









 本文介绍了如何使用Tatoeba翻译数据集进行多语言翻译项目,包括数据集的结构、预处理步骤(存储为TSV和PT文件,去除测试集,添加任务前缀,选择简体中文),以及如何利用mT5进行分词编码。后续将讨论数据集加载和模型训练。
本文介绍了如何使用Tatoeba翻译数据集进行多语言翻译项目,包括数据集的结构、预处理步骤(存储为TSV和PT文件,去除测试集,添加任务前缀,选择简体中文),以及如何利用mT5进行分词编码。后续将讨论数据集加载和模型训练。
·请参考本系列目录:【mT5多语言翻译】之一——实战项目总览
[1] 多语言翻译数据集
数据集地址如下:https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/data。
Tatoeba翻译挑战是一个涵盖多种语言的机器翻译数据集,涉及2539种双语文本和487种语言,形成4024种语言对。这个项目提供了非常全面的训练、开发和测试数据集。
以本实战项目的中韩、中日翻译任务举例,首先去数据集里找到下载地址:


下载下来的是tar压缩包,我们把它保存到项目的待处理文件夹中:

【注】Tatoeba翻译数据集里面提供的都是通用领域的数据,如果对领域知识有要求的,还是要使用自己的打标数据效果更好。但是往往我们自己领域的数据集都很小,构建成本也大,所以我觉得可以现在Tatoeba翻译数据集上训练一次,然后再在自己的数据集上训练一遍。
[2] Tatoeba翻译数据集的构成
我们将上一节下载的压缩包解压,会得到以下内容:

主要分为3个数据集,训练集、验证集、测试集。每个集合都有3个属性,id、src、trg,它们是分开存储的。
.id文件里面存放的是每一条数据的语言编码,如:
jpn cmn_Bopo
jpn cmn_Hans
jpn cmn_Hans
jpn cmn_Hans
jpn cmn_Hans
jpn cmn_Hans
【注】由于很多语言存在不同的版本,尤其是中文,有:lzh lzh_Hans nan wuu yue_Hans yue_Hant zho zho_Bopo zho_Bopo_CN zho_Bopo_TW zho_CN zho_Hans zho_Hans_CN zho_Hans_TW zho_Hant zho_Hant_CN zho_Hant_TW zho_TW这么多种版本或者方言,
.id文件就是对每条数据进行方言种类标注。
.src文件里面存放的源文本,如:
一つ、二つ、三つ、四つ、五つ、六つ、七つ、八つ、九つ、十。
Twitterのアカウントなら、持ってるよ。
インスタやってる?
ウクライナ人ですか?
おすすめのアニメって、何?
おはよう、今アイスあるよ。
.trg文件里面存放的目标文本,如:
一、二、三、四、五、六、七、八、九、十。
我有一个推特账号。
你们用INS吗?
你是乌克兰人吗?
你有哪些推荐的动漫?
早上好、现在我有冰淇淋。
【注】这里谁是源文本,谁是目标文本其实不重要,反正这两者是互相对应的。在实际训练时,输入是谁谁就可以说是src,另外一个就是trg。所以不用纠结为什么数据集中src是jpn而不是zho,不影响我们使用。
[3] 翻译数据集的预处理
[3.1] 将数据存储为tsv文件
由于初始数据集的结构散乱,我们首先把这些文本存到tsv中方便读取。
在写代码之前,有几点预处理原则需要明确:
1、我们已经不需要测试集了。因为模型太大,数据集太大,假设模型每训练一条文本就能学习到相应的翻译知识,理论上模型训练过的文本越多越好。此时老的训练——验证——测试思路已经不在使用,甚至更极端一点连验证集都可以不需要。因为我们的原则是希望模型训练的数据越多越好,那么要不要去验证集、测试集看模型的效果意义已经不大了。
2、因为我们要训练多语言翻译,因此要给不同的任务加上前缀“translate Chinese to Japanese:”或“translate Chinese to Korean:”。但是由于显存限制,我只把序列长度设置到了10,这样输入拼接上前缀,前缀就占了5、6个token了。因此我把前缀改成jan、kor,这样既可以起到任务的标识作用,也节省了token数。
3、由于数据集中包含了数十种中文方言,这里我只取简体中文数据。
鉴于以上的三个原则,我们只处理训练集和验证集,并且只取简中数据,并在tsv中多加一列“prefix”来表示任务前缀,代码如下:
def prepare_translation_datasets(data_path, src_name):
with open(os.path.join(data_path, "train.id"), "r", encoding="utf-8") as f:
trg_id = f.readlines()
trg_id = [text.strip("\n") for text in trg_id]
with open(os.path.join(data_path, "train.trg"), "r", encoding="utf-8") as f:
trg_text = f.readlines()
trg_text = [text.strip("\n") for text in trg_text]
with open(os.path.join(data_path, "train.src"), "r", encoding="utf-8") as f:
src_text = f.readlines()
src_text = [text.strip("\n") for text in src_text]
data = []
for trg, src, id in tqdm(zip(trg_text, src_text, trg_id), total=min(len(trg_text), len(src_text))):
if trg == "" or src == "" or "zho_Hans" not in id:
continue
data.append(["{}:".format(src_name), trg, src])
train_df = pd.DataFrame(data, columns=["prefix", "input_text", "target_text"])
with open(os.path.join(data_path, "test.id"), "r", encoding="utf-8") as f:
trg_id = f.readlines()
trg_id = [text.strip("\n") for text in trg_id]
with open(os.path.join(data_path, "test.trg"), "r", encoding="utf-8") as f:
trg_text = f.readlines()
trg_text = [text.strip("\n") for text in trg_text]
with open(os.path.join(data_path, "test.src"), "r", encoding="utf-8") as f:
src_text = f.readlines()
src_text = [text.strip("\n") for text in src_text]
data = []
for trg, src, id in tqdm(zip(trg_text, src_text, trg_id), total=min(len(trg_text), len(src_text))):
if trg == "" or src == "" or "cmn_Hans" not in id:
continue
data.append(["{}:".format(src_name), trg, src])
eval_df = pd.DataFrame(data, columns=["prefix", "input_text", "target_text"])
return train_df, eval_df
函数首先打开并读取.id、.trg和.src 三个文件,分别存储目标语言的 ID、目标语言的文本和源语言的文本。
处然后,函数遍历这些列表,过滤空值和非简体中文的文本。然后再加上源数据的标识存到df对象里面。
最后,把df对象保存为tsv文件:
train_df.to_csv(tsv_name, sep="\t")
[3.2] 将tsv文本数据分词并存储为pt文件

