










https://zhuanlan.zhihu.com/p/53044278
https://zhuanlan.zhihu.com/p/45483149
abstract: 训练了一个神经网络可以从单张图像端到端的回归出相机的位置和姿态,有别于SLAM,不再需要额外的工程操作或者图优化。室外精度达到2m,3°。室内精度达到0.5m,5°偏差。网络是23层,利用transfer learning from recognition to re-localization 在目标分类的网络上pre-train的模型。比依赖sift关键点提取,匹配的方法更robust。
Contribution:
1)利用transfer learning 任务从目标识别,迁移到re-localization。
- 利用structure from motion根据图像序列/视频,自动生成训练label(camera pose),减少了人类标注的工作。
3)避免传统SLAM的pipeline: 比如需要存储densely spaced keyframes, appearance-based localization, landmarked-based pose estimation, frame-to-frame feature correspondence.
Loss function:
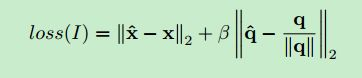
作者实验发现把位置和姿态分成两个网络进行训练的效果并不好,猜测是位置和姿态的耦合关系,所以还是要放在一起训练。
网络结构:
GoogLeNet pre-trained for classification 改造成regression问题。
-
replace the three softmax classfiers with affine regressors.
-
在最终输出层之前插入了一个全连接层,before the regressor.用来当作local feature vector.
一个比较有趣的应用就是你在指定区域拍张照后, 然后得到google map里街景的一个结果
http://mi.eng.cam.ac.uk/projects/relocalisation/#results















 5268
5268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









