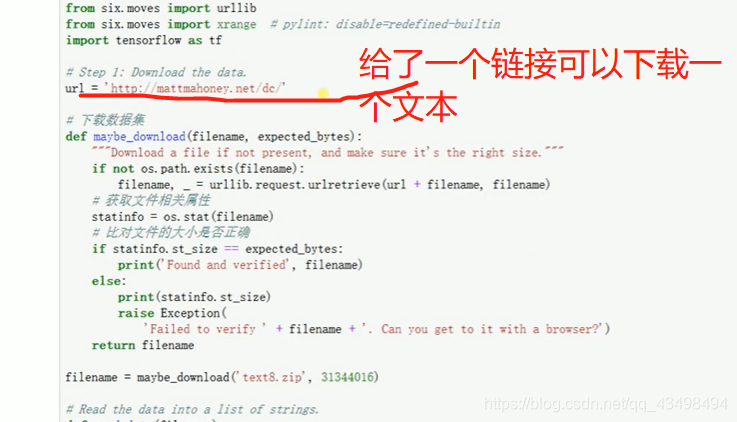
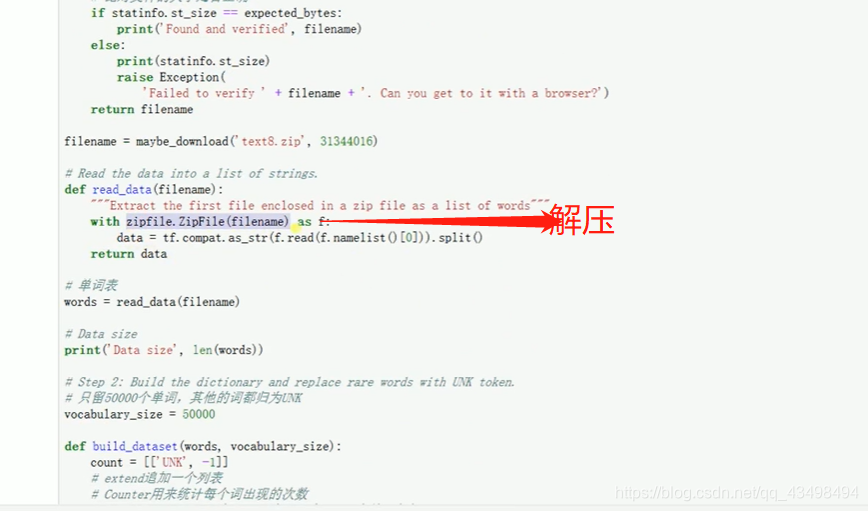
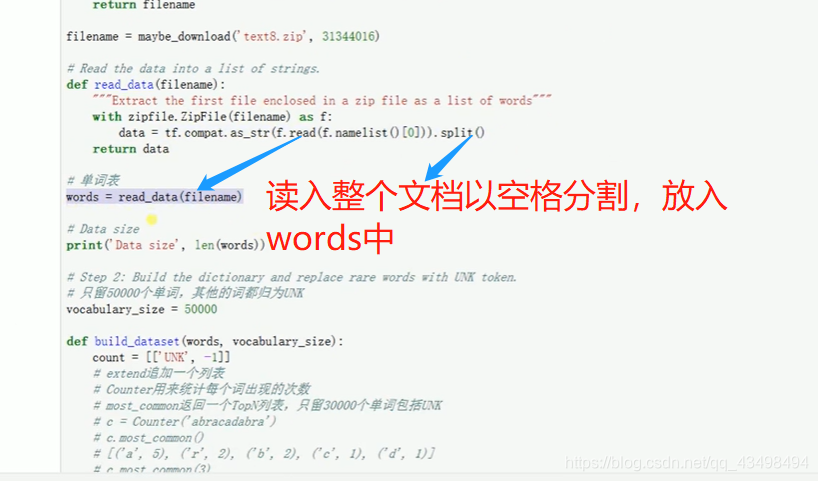
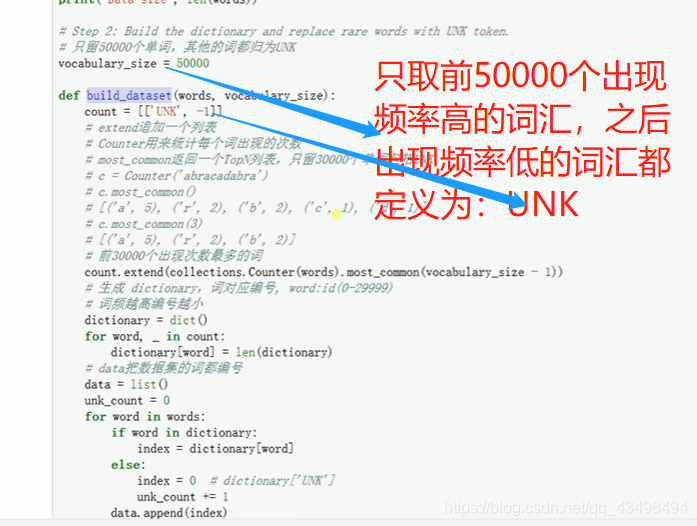
文章目录 上周验证码作业 程序 CNN在文本分类中的应用 使用word2vec训练好的权值矩阵来给CNN做初始化 语音基础 声音分类程序 上周验证码作业 最后一层没用softmax,但用sofymax损失,这个最后也可以达到比较好结果也可以达不到好的效果。 根据目标词汇可能预测上下文的一个或两个词,或多个词。 word2vec模型也是通过神经网络训练出来的,一般将词转化为向量,向量长度一般我们可以用128维度或者256维度,这个词转化为固定长度维度,之后权值就是通过神经网络训练的。 把每个词对应的向量训练好之后,都放入到一个空间中,可以发现词性相近的词会聚集到一起,即他们之间的位置比较近,距离比较近。 程序 用word2vec处理英文时候容易,默认就是空格分割,而处理中文时要先分词如J8分词等。之后处理就与英文一样了。


