









本文为入门遥感图像分割的朋友提供一份详细教程,看完你将收获:
- 大致了解图像分割的基本流程
- 能够独立完成从拿到数据集到完成分割结果并评估的任务
有任何问题欢迎关注or私信,看到即回复,文末附代码链接。
文章目录
0.引言
本章大致介绍一下基本流程,如图所示:
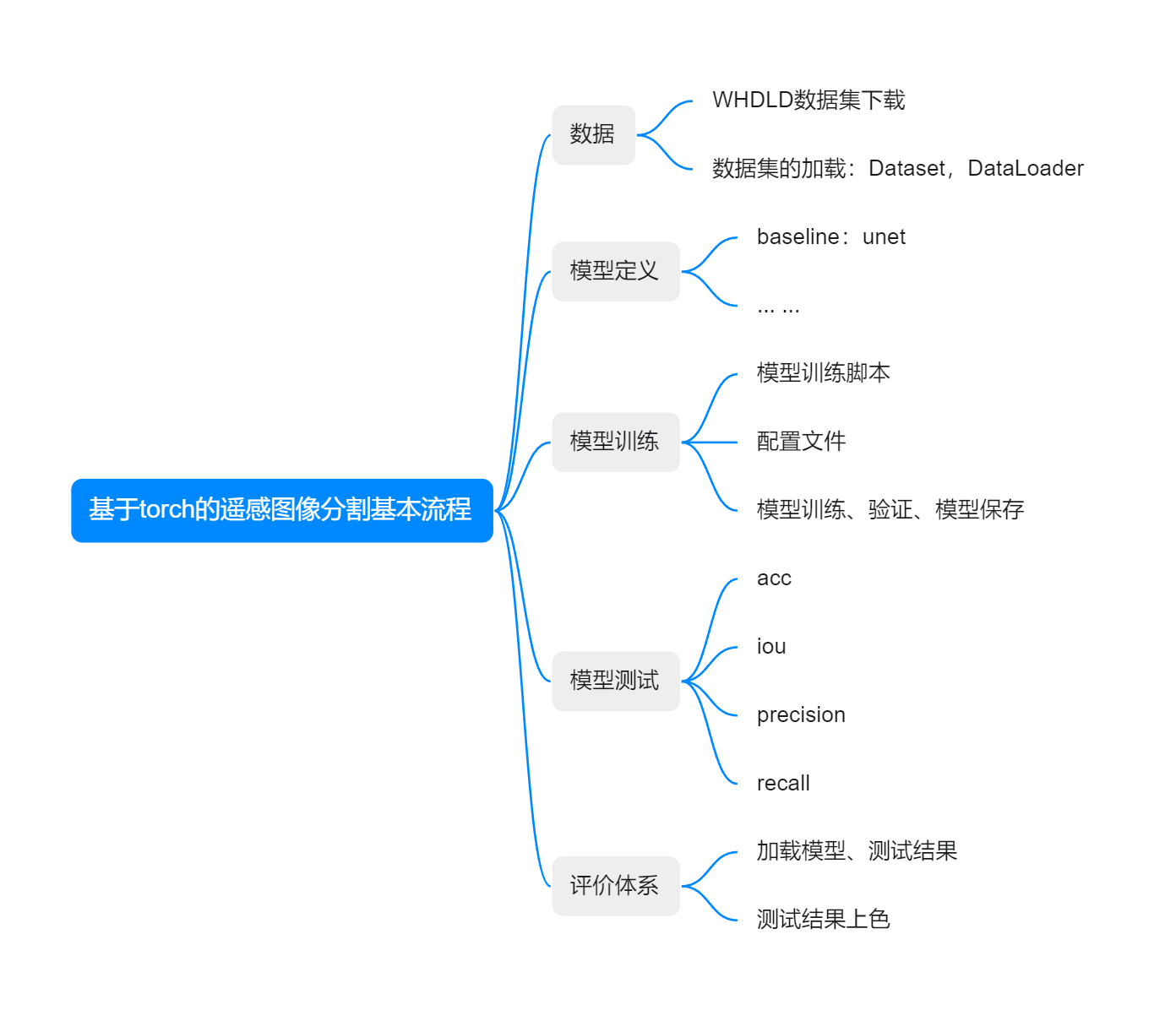
1.数据集准备
用深度学习来做遥感图像分类本质上还是在做监督分类,只是方法上换成了神经网络模型。因此为了训练图像分割模型,首先需要准备数据集,一般包括两部分:
- image:遥感图像,常规RGB是3通道,也可以是多光谱、高光谱、雷达等其他各种数据
- label:图像标签,即图像中每一个像素点代表所属类别(即分类体系)
本文呢以WHDLD数据集为例:
1.1 WHDLD数据集信息
链接: https://aistudio.baidu.com/datasetdetail/55589
影像信息: WHDLD数据集,由武汉大学于2018年发布
-
包含6种类型的遥感地物类型
- bare soil
- building
- pavement
- road
- vegetation
- water
-
图像shape:256 * 256 * 3
-
数据集数量:4940
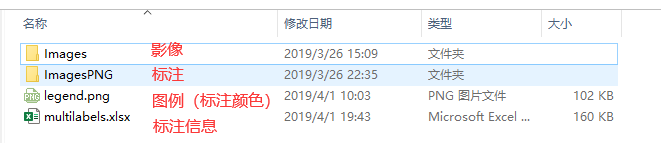
在dataset_config.yaml中定义类别的颜色和索引:
cls_dict:
bare_soil:
color: [128, 128, 128]
cls: 0
building:
color: [255, 0, 0]
cls: 1
pavement:
color: [192, 192, 0]
cls: 2
road:
color: [255, 255, 0]
cls: 3
vegetation:
color: [0, 255, 0]
cls: 4
water:
color: [0, 0, 255]
cls: 5
1.2 划分数据集
使用训练集训练模型参数,验证集用来验证模型精度,测试集一般指在实际使用过程中待分类的影像,本文单独划分出测试集来测试结果。
按照7:2:1划分数据集
- 输入:
- image_dir:影像目录
- label_dir:标签目录
- 输出:
- output_dir:目录下有train\val\test三个目录,各自存放了image、label
import os
import random
from shutil import copy2
from tqdm import tqdm
def split_dataset(image_dir, label_dir, output_dir, train_ratio=0.7, val_ratio=0.2, test_ratio=0.1, seed=42):
# 设置随机种子以保证结果可复现
random.seed(seed)
# 获取图像和标签文件列表
images = sorted(os.listdir(image_dir))
labels = sorted(os.listdir(label_dir))
# 打乱数据
data = list(zip(images, labels))
random.shuffle(data)
# 计算各个集的数量
total_count = len(data)
train_count = int(total_count * train_ratio)
val_count = int(total_count * val_ratio)
test_count = total_count - train_count - val_count
# 划分数据集
train_data = data[:train_count]
val_data = data[train_count:train_count + val_count]
test_data = data[train_count + val_count:]
# 创建输出目录
for split in ['train', 'val', 'test']:
os.makedirs(os.path.join(output_dir, split, 'images'), exist_ok=True)
os.makedirs(os.path.join(output_dir, split, 'labels'), exist_ok=True)
# 复制数据到相应的目录
def copy_files(data, split):
for image, label in data:
copy2(os.path.join(image_dir, image), os.path.join(output_dir, split, 'images', image))
copy2(os.path.join(label_dir, label), os.path.join(output_dir, split, 'labels', label))
copy_files(train_data, 'train')
copy_files(val_data, 'val')
copy_files(test_data, 'test')
print(f"Dataset split into train: {train_count}, val: {val_count}, test: {test_count}")
if __name__ == '__main__':
image_dir = 'E:\work\codes\RSegment\data\WHDLD\Images'
label_dir = 'E:\work\codes\RSegment\data\WHDLD\ImagesPNG'
save_dir = 'E:\work\codes\RSegment\data\WHDLD\outputs'
split_dataset(image_dir, label_dir, save_dir)
结果:

2.读取数据集
2.1 定义数据增强
数据增强是指通过一些图像变换的方式来“扩充”数据集,从而增强模型在训练时的泛化能力。一般使用基础的Resize、Normalize、ToTensorV2来处理图像。
数据增强前后:
- 输入:Array,shape=(256,256,3)
- 输出:Tensor,shape=(3,256,256)
本文用albumentations库定义数据增强策略,注意:
-
图像和标签的一致性: 增强操作如翻转、旋转、裁剪等必须同时应用于图像和标签,以保持它们之间的一致性。
-
标签的格式: 标签通常是一个单通道的图像,其中每个像素的值表示该像素所属的类别。因此,在使用
ToTensorV2时,标签会被转换为形状为(1, H, W)的 Tensor,以保持与 PyTorch 的输入格式一致。 -
