







理论推导
预测值:a*x+b
x:样本值
a,b:待确定
损失函数(最小二乘法),一个样本为:
1
2
1 \over 2
21
(
y
−
a
∗
x
−
b
)
2
(y-a*x-b)^2
(y−a∗x−b)2
代价函数(对于所有样本):J(a,b)=
1
2
m
1 \over 2m
2m1
∑
i
=
1
m
\sum_{i=1}^{m}
∑i=1m
(
y
(
i
)
−
a
∗
x
(
i
)
−
b
)
2
(y^{(i)}-a*x^{(i)}-b)^2
(y(i)−a∗x(i)−b)2
梯度下降公式:a=a-
1
m
1 \over m
m1
∑
i
=
1
m
\sum_{i=1}^{m}
∑i=1m
(
y
(
i
)
−
a
∗
x
(
i
)
−
b
)
(y^{(i)}-a*x^{(i)}-b)
(y(i)−a∗x(i)−b)×(-
x
(
i
)
x^{(i)}
x(i))
b=b-
1
m
1 \over m
m1
∑
i
=
1
m
\sum_{i=1}^{m}
∑i=1m
(
y
(
i
)
−
a
∗
x
(
i
)
−
b
)
(y^{(i)}-a*x^{(i)}-b)
(y(i)−a∗x(i)−b)
代码
梯度下降
import numpy as np
import matplotlib.pyplot as plt
#载入数据
data=np.genfromtxt("data.csv",delimiter=",")
#样本值
x=data[:,0]
#真实值
y=data[:,1]
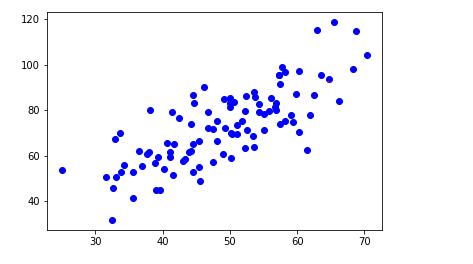
#绘制散点图
plt.scatter(x,y,color='b')
plt.show()
#一元线性回归 预测值:ax+b
a=0
b=0
#学习率
learning_rate=0.0001
#循环次数
loop=50
#梯度下降计算
def gradient_descent(x,y,a,b,learning_rate,loop):
#长度
m=float(len(x))
for i in range(loop):
#两个临时变量,存放加和
a_temp=0
b_temp=0
for j in range(0,len(x)):
a_temp+=-(1/m)*(y[j]-a*x[j]-b)*x[j]
b_temp+=(1/m)*(y[j]-a*x[j]-b)
#更新参数
a=a-a_temp*learning_rate
b=b-b_temp*learning_rate
"""
if i % 5==0:
plt.plot(x,y,'b.')
plt.plot(x,a*x+b,'r')
plt.show()
"""
return a,b
#计算损失值,最小二乘法
def error(a,b,x,y):
totalError=0
for i in range(len(x)):
totalError+=(y[i]-a*x[i]-b)**2
return totalError/(2*float(len(x)))
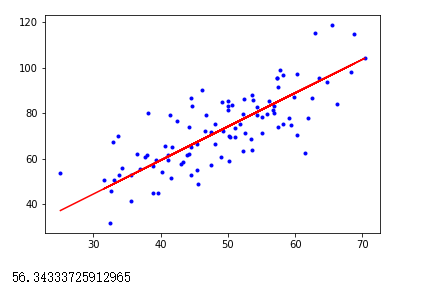
a,b=gradient_descent(x,y,a,b,learning_rate,loop)
plt.plot(x,y,'b.')
plt.plot(x,a*x+b,'r')
plt.show()
print(error(a,b,x,y))
sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
#载入数据
data=np.genfromtxt("E:\\研究生\\资料\\程序\\回归\\data.csv",delimiter=',')
#样本值
x=data[:,0]
y=data[:,1]
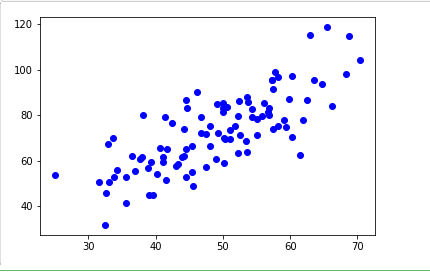
plt.scatter(x,y,color='b')
plt.show()
#取某列数据后,再加一个维度,变成矩阵。
x=data[:,0,np.newaxis]
y=data[:,1,np.newaxis]
#创建并拟合模型
model=LinearRegression()
#要求数据为矩阵
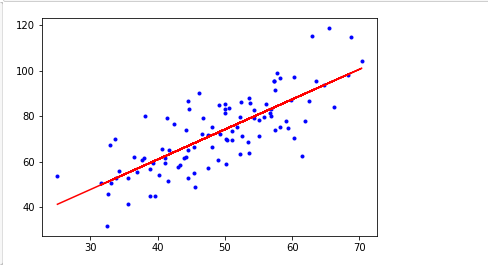
model.fit(x,y)

plt.plot(x,y,'b.')
plt.plot(x,model.predict(x),'r')
plt.show()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











