









前言
数据结构与算法这门课,应用于具体算法题过程中,stl确实可以实现,但速度很慢,很容易出现超时的问题,而且对于memory空间,如果开辟的有问题,再一次调整又消耗想东西的时间,用数组模拟我们学过的stl容器,往往是最优解,当然了,有对于数据结构深度理解的话,作为初试去答题还是可以的,数组模拟仅作为算法题的默认解决方法。
算法 五个特征 输入输出有穷有效 确定
算法的五个性能标准 正确 可使用 效率 健壮可读
基础模型
单链表
实现一个单链表,链表初始为空,支持三种操作:
向链表头插入一个数;
删除第 k 个插入的数后面的数;
在第 k 个插入的数后插入一个数。
现在要对该链表进行 M 次操作,进行完所有操作后,从头到尾输出整个链表。
注意:题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
H x,表示向链表头插入一个数 x。
D k,表示删除第 k 个插入的数后面的数(当 k 为 0 时,表示删除头结点)。
I k x,表示在第 k 个插入的数后面插入一个数 x(此操作中 k 均大于 0)。
head 表示头结点,e数组存储元素,ne数组存储下一个节点索引,indx表示下一个可以存储元素的位置索引。
头结点后面添加元素:
在e的idx处存储元素e[ide] = x;
该元素插入到头结点后面 ne[idx] = head;
头结点指向该元素 head = idx;
idx 指向下一个可存储元素的位置 idx++。
在索引 k 后插入一个数
在e的idx处存储元素e[index] = x
该元素插入到第k个插入的数后面 ne[idx] = ne[k];
第k个插入的数指向该元素 ne[k] = idx;
idx 指向下一个可存储元素的位置 idx++。
删索引为 k 的元素的后一个元素:
ne[k] 的值更新为 ne[ne[k]]
类似于寻根问祖的方法,与后面会提到de递归while find(find(a))情况类似
#include <iostream>
using namespace std;
const int N = 100010;
// head 表示头结点的下标
// e[i] 表示节点i的值
// ne[i] 表示节点i的next指针是多少
// idx 存储当前已经用到了哪个点
int head=-1, e[N], ne[N], idx=0;
void add_to_head(int x){
e[idx] = x, ne[idx] = head, head = idx ++ ;
}
void add(int k, int x){
e[idx] = x, ne[idx] = ne[k], ne[k] = idx ++ ;
}
void remove(int k){
ne[k] = ne[ne[k]];
}
int main(){
int m;
cin >> m;
while (m -- ){
int k, x;
char op;
cin >> op;
if (op == 'H') {
cin >> x;
add_to_head(x);
}
else if (op == 'D'){
cin >> k;
if (!k) head = ne[head];
else remove(k - 1);
}
else {
cin >> k >> x;
add(k - 1, x);
}
}
for (int i = head; i != -1; i = ne[i]) cout << e[i] << ' ';
cout << endl;
return 0;
}
双链表
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
L x,表示在链表的最左端插入数 x。
R x,表示在链表的最右端插入数 x。
D k,表示将第 k 个插入的数删除。
IL k x,表示在第 k 个插入的数左侧插入一个数。
IR k x,表示在第 k 个插入的数右侧插入一个数。
这道题是的核心是两侧的头和尾要有溯源关系,指针位置能互相链接,
add函数,根据k来插入因为是k+1=index的理论,是找到前一个进行插入

remove函数这里的k是第几个插入的数,而不是当前序列的第几个数

简单的代码就不写了,将核心代码写出来
#include<iostream>
using namespace std;
const int N=1e5+10;
int e[N],r[N],l[N],idx=1;
void init(){
r[0]=1;
l[1]=0;
}
void insert(int k,int x){
e[++idx]=x;
r[idx]=r[k];
l[idx]=k;
l[r[k]]=idx;
r[k]=idx;
}
void del(int k){
l[r[k]]=l[k];
r[l[k]]=r[k];
}
模拟栈
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令为 push x,pop,empty,query 中的一种。
模拟栈还是以数组的形式,下标的++和–,用来作为top和maxsize的排序
#include<iostream>
using namespace std;
const int N=100010;
int stack[N],top;
int main()
{
int m;
cin>>m;
while(m--)
{
string opration;
int x;
cin>>opration;
if(opration == "push")
{
cin>>x;
stack[top++]=x;
}
else if(opration == "pop")
--top;
else if(opration == "empty")
if(top) printf("NO\n");
else printf("YES\n");
else
cout<<stack[top-1]<<endl;
}
return 0;
}
表达式求值
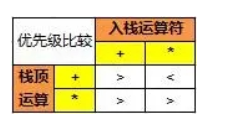