数据类型: 在转换为 Tensor 时,
ToTensorV2会将图像转换为浮点类型,并将像素值归一化到[0, 1]之间。而标签通常保持为整型,以表示类别索引。
from albumentations.pytorch import ToTensorV2
from albumentations import *
transform = {
'train':Compose([
HorizontalFlip(p=0.5),
RandomBrightnessContrast(p=0.2),
GaussianBlur(p=0.1),
Resize(height=256, width=256, p=1.0),
Normalize(),
ToTensorV2()
]),
'val':Compose([
Resize(height=256, width=256),
Normalize(),
ToTensorV2()
]),
'test': Compose([
Resize(height=256, width=256),
Normalize(),
ToTensorV2()
])
}
2.2 读取Dataset
torch在读取数据集时,继承torch.utils.Dataset类,重写__init__(),__len__(),__getitem__()三个方法,并加载定义好的transform
- __init__():定义数据集路径、数据增强等
- __len__():数据集数量
- __getitem__():根据索引读取数据集
from torch.utils.data import Dataset, DataLoader
import os
import glob
from PIL import Image
from loguru import logger
from pathlib import Path
import numpy as np
from datasets.transform import transform
class WhdldDataset(Dataset):
"""
root是划分完数据集后的目录
"""
def __init__(
self,
root: str,
transforms=None,
mode = 'train',
image_suffix: str = '.jpg',
label_suffix: str = '.png',
):
self.images = glob.glob(os.path.join(root, mode, f'images/*{image_suffix}'))
self.labels = [
os.path.join(os.path.join(root, mode, 'labels'), Path(image).stem + label_suffix) for image in self.images
]
logger.info(f'load {len(self.images)} samples of {root}')
self.transforms = transforms
def __len__(self):
return len(self.labels)
def __getitem__(self, i):
image = np.array(Image.open(self.images[i]))
label = np.array(Image.open(self.labels[i])) - 1 # gt从0开始
res = {
'image': image,
'label': label
}
if self.transforms is not None:
res = self.transforms(image=image, mask=label)
res['label'] = res.pop('mask') # 标签字典改成label,方便统一
return res
if __name__ == '__main__':
root = r'E:\work\codes\RSegment\data\WHDLD\outputs'
dataset = WhdldDataset(root,transform, mode='train')
data = dataset.__getitem__(1)
print(data['image'].shape)
print(data['label'].shape)
测试结果:logger记录日志,同时查看image和label的shape和type正常

在此基础上定义Dataloader,方便模型训练。
Dataloader可以理解成给Dataset加上了Batchsize的遍历器,即原本是(3,256,256)的tensor经过Dataloader包装后,遍历过程中shape为(batchsize,3,256,256)
train_dataset = WhdldDataset(args.train_data_dir,transform=transform['train'])
val_dataset = WhdldDataset(args.val_data_dir,transform=transform['val'])
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.num_workers, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=args.batch_size, num_workers=args.num_workers, shuffle=False)
3.模型定义
本文以最常规的Unet为Baseline完成遥感图像分割流程,模型持续更新
所有的模型弄清楚输入输出,只是中间不同模型特征处理方式不同。输入是图片,输出是标签
- 输入:根据上文可知输入是(batchsize,3,256,256)
- 输出:各像素属于的类别标签(batch,1,256,256) #1一般略去
Unet模型见原文:https://arxiv.org/pdf/1505.04597
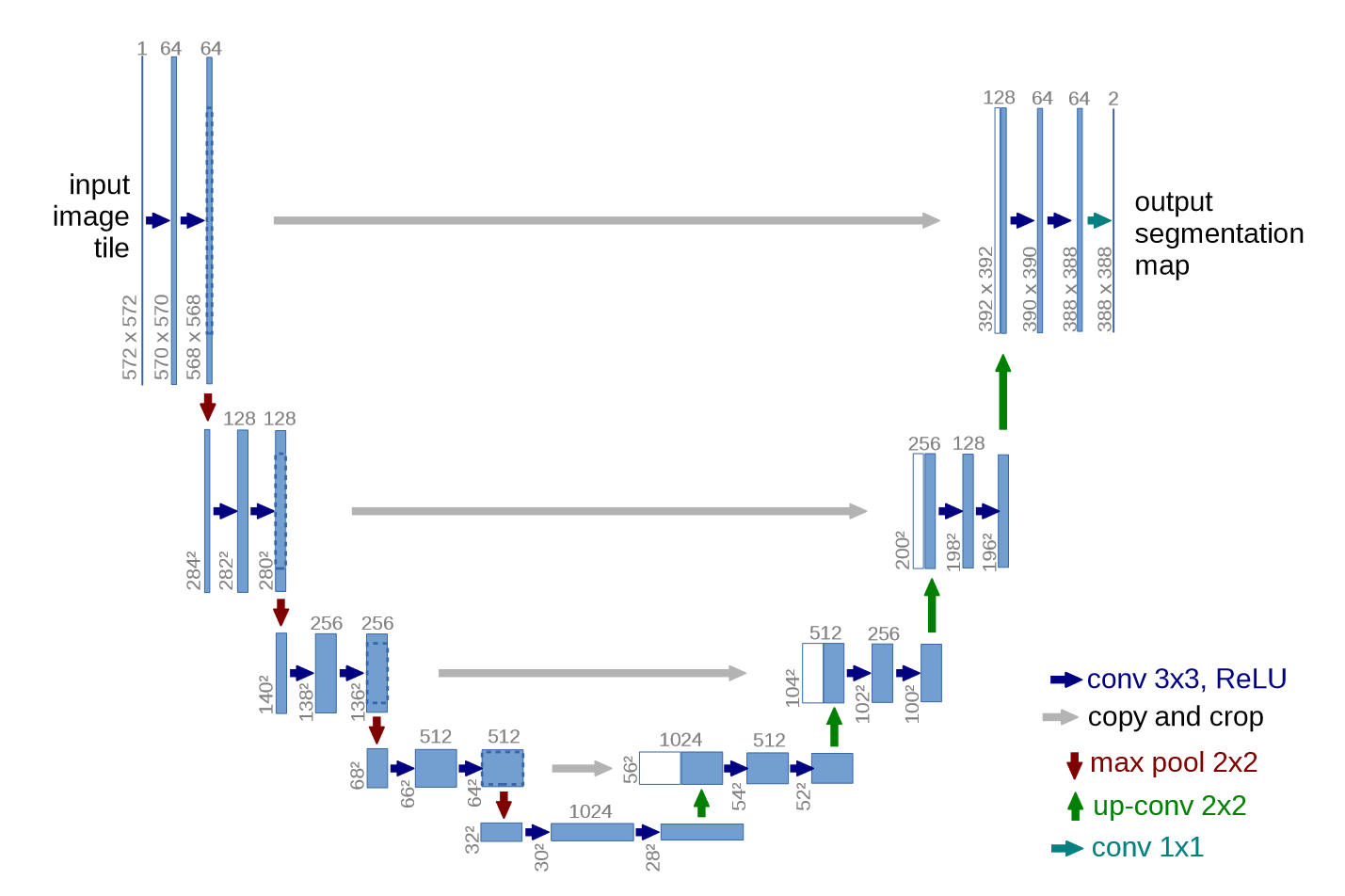
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(UNet, self).__init__()
# Encoder path (downsampling)
self.enc1 = self.conv_block(in_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# Bottleneck
self.bottleneck = self.conv_block(512, 1024)
