







此示例,说明了CUDA事件,在GPU和CPU同时执行时,计算GPU 的执行时间,即在GPU上程序运行的时间。
事件被插入到cuda调用流中,由于CUDA流调用,是异步的,即:在GPU执行时,CPU可以进行计算,CPU通过查询CUDA事件来判断GPU是否已经完成任务。
cuda核函数计时
cuda里面的程序是异步执行的,
- cpu将命令写入缓存区,
- GPU读取命令启动核函数,执行任务,返回结果,cpu一般不会等待cuda函数结束,会直接去做其他的事情。
- 一般GPU会给CPU汇报执行的进度,命令缓冲区和同步信息位置 位于,页锁定主机内存上,——CPU,GPU都可以在此处读取,“同步信息位置”,内存上有一个单调递增的整数值(“进度值”)GPU完成一条指令后,这个值就会更新这个值,CPU通过读取同步信息位置就可以得到GPU的工作进度。
cuda事件可以反映这种能力,其本质是GPU 的时间戳,可以在指定的时间点上记录,所以可以用来记录核函数的运行时间,因为位置是不固定的。
但是cuda事件是在GPU上实现的,不适用于从同时包含设备代码和主机代码的混合代码情况。
// includes, system
#include <stdio.h>
// includes CUDA Runtime
#include <cuda_runtime.h>
// includes, project
#include <helper_cuda.h>
#include <helper_functions.h> // helper utility functions
__global__ void increment_kernel(int *g_data, int inc_value)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
g_data[idx] = g_data[idx] + inc_value;
}
bool correct_output(int *data, const int n, const int x)
{
//判断输出是否正确 错误的话打印error以及 data 和 x 的数值
for (int i = 0; i < n; i++)
if (data[i] != x)
{
printf("Error! data[%d] = %d, ref = %d\n", i, data[i], x);
return false;
}
return true;
}
int main(int argc, char *argv[])
{
int devID;
//cudadeviceprop 数据结构,是针对函数cudadeviceproperties定义的,其函数的功能是获取GPU计算装置的相关属性,
//比如,支持cuda 的版本号装置的名称,内存的大小,最大的thread数目,执行单元的频率等等
cudaDeviceProp deviceProps;
printf("[%s] - Starting...\n", argv[0]);
// 这将挑选出最有可能支持CUDA的设备
devID = findCudaDevice(argc, (const char **)argv);
// 设备名字
//在cuda的代码里面,错误检查可以帮助找到cuda代码里面的错误,一般有两种从代码里产生的错误,
//1.cuda API调用错误, 比如cudaMalloc()函数可能调用失败
//2.cuda kernel调用错误,可能某个kernel的实现,访问了非法内存
/*所有的cuda API调用都会返回一个cuda error值,所以检查这种调用会比较容易*/
/*cuda kernel 不返回任何值,从cuda kernel调用产生的错误可以在核函数调用完毕以后,从cudaGetLastError()中查到*/ checkCudaErrors(cudaGetDeviceProperties(&deviceProps, devID));
printf("CUDA device [%s]\n", deviceProps.name);
int n = 16 * 1024 * 1024;
int nbytes = n * sizeof(int);
int value = 26;
// 分配主机内存
int *a = 0;
checkCudaErrors(cudaMallocHost((void **)&a, nbytes));
memset(a, 0, nbytes);
// 分配设备内存
int *d_a=0;
checkCudaErrors(cudaMalloc((void **)&d_a, nbytes));
checkCudaErrors(cudaMemset(d_a, 255, nbytes));