如上图所示,在训练模型的最初阶段,需要把初始文本用分词器转换成token id,我们的数据集大概有1200万文本,如果每次训练时都重新用分词器分词,那么每次都得等很久。因此此处我们直接用mT5的分词器把原始的tsv中的数据给分词完毕,并存储到pt文件中。
首先创建mT5的分词器:
tokenizer = AutoTokenizer.from_pretrained(mt5_path)
然后定义mT5的批量编码函数,这里我设置的文本长度为20:
def encode_str(text, seq_len=20):
ids = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=text,
return_tensors='pt',
padding='max_length',
truncation=True,
max_length=seq_len,
return_attention_mask=False
)
return ids['input_ids']
最后读取tsv,将"prefix"和源文本拼接然后编码为src_id,将目标文本直接编码为trg_id,之后保存成.pt文件。
df = pd.read_csv(tsv_path, sep="\t").astype(str)
src = []
trg = []
for j in tqdm(range(len(df))):
src.append(df.iloc[j, 1] + df.iloc[j, 2])
trg.append(df.iloc[j, 3])
src_ids = encode_str(src)
trg_ids = encode_str(trg)
data = torch.stack((src_ids, trg_ids), dim=1)
torch.save(data, pt_path)
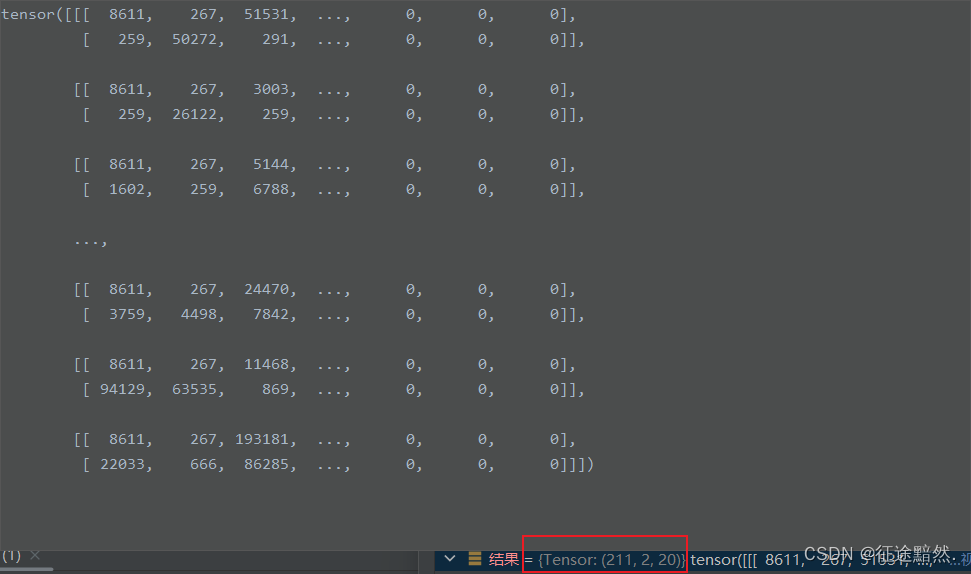
pt文件中保存的是一个(num, 2, seq)的张量,num表示数据集中的文本数,第二维中的2表示一个向量是源文本、另一个是目标文本,seq表示文本的长度。



















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