# Decoder path (upsampling)
self.upconv4 = self.upconv_block(1024, 512)
self.dec4 = self.conv_block(1024, 512)
self.upconv3 = self.upconv_block(512, 256)
self.dec3 = self.conv_block(512, 256)
self.upconv2 = self.upconv_block(256, 128)
self.dec2 = self.conv_block(256, 128)
self.upconv1 = self.upconv_block(128, 64)
self.dec1 = self.conv_block(128, 64)
# Final convolution layer to get desired output channels
self.final_conv = nn.Conv2d(64, out_channels, kernel_size=1)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def upconv_block(self, in_channels, out_channels):
return nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(F.max_pool2d(enc1, 2))
enc3 = self.enc3(F.max_pool2d(enc2, 2))
enc4 = self.enc4(F.max_pool2d(enc3, 2))
# Bottleneck
bottleneck = self.bottleneck(F.max_pool2d(enc4, 2))
# Decoder
dec4 = self.upconv4(bottleneck)
dec4 = torch.cat((dec4, enc4), dim=1)
dec4 = self.dec4(dec4)
dec3 = self.upconv3(dec4)
dec3 = torch.cat((dec3, enc3), dim=1)
dec3 = self.dec3(dec3)
dec2 = self.upconv2(dec3)
dec2 = torch.cat((dec2, enc2), dim=1)
dec2 = self.dec2(dec2)
dec1 = self.upconv1(dec2)
dec1 = torch.cat((dec1, enc1), dim=1)
dec1 = self.dec1(dec1)
# Final output
return self.final_conv(dec1)
# Example usage
if __name__ == "__main__":
model = UNet(in_channels=3, out_channels=1) # For a single-channel output (e.g., binary segmentation)
print(model)
x = torch.randn((2, 3, 256, 256)) # Example input tensor (batch_size, channels, height, width)
output = model(x)
print(output.shape) # Should be (1, 1, 256, 256) for this example
运行结果:
UNet(
(enc1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(enc2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(enc3): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(enc4): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(bottleneck): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(upconv4): ConvTranspose2d(1024, 512, kernel_size=(2, 2), stride=(2, 2))
(dec4): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(upconv3): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2))
(dec3): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(upconv2): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2))
(dec2): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(upconv1): ConvTranspose2d(128, 64, kernel_size=(2, 2), stride=(2, 2))
(dec1): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(final_conv): Conv2d(64, 1, kernel_size=(1, 1), stride=(1, 1))
)
torch.Size([2, 1, 256, 256])
4.模型训练
4.1 模型训练脚本
编写Trainer类:包含6个部分:
- __init__:输入并定义dataloader、model、optimizer、loss function、lr scheduler
- init_settings:创建日志模型保存目录、初始化评价指标类
- train:模型训练
- evaluate:模型验证
- save_model:保存模型参数
- load_model:加载模型参数
模型训练详细流程如下:
1. 初始化 (init)
-
目标: 在创建
Trainer对象时,完成训练和验证过程的所有必要初始化工作。 -
参数初始化:
model: 传入待训练的深度学习模型,本文暂时使用unet。train_loader和val_loader: 分别是训练集和验证集的数据加载器,用于批量加载数据。criterion: 损失函数,用于计算模型预测输出与真实标签之间的误差。optimizer: 优化器,用于在训练过程中调整模型的参数,目标是最小化损失。scheduler: 学习率调度器,用于动态调整训练过程中的学习率,提升模型收敛效果。device: 指定使用的设备(CPU或GPU),用于加速计算。num_classes: 任务中的类别数,用于度量计算,比如混淆矩阵。resume: 模型恢复路径,用于从先前保存的检查点加载模型参数(如有需要)。output_dir: 输出目录,用于存储训练日志、模型检查点等。