这个是好多算法题或者算法书中经常遇到的,也是之后在学编译原理的时候用的前缀表达式,先确定eval的优先级,然后计算,主要是()的问题,while一层层往里面算
#include <bits/stdc++.h>
using namespace std;
stack<int> num;
stack<char> op;
//优先级表
unordered_map<char, int> h{ {'+', 1}, {'-', 1}, {'*',2}, {'/', 2} };
void eval()//求值{
int a = num.top();num.pop();
int b = num.top();num.pop();
char p = op.top();op.pop();
int r = 0;
if (p == '+') r = b + a;
if (p == '-') r = b - a;
if (p == '*') r = b * a;
if (p == '/') r = b / a;
num.push(r);
}
int main()
{
string s;
cin >> s;
for (int i = 0; i < s.size(); i++) {
if (isdigit(s[i]))//数字入栈
{
int x = 0, j = i;//计算数字
while (j < s.size() && isdigit(s[j])) {
x = x * 10 + s[j] - '0';
j++;
}
num.push(x);//数字入栈
i = j - 1;
}
else if (s[i] == '('){
op.push(s[i]);
}
else if (s[i] == ')') {
while(op.top() != '(')//一直计算到左括号
eval();
op.pop();//左括号出栈
}
else
{
while (op.size() && h[op.top()] >= h[s[i]])//待入栈运算符优先级低,则先计算
eval();
op.push(s[i]);//操作符入栈
}
}
while (op.size()) eval();//剩余的进行计算
cout << num.top() << endl;//输出结果
return 0;
}
模拟队列
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令为 push x,pop,empty,query 中的一种。
head-tail<=0是之后在模拟队列中常用的检测模式,在后面的滑动窗口和kmp中都有使用
#include<iostream>
using namespace std;
const int N=1e5+10;
int que[N],head,tail;
void insert(int x)
{
que[tail++]=x;
}
int main()
{
int m;
cin>>m;
while(m--)
{
string op;
cin>>op;
if(op=="push")//向队列插入一个数
{
int x;
cin>>x;
insert(x);
}
else if(op=="pop") //队列出一个数
{
if(tail-head) {
head++;
}
}
else if(op=="empty") //判断栈是否为空
{
if(tail-head!=0) cout<<"NO"<<endl;
else cout<<"YES"<<endl;
}
else
{
cout<<que[head]<<endl;
}
}
}
单调栈
给定一个长度为 N 的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出 −1。
用单调递增栈,当该元素可以入栈的时候,栈顶元素就是它左侧第一个比它小的元素。
#include <iostream>
using namespace std;
const int N = 100010;
int stk[N], tt;
int main()
{
int n;
cin >> n;
while (n -- )
{
int x;
scanf("%d", &x);
while (tt && stk[tt] >= x) tt -- ;//如果栈顶元素大于当前待入栈元素,则出栈
if (!tt) printf("-1 ");//如果栈空,则没有比该元素小的值。
else printf("%d ", stk[tt]);//栈顶元素就是左侧第一个比它小的元素。
stk[ ++ tt] = x;
}
return 0;
}
核心应用题
回文系列
天大最爱的回文梗
给定一个字符串,请你求出其中的最长回文子串的长度。
暴力朴素
#include<iostream>
#include<cstring>
using namespace std;
int main()
{
string str;
getline(cin,str);
int res=0;
for(int i=0;i<str.size();i++)
{
int l=i-1,r=i+1;
while(l>=0&&r<str.size()&&str[l]==str[r]) l--,r++;
res=max(res,r-l-1);
l=i,r=i+1;
while(l>=0&&r<str.size()&&str[l]==str[r]) l--,r++;
res=max(res,r-l-1);
}
cout<<res<<endl;
return 0;
}
字符串哈希
核心思想:将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧:取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
全文解
typedef unsigned long long ULL;
typedef pair<int,int> PII;
/*=====================Guxier=====================*/
const int N = 2e6 + 10 , P = 131;
char s[N];