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 本文介绍了使用Tensorflow2进行深度学习的实践,包括上周的验证码作业,探讨了不使用softmax但利用softmax损失的效果。接着讲解了word2vec在CNN文本分类中的应用,以及如何用预训练的word2vec权重初始化CNN。进一步深入到语音基础,解释了MFCC特征提取的过程。最后,作者分享了一个声音分类程序的实现,并提醒在处理复杂任务时要注意效率和进度反馈。
本文介绍了使用Tensorflow2进行深度学习的实践,包括上周的验证码作业,探讨了不使用softmax但利用softmax损失的效果。接着讲解了word2vec在CNN文本分类中的应用,以及如何用预训练的word2vec权重初始化CNN。进一步深入到语音基础,解释了MFCC特征提取的过程。最后,作者分享了一个声音分类程序的实现,并提醒在处理复杂任务时要注意效率和进度反馈。

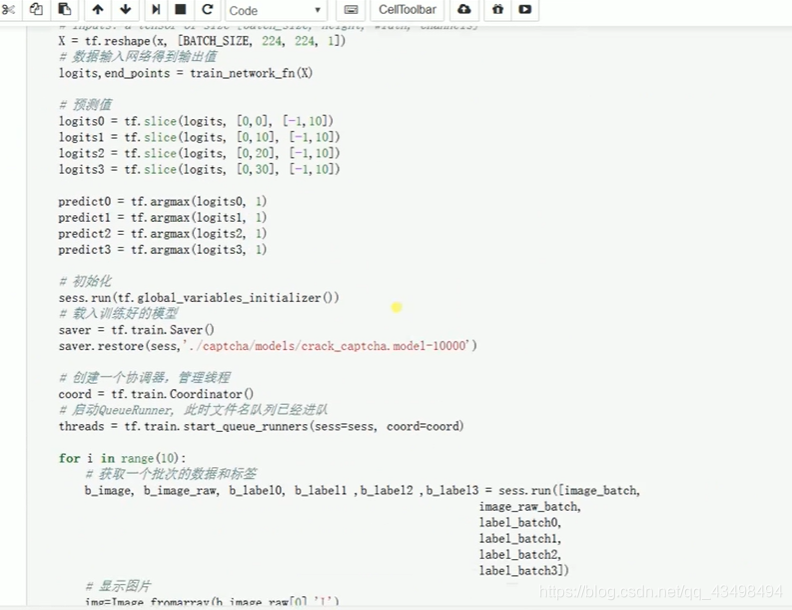
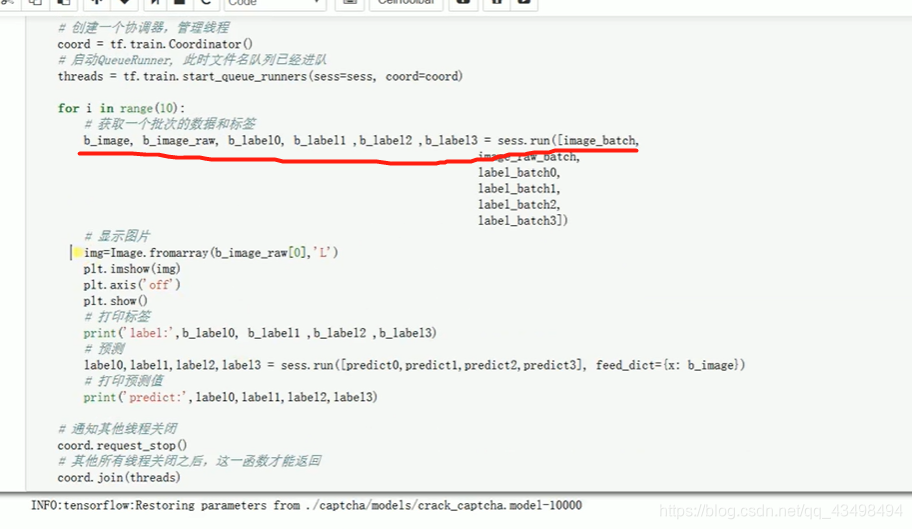
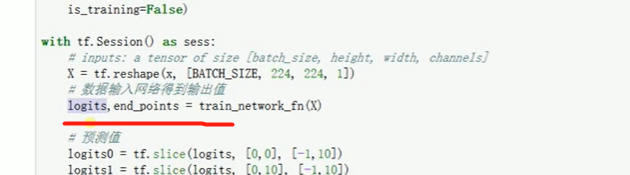
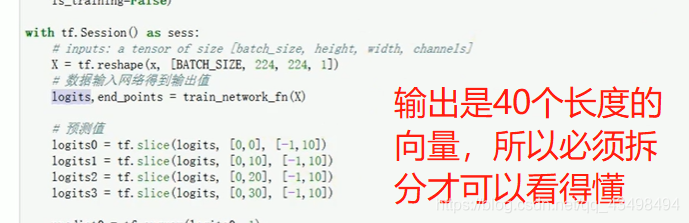






 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 797
797