-
调用初始化方法 (
init_settings):- 加载之前训练的模型(如有指定恢复路径)。
- 初始化输出目录,用于存储训练日志和模型文件。
- 设置日志记录系统,用于记录训练过程中的关键信息。
- 初始化度量工具(Metrics),用于评估模型在验证集上的表现。
2. 模型初始化设置 (init_settings)
- 加载模型: 如果指定了
resume路径,调用load_model方法,从该路径加载已保存的模型参数,并将模型名记录下来。 - 创建输出目录: 调用
os.makedirs创建一个包含当前时间戳的目录,用于保存模型检查点和日志文件。 - 设置日志系统: 调用
setup_logging配置日志系统,将日志输出到指定的目录中。 - 初始化度量工具: 创建
Metrics对象,用于在验证阶段评估模型表现(如准确率和交并比)。
3. 训练过程 (train)
- 目标: 通过指定的 epoch 数,逐步优化模型,保存最佳表现的模型。
- 训练循环: 对于每个 epoch:
- 设置模型为训练模式: 调用
self.model.train(),确保模型在训练过程中正确处理 dropout 和 batch normalization 等操作。 - 批次循环: 对每个数据批次:
- 加载数据: 从
train_loader中加载一个批次的图像和对应的标签,将其移动到指定设备上(如 GPU)。 - 清零梯度: 在每次反向传播之前,调用
self.optimizer.zero_grad()清除上一次计算的梯度,避免累积。 - 前向传播: 将输入图像通过模型,得到预测输出。
- 计算损失: 使用损失函数
criterion计算预测输出和真实标签之间的误差。 - 反向传播: 调用
loss.backward()计算损失对模型参数的梯度。 - 优化模型参数: 调用
self.optimizer.step()更新模型参数,最小化损失。 - 累积损失: 记录当前批次的损失值,以便后续计算平均训练损失。
- 加载数据: 从
- 调整学习率: 在每个 epoch 完成后,调用
self.scheduler.step()依据预设的策略调整学习率。 - 计算平均训练损失: 通过累积的损失计算该 epoch 的平均训练损失,并记录。
- 验证模型: 调用
evaluate方法,使用验证集评估模型的表现。 - 保存模型: 如果当前 epoch 的验证精度超过历史最佳精度,则保存该 epoch 的模型,并更新最佳精度记录。
- 设置模型为训练模式: 调用
4. 验证过程 (evaluate)
- 目标: 评估模型在验证集上的性能,以确保模型不仅在训练集上表现良好,也能泛化到未见过的数据。
- 设置模型为验证模式: 调用
self.model.eval(),确保在验证过程中不执行 dropout 和 batch normalization 的更新。 - 评估循环: 对验证集中的每个数据批次:
- 加载数据: 从
val_loader中加载一个批次的图像和对应的标签,将其移动到指定设备上(如 GPU)。 - 前向传播: 将输入图像通过模型,得到预测输出。
- 计算预测: 使用
torch.max获取每个像素/样本的预测类别。 - 更新度量工具: 调用
self.metrics.sample_add(labels, preds)将当前批次的预测结果与真实标签传递给度量工具,更新混淆矩阵或其他度量信息。 - 计算损失: 使用损失函数
criterion计算预测输出和真实标签之间的误差,并累积损失值。
- 加载数据: 从
- 计算平均验证损失: 通过累积的损失计算验证集的平均损失,并记录。
- 计算并记录评估指标: 调用
self.metrics.compute()计算如准确率、交并比等关键指标,并将其记录到日志中。 - 返回评估结果: 返回包含所有评估指标的字典,便于进一步处理。
5. 模型保存 (save_model)
- 目标: 在验证集上取得最佳表现时,将当前的模型参数保存为一个检查点文件。
- 移除旧模型文件: 如果当前已经存在一个模型文件,会先删除旧的模型文件。
- 保存新模型: 调用
torch.save(self.model.state_dict(), model_path)将当前模型的参数保存到指定路径,并更新记录的模型文件名。 - 记录模型保存: 记录模型保存的路径和文件名,便于后续恢复或推理使用。
6. 模型加载 (load_model)
- 目标: 从指定的检查点文件加载模型参数,用于恢复训练或进行推理。
- 加载模型参数: 调用
torch.load(checkpoint)从检查点文件中加载模型的状态字典,并将其加载到当前模型中。 - 设置设备: 将加载后的模型移动到指定的设备上(如 GPU),以便进行后续的训练或验证。
- 记录模型加载: 记录模型加载的路径,便于追踪和调试。
具体代码如下:
class Trainer:
def __init__(self,
model,
num_classes,
train_loader,
val_loader,
criterion,
optimizer,
scheduler,
device,
resume,
output_dir):
self.model = model
self.train_loader = train_loader
self.val_loader = val_loader
self.criterion = criterion
self.optimizer = optimizer
self.scheduler = scheduler
self.device = device
self.num_classes = num_classes
self.resume = resume
self.model_name = ""
self.save_dir = os.path.join(output_dir, datetime.now().strftime("%Y%m%d_%H%M%S"))
self.init_settings()
# 如果指定了恢复路径,则加载模型
def init_settings(self):
if self.resume:
self.load_model(self.resume)
self.model_name = os.path.basename(self.resume)
logger.info('init output dirs ... ')
os.makedirs(self.save_dir, exist_ok=True)