ULL hl[N] , hr[N] , p[N];
// p 是进制数,经验值p=131或13331
// 使得字符串哈希不产生冲突
ULL get(ULL h[] ,int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
int T = 1;
while(scanf("%s", s+1) ,strcmp(s+1 , "END"))
{
int n = strlen(s+1);
for(int i = 2*n ; i > 0 ; i -= 2)
{
s[i] = s[i/2];
s[i - 1] = 'z' + 1;
}
n *= 2 ;
p[0] = 1;
for(int i = 1, j = n; i <= n ; i++ , j--)
{
hl[i] = hl[i-1] * P + s[i] - 'a' + 1;
hr[i] = hr[i-1] * P + s[j] - 'a' + 1;
p[i] = p[i-1] * P;
}
int res = 0;
for(int i = 1 ; i <= n ; i++ )
{
int l = 0 , r = min(i - 1, n - i);
while(l < r)
{
int mid = l+r+1 >> 1;
if(get(hl , i-mid , i-1) != get(hr , n - (i+mid) +1, n - (i + 1) + 1) )
r = mid - 1;
else l = mid;
}
if(s[i - l] <= 'z') res = max(res, l + 1);
else res = max(res , l);
}
cout << "Case " << T++ << ": ";
cout << res << endl;
}
puts("");
return 0;
}
对于高精度的计算
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
bool flag = true;
bool check(string str)
{
for (int i = 0, j = str.size() - 1; i < j; i ++ , j -- )
if (str[i] != str[j]) return false;
return true;
}
vector<int> add(vector<int> &A, vector<int> &B)
{
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); i ++ )
{
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(t);
return C;
}
int main()
{
string a;
int n;
cin >> a >> n;
if (check(a)) cout << a << endl << "0" << endl;
else
{
int cnt = 0;
for (int i = 0; i < n; i ++ )
{
vector<int> A, B;
for (int i = a.size() - 1; i >= 0; i -- ) A.push_back(a[i] - '0');
for (int i = 0; i < a.size(); i ++ ) B.push_back(a[i] - '0');
auto C = add(A, B);
cnt ++ ;
string res;
for (int i = C.size() - 1; i >= 0; i -- ) res += to_string(C[i]);
if (check(res))
{
cout << res << endl << cnt << endl;
flag = false;
break;
}
else a = res;
}
if (cnt == n && flag == true) cout << a << endl << n << endl;
}
return 0;
}
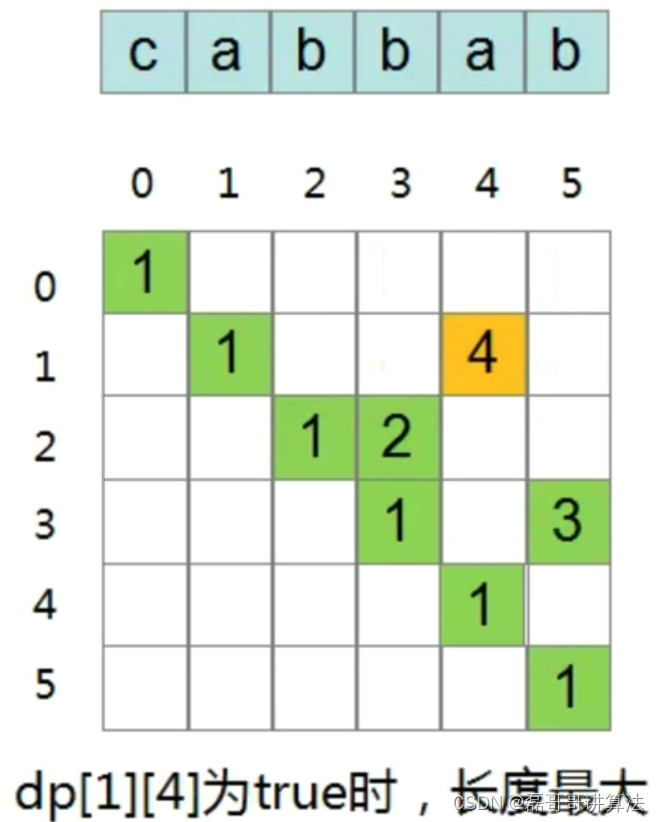
动态规划:
f[i][j] 表示字符串 s 的第 i 个字符到第 j 个字符是否为回文子串;
f[i][j] 是回文子串的条件为 [i+1,j-1] 回文,且 s[i] == s[j];
边界情况:
- i == j 时,一定回文,f[i][j] = true;
- i + 1 == j 时,当且仅当 s[i] == s[j] 时回文;
故:
- i == j, f[i][j] = true;
- i + 1 == j, f[i][j] = s[i] == s[j];
- 其他,f[i][j] = f[i+1][j-1] && s[i] == s[j];
注意状态转移时,当前状态 i,j 取决于 i + 1, j - 1,故代码的中 i 需要递减遍历;
#include<iostream>
using namespace std;
const int N = 1e3 + 7;
string s;
int f[N][N];
int main() {
getline(cin, s);
int n = s.size();
int ans = 0;
for (int i = n - 1; i >= 0; --i) {
for (int j = i; j < n; ++j) {
if (i == j) f[i][j] = 1;
else if (i+1 == j) f[i][j] = s[i] == s[j];
else f[i][j] = f[i+1][j-1] && s[i] == s[j];
if (f[i][j]) {
ans = max(ans, j - i + 1);
}
}
}
cout << ans;
return 0;
}
manacher
从中心扩展延伸的方法的缺陷:处理字符串长度的奇偶性带来的对称轴不确定问题
解决方案,对原来的字符串进行处理,在首尾和所有空隙插入一个无关字符,插入后不改变原串中回文的性质,但串长都变成了奇数.