// 设置调用的内核线程结构
dim3 threads = dim3(512, 1);
dim3 blocks = dim3(n / threads.x, 1);
// 创建cuda事件句柄
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
StopWatchInterface *timer = NULL;
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
checkCudaErrors(cudaDeviceSynchronize());
float gpu_time = 0.0f;
// 异步将工作发送给GPU(全部发送到流0)
sdkStartTimer(&timer);
cudaEventRecord(start, 0);
cudaMemcpyAsync(d_a, a, nbytes, cudaMemcpyHostToDevice, 0);
increment_kernel<<<blocks, threads, 0, 0>>>(d_a, value);
cudaMemcpyAsync(a, d_a, nbytes, cudaMemcpyDeviceToHost, 0);
cudaEventRecord(stop, 0);
sdkStopTimer(&timer);
// 让CPU在等待阶段1完成时做一些工作
unsigned long int counter=0;
while (cudaEventQuery(stop) == cudaErrorNotReady)
{
counter++;
}
checkCudaErrors(cudaEventElapsedTime(&gpu_time, start, stop));
// 打印cpu gpu的时间
printf("time spent executing by the GPU: %.2f\n", gpu_time);
printf("time spent by CPU in CUDA calls: %.2f\n", sdkGetTimerValue(&timer));
printf("CPU executed %lu iterations while waiting for GPU to finish\n", counter);
// 检查输出是否正确
bool bFinalResults = correct_output(a, n, value);
// 释放资源
checkCudaErrors(cudaEventDestroy(start));
checkCudaErrors(cudaEventDestroy(stop));
checkCudaErrors(cudaFreeHost(a));
checkCudaErrors(cudaFree(d_a));
exit(bFinalResults ? EXIT_SUCCESS : EXIT_FAILURE);
}
checkCudaErrors()
/所有的cuda API调用都会返回一个cuda error值,所以检查这种调用会比较容易/
if ( cudaSuccess != cudaMalloc( &fooPtr, fooSize ) )
printf( "Error!\n" );
CUDA kernel不返回任何值。从CUDA kernel调用产生的错误可以在该调用完毕后,从cudaGetLastError()中检查到。
fooKernel<<< x, y >>>(); // Kernel call
if ( cudaSuccess != cudaGetLastError() )
printf( "Error!\n" );
关于dim3
dim3 threads = dim3(512, 1);
dim3是一种整数向量类型,可以在cuda代码中使用,它最常见的应用是在内核调用中传递网络和块维度,还可以在任何用户代码中保存3维值
dim3 grid(512);//512*1*1
dim3 block(1024,1024);//1024*1024*1
fookernel<<<grid,block>>>();
dim3,有3个元素,x、y、z
在c代码中,dim3可被初始化为 dim3 grid={512,512,1};
在c++中,dim3可初始化为 dim3 grid(512,512,1);
不是3个元素都需要提供,初始化期间没有提供的元素都初始化为1
dim3可以转化为另一种类似的cuda数据类型unit3
https://codeyarns.com/tech/2011-02-16-cuda-dim3.html