logger.info('init loggings ... ')
setup_logging(self.save_dir)
logger.info('init Metrics ... ')
self.metrics = Metrics(self.num_classes, self.device)
def train(self, epochs):
best_val_acc = 0.0
for epoch in range(epochs):
logger.info(f"Epoch {epoch + 1}/{epochs}")
self.model.train()
train_loss = 0.0
for i, data in enumerate(self.train_loader):
images = data['image']
labels = data['label']
images, labels = images.to(self.device), labels.to(self.device).long()
self.optimizer.zero_grad()
outputs = self.model(images)
loss = self.criterion(outputs, labels)
loss.backward()
self.optimizer.step()
train_loss += loss.item()
logger.info(f"[{epoch + 1}/{epochs}][{i}/{len(self.train_loader)}] Loss: {loss.item():.4f}")
self.scheduler.step()
train_loss /= len(self.train_loader)
logger.info(f"Train Loss: {train_loss:.4f}")
evaluate_results = self.evaluate()
val_acc = evaluate_results['total_acc']
val_miou = evaluate_results['total_iou']
if val_acc > best_val_acc:
best_val_acc = val_acc
self.save_model(f"epoch_{epoch + 1}_acc_{val_acc:.4f}_miou_{val_miou:.4f}.pth")
def evaluate(self):
self.model.eval()
self.metrics.update()
val_loss = 0.0
with torch.no_grad():
logger.info("start evaluating ...")
for data in tqdm(self.val_loader):
images = data['image']
labels = data['label']
images, labels = images.to(self.device), labels.to(self.device).long()
outputs = self.model(images)
_, preds = torch.max(outputs, dim=1)
# 更新混淆矩阵
self.metrics.sample_add(labels, preds)
loss = self.criterion(outputs, labels)
val_loss += loss.item()
val_loss /= len(self.val_loader.dataset)
logger.info(f"Validation Loss: {val_loss:.4f}")
# 计算并记录指标
results = self.metrics.compute()
logger.info("Validation Metrics:")
for key, value in results.items():
logger.info(f"{key}: {value}")
return results
def save_model(self, filename):
if os.path.exists(os.path.join(self.save_dir, self.model_name)):
os.remove(os.path.join(self.save_dir, self.model_name))
model_path = os.path.join(self.save_dir, filename)
torch.save(self.model.state_dict(), model_path)
self.model_name = filename
logger.info(f"Model saved to {model_path}")
def load_model(self, checkpoint):
self.model.load_state_dict(torch.load(checkpoint))
self.model.to(self.device)
logger.info(f"Model loaded from {checkpoint}")
4.2 编写配置文件
在config_model.yaml中定义相关配置
training:
epochs: 100
batch_size: 4
learning_rate: 0.001
optimizer: "adam" # 选择优化器:adam 或 sgd
loss_function: "cross_entropy" # 损失函数:cross_entropy 或 mse
scheduler:
type: "step_lr" # 学习率调度器类型: step_lr
step_size: 10 # 每隔多少个 epoch 调整一次学习率
gamma: 0.1 # 学习率调整的倍率
resume: './outputs/20240831_202015/best_model_acc_0.8348_miou_0.7164.pth'
device: "cuda" # 设备:cuda 或 cpu
dataset:
train_path: "./data/WHDLD/outputs/train"
val_path: "./data/WHDLD/outputs/val"
in_channels: 3
num_classes: 6
num_workers: 4
model:
name: "unet" # 模型名称:unet 或其他
save:
output_dir: "outputs"
4.3 根据配置文件编写配置代码
同样是编写TrainConfig类,根据yaml配置文件定义配置
通过get_train_config()函数获取实例化的train_config.
import yaml
import torch
import torch.optim as optim
import torch.nn as nn
from models.unet import UNet
class TrainConfig:
def __init__(self, yaml_file):
self.config = self.load_config(yaml_file)
self.device = self.config['training']['device']
self.model = None
self.transform = None
self.optimizer = None
self.loss_function = None
self.scheduler = None
self.train_loader = None
self.val_loader = None
self.setup()
def load_config(self, yaml_file):
with open(yaml_file, 'r', encoding='utf-8') as file:
config = yaml.safe_load(file)
return config
def setup(self):
self.train_loader = self.create_data_loader(mode='train')
self.val_loader = self.create_data_loader(mode='val')
self.create_model()
self.create_optimizer()
self.create_loss_function()
self.create_scheduler()
def summary(self):
return {
'train_data': self.train_loader,
'val_data': self.val_loader,
'model': self.model,
'optimizer': self.optimizer,
'loss': self.loss_function,
'scheduler': self.scheduler
}
def create_data_loader(self, mode='train'):
shuffle = True if mode == 'train' else False
dataset = WhdldDataset(self.config['dataset']['train_path'], transform=transform['train'])
data_loader = DataLoader(dataset, batch_size=self.config['training']['batch_size'],
num_workers=self.config['dataset']['num_workers'], shuffle=shuffle)
return data_loader
def create_model(self):
model_config = self.config
name = model_config['model']['name']
num_classes = model_config['dataset']['num_classes']
input_channels = model_config['dataset']['in_channels']
if name == "unet":
self.model = UNet(in_channels=input_channels, out_channels=num_classes).to(self.device)
else:
raise ValueError(f"Unknown model name: {name}")
return self.model
def create_optimizer(self):
training_config = self.config['training']
optimizer_name = training_config['optimizer']
learning_rate = training_config['learning_rate']
if optimizer_name == "adam":
self.optimizer = optim.Adam(self.model.parameters(), lr=learning_rate)
elif optimizer_name == "sgd":
self.optimizer = optim.SGD(self.model.parameters(), lr=learning_rate, momentum=0.9)
else:
raise ValueError(f"Unknown optimizer: {optimizer_name}")
def create_loss_function(self):
loss_function_name = self.config['training']['loss_function']
if loss_function_name == "cross_entropy":
self.loss_function = nn.CrossEntropyLoss()
elif loss_function_name == "mse":
self.loss_function = nn.MSELoss()
else:
raise ValueError(f"Unknown loss function: {loss_function_name}")
def create_scheduler(self):
scheduler_config = self.config['training']['scheduler']
scheduler_type = scheduler_config.get("type")
if scheduler_type == "step_lr":
self.scheduler = optim.lr_scheduler.StepLR(
self.optimizer,
step_size=scheduler_config["step_size"],
gamma=scheduler_config["gamma"]
)
else:
raise ValueError(f"Unknown scheduler: {scheduler_type}")
def get_train_config(config_file = 'config_model.yaml'):
return TrainConfig(config_file)
4.4 模型训练
编写main函数,根据yaml路径进行模型训练:
def main(config_file):
train_config = TrainConfig(config_file)
config = train_config.config
# 初始化模型、损失函数、优化器
device = train_config.device
train_loader = train_config.train_loader
val_loader = train_config.val_loader
model = train_config.model
criterion = train_config.loss_function
optimizer = train_config.optimizer
scheduler = train_config.scheduler
# 创建 Trainer 实例
trainer = Trainer(model,
config['dataset']['num_classes'],
train_loader,
val_loader,
criterion,
optimizer,
scheduler,
device,
config['training']['resume'],
config['save']['output_dir'])
# 开始训练
trainer.train(config['training']['epochs'])
控制台输出如下:
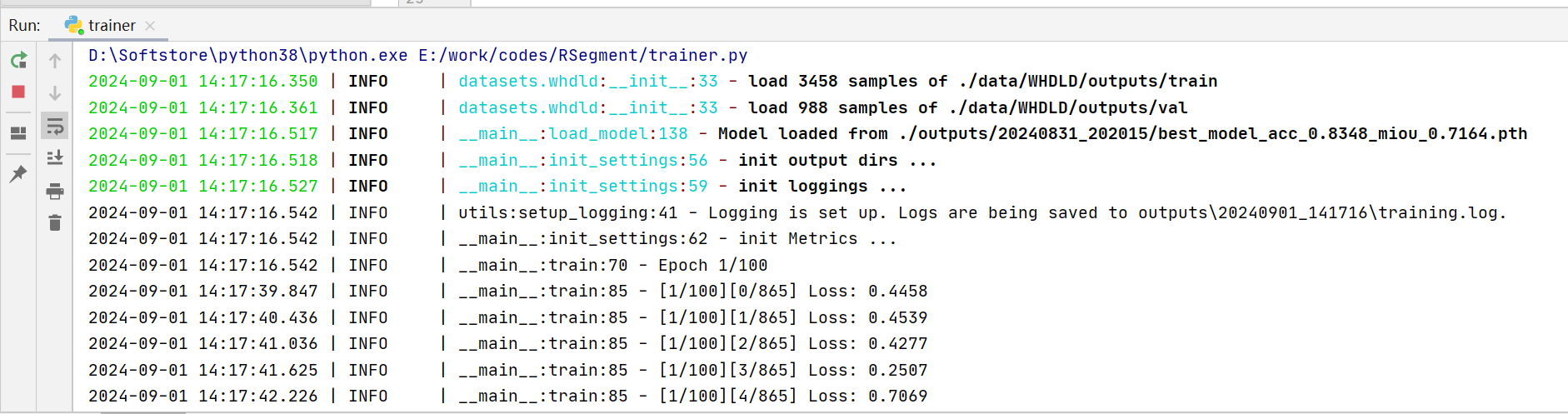
5.评价指标
编写Metrics类实现图像分割评价指标,大致逻辑如下:
初始化 Metrics 类:
Metrics类用于计算多分类任务的各种评估指标。- 初始化时,传入类的数量
class_num和设备device。 cfm_init方法初始化一个形状为(class_num, class_num)的全零混淆矩阵cfm,用于存储分类结果。
sample_add 方法:
- 方法用于将每次的真实标签
true_vector和预测标签pre_vector添加到混淆矩阵中。 - 首先将标签展平成一维向量
- 然后通过掩码筛选出有效的标签(标签值在 0 到
class_num之间) - 最后通过