数据传输主机计算,设备上的计算以及,在某些情况下主机和设备之间其他数据传输重叠
实现数据传输 和 其他操作之间的重叠need cuda流
cuda流
cuda流是一系列操作,这些操作按着主机代码发出的顺序,在设备上执行,流中的操作保证按照规定顺序执行,不同流中的操作可以交错,甚至在一定条件下,可以并发运行。
默认流
cuda中的所有设备操作(核函数与数据传输)都在流中进行,如果未指定流,则使用默认流(也称为”空流”)
CUDA 中的所有设备操作(内核和数据传输)都在流中运行。如果未指定流,则使用默认流(也称为“空流”)。默认流与其他流不同,因为它是与设备上的操作相关的同步流:在设备上的任何流中以前发出的所有操作完成之前,默认流中的任何操作都不会开始,并且默认流中的操作必须在任何其他操作(在设备上的任何流中)开始之前完成。
让我们看一些使用默认流的简单代码示例,并从主机和设备的角度讨论操作如何进行。
a_d = a
call increment<<<1,N>>>(a_d)
a = a_d
在上面的代码中,从设备的角度来看,所有三个操作都颁发给相同的(默认)流,并将按发出它们的顺序执行。
从主机的角度来看,隐式数据传输是阻塞或同步传输,而内核启动是异步的。由于第一行上的主机到设备数据传输是同步的,因此在主机到设备的传输完成之前,CPU 线程将不会到达第二行上的内核调用。一旦内核被发出,CPU线程就会移动到第三行,但由于设备端的执行顺序,该行上的传输无法开始。
从主机的角度来看,内核启动的异步行为使得重叠的设备和主机计算变得非常简单。我们可以修改代码以添加一些独立的CPU计算,如下所示。
a_d = a
call increment<<<1,N>>>(a_d)
call myCPUroutine(b)
a = a_d
在上面的代码中,一旦内核在设备上启动,CPU线程就会执行,使其在CPU上的执行与GPU上的内核执行重叠。主机或设备例程是先完成不会影响后续设备到主机的传输,该传输仅在内核完成后开始。从设备的角度来看,与上一个示例相比没有任何变化。设备完全不知道 。increment()myCPUroutine()myCPUroutine()
非默认流
CUDA Fortran 中的非默认流在主机代码中声明、创建和销毁,如下所示。
integer(kind=cuda_stream_kind) :: stream1
istat = cudaStreamCreate(stream1)
istat = cudaStreamDestroy(stream1)
为了向非默认流发出数据传输,我们使用该函数,该函数类似于上一篇文章中讨论的函数,但将流标识符作为第四个参数。cudaMemcpyAsync()cudaMemcpy()
istat = cudaMemcpyAsync(a_d, a, N, stream1)
cudaMemcpyAsync()在主机上是非阻塞的,因此在发出传输后立即将控制权返回到主机线程。此例程有变体,可以在指定的流中异步传输 2D 和 3D 数组部分。cudaMemcpy2DAsync() cudaMemcpy3DAsync()
要将内核发布到非默认流,我们将流标识符指定为第四个执行配置参数(第三个执行配置参数分配共享设备内存,我们将在后面讨论;现在使用 0)。
call increment<<<1,N,0,stream1>>>(a_d)
与流同步
由于非默认流中的所有操作相对于主机代码都是非阻塞的,因此您将遇到需要将主机代码与流中的操作同步的情况。有几种方法可以做到这一点。“重锤”方式是使用 ,它会阻止主机代码,直到设备上所有先前发出的操作都已完成。在大多数情况下,这是矫枉过正的,并且由于整个设备和主机线程停止而确实会损害性能。cudaDeviceSynchronize()
CUDA 流 API 具有多种不太严格的方法,用于将主机与流同步。该函数可用于阻止主机线程,直到指定流中以前发出的所有操作都已完成。该函数测试颁发给指定流的所有操作是否都已完成,而不会阻止主机执行。这些函数和操作类似于其对应的流,不同之处在于其结果基于是否已记录指定事件,而不是基于指定的流是否处于空闲状态。
cudaStreamSynchronize(stream)
cudaStreamQuery(stream)
cudaEventSynchronize(event)
cudaEventQuery(event)
重叠的内核执行和数据传输
前面我们演示了如何在默认流中将内核执行与在主机上执行代码重叠。但是,我们在这篇文章中的主要目标是向您展示如何将内核执行与数据传输重叠。要做到这一点,有几个要求。
设备必须能够“并发复制和执行”。这可以从变量的字段或实用程序的输出中查询。几乎所有具有计算能力 1.1 及更高版本的设备都具有此功能。deviceOverlapcudaDeviceProppgaccelinfo