torch.bincount计算并更新混淆矩阵。
acc 方法:
- 计算准确率(Accuracy)。包括每个类别的准确率
per_class_acc,以及总体准确率total_acc - 每个类别的准确率是该类别的正确预测数量除以该类别的真实样本总数
- 总体准确率是所有正确预测的样本数量除以所有样本总数。
iou 方法:
- 计算交并比(IoU)。包括每个类别的 IoU(
per_class_iou),以及总体 IoU(total_iou)。 - IoU 是正确预测的数量除以该类别的真实样本和预测样本的总和减去正确预测的数量。
precision 方法:
- 计算精确率(Precision)。包括每个类别的精确率(
per_class_precision)和总体精确率(total_precision)。 - 精确率是该类别的正确预测数量除以预测为该类别的样本总数。
recall 方法:
- 计算召回率(Recall)。包括每个类别的召回率(
per_class_recall)和总体召回率(total_recall)。 - 召回率是该类别的正确预测数量除以真实为该类别的样本总数。
compute 方法:
- 该方法汇总所有的评估指标,返回一个包含准确率、IoU、精确率和召回率的字典。
- 每个指标包括每个类别的值和总体值。
示例代码:
- 在
main部分,创建Metrics对象,并添加样本的真实标签和预测标签到混淆矩阵中,最后调用compute方法计算评估指标并输出结果。 - 每一个epoch计算完后调用
update清除已添加的样本。
代码如下:
import torch
class Metrics:
def __init__(self, class_num, device = 'cpu'):
self.class_num = class_num
self.device = device
self.cfm = self.cfm_init(self.class_num)
def cfm_init(self, class_num):
return torch.zeros(size=(class_num, class_num), dtype=torch.int).to(self.device)
def update(self):
self.cfm = self.cfm_init(self.class_num)
def sample_add(self, true_vector, pre_vector):
true_vector = true_vector.flatten()
pre_vector = pre_vector.flatten()
mask = (true_vector >= 0) & (true_vector < self.class_num)
self.cfm += torch.bincount(self.class_num * true_vector[mask] + pre_vector[mask],
minlength=self.class_num ** 2).reshape(self.class_num, self.class_num).to(self.device)
def acc(self):
per_class_acc = torch.diag(self.cfm).float() / torch.sum(self.cfm, dim=1).float()
total_acc = torch.diag(self.cfm).sum().float() / self.cfm.sum().float()
return per_class_acc, total_acc
def iou(self):
per_class_iou = torch.diag(self.cfm).float() / (
torch.sum(self.cfm, dim=1).float() + torch.sum(self.cfm, dim=0).float() - torch.diag(
self.cfm).float())
total_iou = torch.diag(self.cfm).sum().float() / (
torch.sum(self.cfm).float() + torch.sum(self.cfm).float() - torch.diag(self.cfm).sum().float())
return per_class_iou, total_iou
def precision(self):
per_class_precision = torch.diag(self.cfm).float() / torch.sum(self.cfm, dim=0).float()
total_precision = torch.diag(self.cfm).sum().float() / torch.sum(self.cfm, dim=0).sum().float()
return per_class_precision, total_precision
def recall(self):
per_class_recall = torch.diag(self.cfm).float() / torch.sum(self.cfm, dim=1).float()
total_recall = torch.diag(self.cfm).sum().float() / torch.sum(self.cfm, dim=1).sum().float()
return per_class_recall, total_recall
def compute(self):
acc = self.acc()
iou = self.iou()
precision = self.precision()
recall = self.recall()
results = {
'acc': acc[0].tolist(), # 每类的准确率
'total_acc': acc[1].item(), # 总体准确率
'iou': iou[0].tolist(), # 每类的 IoU
'total_iou': iou[1].item(), # 总体 IoU
'precision': precision[0].tolist(), # 每类的精确率
'total_precision': precision[1].item(), # 总体精确率
'recall': recall[0].tolist(), # 每类的召回率
'total_recall': recall[1].item() # 总体召回率
}
return results
if __name__ == '__main__':
class_num = 3
metrics = Metrics(class_num)
true_vectors = torch.tensor([0, 1, 2, 1, 0, 2, 2, 1, 0, 1])
pred_vectors = torch.tensor([0, 2, 2, 1, 0, 2, 0, 1, 1, 1])
# 将这些样本添加到混淆矩阵中
metrics.sample_add(true_vectors, pred_vectors)
results = metrics.compute()
print("评估指标:")
for key, value in results.items():
print(f"{key}: {value}")
6.模型预测
6.1 模型预测流程
训练好模型后保存结果如下:
编写Predictor类预测结果,流程如下:
定义Predictor类
用于加载训练好的模型权重,并对图像或图像文件夹进行预测。
init方法
- 初始化
Predictor类的实例,设置设备(cuda或cpu),加载模型结构(从 YAML 配置文件中获取),并调用load_weight方法加载指定的模型权重。 - 初始化图像预处理方法
transform,用于在预测前对图像进行必要的预处理操作。
load_weight方法
从指定的路径加载模型权重,并将权重加载到模型中。加载完成后,会打印一条提示信息。
predict方法
对单张图像进行预测:
- 打开图像并将其转换为 NumPy 数组。
- 使用预处理函数对图像进行预处理,并将其转换为张量格式。
- 在模型的前向传播过程中,关闭梯度计算(使用
torch.no_grad()),计算输出,并获得预测结果。 - 返回预测结果的 NumPy 数组。
predict_folder方法
对整个文件夹中的图像进行批量预测:
- 检查并创建输出文件夹。
- 对输入文件夹中的每张图像进行循环处理,调用
predict方法获取预测结果。 - 将预测结果转换为
.tif格式并保存到指定的输出文件夹中。 - 输出预测完成的信息。
测试:
- 在
main中,定义输入图像路径test_path和输出路径pred_path,指定模型权重路径model_path - 创建
Predictor对象,并调用predict_folder方法对文件夹中的图像进行预测,将预测结果保存到指定目录中。