内核执行和要重叠的数据传输必须都发生在不同的非默认流中。
数据传输中涉及的主机内存必须是固定内存。
因此,让我们从上面修改我们的简单主机代码以使用多个流,看看我们是否可以实现任何重叠。此示例的完整代码可在 Github 上找到。在修改后的代码中,我们将大小数组分解为元素块。由于内核对所有元素独立运行,因此每个块都可以独立处理。使用的(非默认)流数为 。有多种方法可以实现数据的域分解和处理;一个是循环遍历数组的每个块的所有操作,如本示例代码所示。
NstreamSizenStreams=N/streamSize
do i = 1, nStreams
offset = (i - 1) * streamSize
istat = cudaMemcpyAsync(a_d(offset+1), a(offset+1), streamSize, stream(i))
call kernel<<>>(a_d, offset)
istat = cudaMemcpyAsync(a(offset+1), a_d(offset+1), streamSize,stream(i))
enddo
另一种方法是将类似的操作批处理在一起,首先发出所有主机到设备的传输,然后是所有内核启动,然后是所有设备到主机的传输,如下面的代码所示。
do i = 1, nStreams
offset = (i - 1) * streamSize
istat = cudaMemcpyAsync(a_d(offset+1), a(offset+1), streamSize, stream(i))
enddo
do i = 1, nStreams
offset = (i - 1) * streamSize
call kernel<<>>(a_d,offset)
enddo
do i = 1, nStreams
offset = (i - 1) * streamSize
istat = cudaMemcpyAsync(a(offset+1), a_d(offset+1), streamSize, stream(i))
enddo
上面显示的两种异步方法都产生了正确的结果,并且在这两种情况下,依赖的操作都按照它们需要执行的顺序被发送到相同的流。但这两种方法的性能非常不同,这取决于所使用的特定GPU的生成。在特斯拉C1060(计算能力1.3)上运行测试代码(来自Github)会得到以下结果。
Device : Tesla C1060
Time for sequential transfer and execute (ms ): 12.92381
max error : 2.3841858e -07
Time for asynchronous V1 transfer and execute (ms ): 13.63690
max error : 2.3841858e -07
Time for asynchronous V2 transfer and execute (ms ): 8.845888
max error : 2.3841858e -07
在特斯拉C2050(计算能力2.0)上,我们得到了以下结果。
Device : Tesla C2050
Time for sequential transfer and execute (ms ): 9.984512
max error : 1.1920929E -07
Time for asynchronous V1 transfer and execute (ms ): 5.735584
max error : 1.1920929E -07
Time for asynchronous V2 transfer and execute (ms ): 7.597984
max error : 1.1920929E -07
这里第一次报告的是使用阻塞传输的顺序传输和内核执行,我们将阻塞传输用作异步加速比较的基线。为什么这两种异步策略在不同的体系结构上执行不同?为了破译这些结果,我们需要更多地了解CUDA设备如何安排和执行任务。CUDA设备包含用于各种任务的引擎,这些引擎会在操作发出时排队。在不同的引擎中,任务之间的依赖关系得到了维护,但在任何引擎中,所有的外部依赖关系都消失了;每个引擎队列中的任务按照发出的顺序执行。C1060只有一个复制引擎和一个内核引擎。在C1060上执行示例代码的时间线如下图所示。