代码如下:
import os
from PIL import Image
import torch
from config.load_config import get_train_config
from datasets.transform import transform
from tqdm import tqdm
import numpy as np
class Predictor:
def __init__(self,
weight,
yaml_fp = './config/config_model.yaml',
transform = transform['test'],
device='cuda'):
self.device = torch.device(device if torch.cuda.is_available() else 'cpu')
self.model = get_train_config(yaml_fp).model
self.model.eval()
self.weight = weight
self.transform = transform
self.load_weight()
def load_weight(self):
self.model.load_state_dict(torch.load(self.weight))
print('load model weight from ', self.weight)
def predict(self, image_path):
image = np.array(Image.open(image_path))
image = self.transform(image=image)['image'].unsqueeze(0).to(self.device)
with torch.no_grad():
output = self.model(image)
_, pred = torch.max(output, 1)
return pred.squeeze().cpu().numpy()
def predict_folder(self, input_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print("start predict ...")
for image_name in tqdm(os.listdir(input_dir)):
image_path = os.path.join(input_dir, image_name)
pred_array = self.predict(image_path)
# 保存预测结果为 .tif 文件
pred_image = Image.fromarray(pred_array.astype('uint8'))
save_path = os.path.join(output_dir, f"{image_name.split('.')[0]}.tif")
pred_image.save(save_path)
print(f"results save to {output_dir}")
if __name__ == '__main__':
test_path = './data/WHDLD/outputs/test/images'
pred_path = './data/WHDLD/outputs/test/preds'
model_path = './outputs/20240831_202015/best_model_acc_0.8322_miou_0.7127.pth'
transform = transform['test']
predictor = Predictor(weight = model_path)
predictor.predict_folder(test_path, pred_path)
6.2 模型预测结果上色
预测结果为[0, num_classes-1]的二维图像,根据数据集定义各个类的颜色并上色:
配置文件如下:
cls_dict:
bare_soil:
color: [128, 128, 128]
cls: 0
building:
color: [255, 0, 0]
cls: 1
pavement:
color: [192, 192, 0]
cls: 2
road:
color: [255, 255, 0]
cls: 3
vegetation:
color: [0, 255, 0]
cls: 4
water:
color: [0, 0, 255]
cls: 5
代码如下:
from PIL import Image
import numpy as np
import os
from tqdm import tqdm
from config.load_config import DatasetConfig
def gray_color(input_dir, output_dir, color_mapping):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for filename in tqdm(os.listdir(input_dir)):
if filename.endswith(".tif"):
gray_image_path = os.path.join(input_dir, filename)
gray_image = Image.open(gray_image_path).convert('L')
gray_array = np.array(gray_image)
# Create a color image array
color_image = np.zeros((*gray_array.shape, 3), dtype=np.uint8)
for cls_id, color in color_mapping.items():
color_image[gray_array == cls_id] = color
# Convert the color image array back to a PIL image
color_image_pil = Image.fromarray(color_image)
# Save the color image
color_image_path = os.path.join(output_dir, filename)
color_image_pil.save(color_image_path)
# print(f"Saved colored image: {color_image_path}")
if __name__ == '__main__':
config = DatasetConfig("../config/config_dataset.yaml")
color_mapping = {info['cls']: tuple(info['color']) for info in config.cls_dict.values()}
input_dir = '../data/WHDLD/outputs/test/preds'
output_dir = '../data/WHDLD/outputs/test/preds_color'
gray_color(input_dir, output_dir, color_mapping)
部分预测结果如下:

7.其他
使用loguru记录训练日志
import os
from loguru import logger
def setup_logging(output_dir):
"""
设置loguru的日志记录,按照当前运行时间作为文件名保存
:param output_dir: 日志文件保存的目录
"""
os.makedirs(output_dir, exist_ok=True)
log_file_path = os.path.join(output_dir, "training.log")
logger.remove()
logger.add(log_file_path, rotation="500 MB", retention="10 days", level="INFO")
logger.add(lambda msg: print(msg, end=""), level="INFO")
logger.info(f"Logging is set up. Logs are being saved to {log_file_path}.")
后续将继续完善和更新模型代码
代码仓库:https://gitee.com/xuxing2023/RSegment
文章链接:《【入门教程】基于深度学习的遥感图像分割流程(附代码)》
公众号:GISer阿兴


















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