在原理图中,我们假设主机到设备的传输、内核执行和设备到主机的传输所需的时间大致相同(选择内核代码就是为了实现这一点)。正如序列内核所期望的那样,任何操作都没有重叠。对于我们代码的第一个异步版本,在复制引擎中的执行顺序是:H2D流(1),D2H流(1),H2D流(2),D2H流(2),等等。这就是为什么我们在C1060上使用第一个异步版本时没有看到任何加速:任务以排除内核执行和数据传输重叠的顺序被发送给复制引擎。但是,对于版本2,所有主机到设备的传输都是在任何设备到主机的传输之前发出的,因此可能会出现重叠,这可以从较低的执行时间中看出。从我们的原理图中,我们预计异步版本2的执行是顺序版本的8/12,或8.7 ms,这在前面给出的计时结果中得到了证实。
在C2050上,两个特性相互作用导致了与C1060的行为差异。C2050有两个复制引擎,一个用于主机到设备的传输,另一个用于设备到主机的传输,以及一个单一的内核引擎。下图展示了我们的示例在C2050上的执行。在原理图中,我们假设主机到设备的传输、内核执行和设备到主机的传输所需的时间大致相同(选择内核代码就是为了实现这一点)。正如序列内核所期望的那样,任何操作都没有重叠。对于我们代码的第一个异步版本,在复制引擎中的执行顺序是:H2D流(1),D2H流(1),H2D流(2),D2H流(2),等等。这就是为什么我们在C1060上使用第一个异步版本时没有看到任何加速:任务以排除内核执行和数据传输重叠的顺序被发送给复制引擎。但是,对于版本2,所有主机到设备的传输都是在任何设备到主机的传输之前发出的,因此可能会出现重叠,这可以从较低的执行时间中看出。从我们的原理图中,我们预计异步版本2的执行是顺序版本的8/12,或8.7 ms,这在前面给出的计时结果中得到了证实。
在C2050上,两个特性相互作用导致了与C1060的行为差异。C2050有两个复制引擎,一个用于主机到设备的传输,另一个用于设备到主机的传输,以及一个单一的内核引擎。下图展示了我们的示例在C2050上的执行。
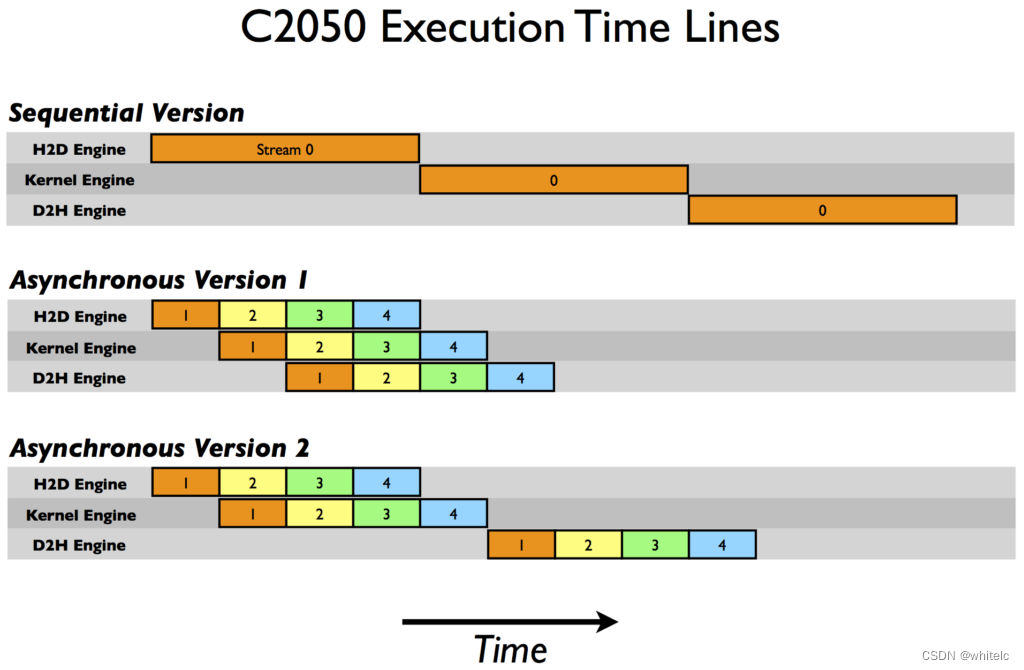
有两个复制引擎解释了为什么异步版本1达到良好的加速C2050: device-to-host传输中的数据流(我)不阻止host-to-device中传输数据流(i + 1)就像C1060因为有一个单独的引擎为每个复制C2050方向。该示意图预测了相对于顺序版本的执行时间将减少一半,这大致是我们的计时结果所显示的。
但是在C2050上的异步版本2中观察到的性能下降又如何呢?这与C2050并发运行多个内核的能力有关。当多个内核在不同的(非默认)流中被连续发出时,调度器尝试启用这些内核的并发执行,结果是延迟一个信号,这个信号通常发生在每个内核完成之后(负责启动设备到主机的传输),直到所有的内核完成。因此,虽然在我们的异步代码的第二个版本中,主机到设备的传输和内核执行之间有重叠,但内核执行和设备到主机的传输之间没有重叠。该示意图预测异步版本2的总体时间为顺序版本的9/12,即7.5 ms,我们的计时结果证实了这一点。
在CUDA Fortran异步数据传输中有一个更详细的例子描述。好消息是,对于具有3.5计算能力的设备(K20系列),Hyper-Q功能消除了定制启动顺序的需要,所以上述两种方法都可以工作。我们将在以后的文章中讨论使用开普勒功能,但现在,这里是在特斯拉K20c GPU上运行示例代码的结果。正如您所看到的,这两个异步方法实现了与同步代码相同的加速。
Device : Tesla K20c
Time for sequential transfer and execute (ms): 7.101760
max error : 1.1920929E -07
Time for asynchronous V1 transfer and execute (ms): 3.974144
max error : 1.1920929E -07
Time for asynchronous V2 transfer and execute (ms): 3.967616
max error : 1.1920929E -07
**
总结
**
本文和前一篇文章讨论了如何优化主机和设备之间的数据传输。前一篇文章关注的是如何最小化执行此类传输的时间,而这篇文章介绍了流以及如何通过并发执行副本和内核来使用流来屏蔽数据传输时间。
在一篇关于流的文章中,我应该提到,虽然使用默认流对开发代码很方便,但同步代码更简单——最终你的代码应该使用非默认流。这在编写库时尤其重要。如果库中的代码使用默认流,那么最终用户就没有机会将数据传输与库的内核执行重叠。
现在您已经知道了如何在主机和设备之间有效地移动数据,因此我们将在下一篇文章中研究如何从内核中有效地访问数据。
原文链接
https://developer.nvidia.com/blog/how-overlap-data-transfers-cuda-fortran/















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