定义:回文半径:一个回文串中最左或最右位置的字符到其对称轴的距离 ,用 p[i]p[i] 表示第 ii 个字符的回文半径.
const int N=22000010;
char s[N],str[N];
int pos[N];
int init() //处理原字符串
{
int len=strlen(s);
str[0]='@'; str[1]='#'; //@是防止越界
int j=2;
for ( int i=0; i<len; i++ )
str[j++]=s[i],str[j++]='#';
str[j]='\0'; return j;
}
int manacher()
{
int ans=-1,len=init(),mx=0,id=0;
for ( int i=1; i<len; i++ )
{
if ( i<mx ) pos[i]=min( pos[id*2-i],mx-i ); //situation1
else pos[i]=1; //situation2
while ( str[i+pos[i]]==str[i-pos[i]] ) pos[i]++; //扩展
if ( pos[i]+i>mx ) mx=pos[i]+i,id=i; //update id
ans=max( ans,pos[i]-1 );
}
return ans;
}
整合系列
char s[N];
int p[N];
int main(){
int cnt = 0;
while (scanf("%s", s + 1) && strcmp(s + 1, "END")){
int n = strlen(s + 1) * 2;
for (int i = n; i; i -= 2){
s[i] = s[i / 2];
s[i - 1] = 'z' + 1;
}//#号话,强行变成奇数
s[0] = '$';
s[ ++ n] = 'z' + 1;
int mx = 0, c = 0, ans = 0;
memset(p, 0, sizeof p);//初始化回文半径存储
for(int i=1;i<=n;i++){
if(i<mx)p[i]=min(mx-i,p[2*c-i]);//最右侧r>移动的回文中心c的移动长度i,就是补充到可用半径
else p[i]=1;//是从三种情况优化为,1+2,大于n等于n的时候是1,外延扩展
while(s[i-p[i]]==s[i+p[i]])p[i]++;//因为外延所以动态更改
if(p[i]+i>mx){
//更改完会影响最大的右侧,所以看你外延了多少,并且回文中心也会移动,因为两个回文的中心必然是绿色共同。
mx=p[i]+i;
c=i;
}
ans=max(ans,p[i]);
}
printf("Case %d: %d\n", ++ cnt, ans - 1);//回文长度等于回文序列最大值-1。
}
滑动窗口
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int n, k, q[N], a[N];//q[N]存的是数组下标
int main()
{
int tt = -1, hh=0;//hh队列头 tt队列尾
cin.tie(0);
ios::sync_with_stdio(false);
cin>>n>>k;
for(int i = 0; i <n; i ++) cin>>a[i];
for(int i = 0; i < n; i ++)
{
//维持滑动窗口的大小
//当队列不为空(hh <= tt) 且 当当前滑动窗口的大小(i - q[hh] + 1)>我们设定的
//滑动窗口的大小(k),队列弹出队列头元素以维持滑动窗口的大小
if(hh <= tt && k < i - q[hh] + 1) hh ++;
//构造单调递增队列
//当队列不为空(hh <= tt) 且 当队列队尾元素>=当前元素(a[i])时,那么队尾元素
//就一定不是当前窗口最小值,删去队尾元素,加入当前元素(q[ ++ tt] = i)
while(hh <= tt && a[q[tt]] >= a[i]) tt --;
q[ ++ tt] = i;
if(i + 1 >= k) printf("%d ", a[q[hh]]);
//真实跑一遍程序的话,可以理解为 head《tail那么队列式可以有,然后i-q[hh]+1是看滑动窗口溢出了吗,如果溢出,就把之前的那个派出去,head++,q[head]是每次的输出点,tail则是窗口的单调队列,tail因为输出变为-1,在++之后又变成了q[0]的输出,去q[]是用来储存a[]的位置下标的。
}
KMP算法
给定一个模式串 S,以及一个模板串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串 P 在模式串 S 中多次作为子串出现。
求出模板串 P 在模式串 S 中所有出现的位置的起始下标。
求Next数组:
// s[]是模式串,p[]是模板串, n是s的长度,m是p的长度
// 为什么要从i = 2开始匹配?因为next[1] = 0,已经确定了,所以应该从i = 2开始匹配。
// 注意:next[i]的定义是非平凡的最大后缀等于最大前缀,next[i]必须要小于i
// 对于每一个i开始匹配过程
for (int i = 2, j = 0; i <= m; i ++ )
{
// 如果p[i] != p[j + 1]那么,就跳到ne[j]再进行匹配p[i]与p[j + 1],直到p[i] == p[j + 1]或j = 0为止
// j一定要大于0,因为j大于0才能跳转到next[j]嘛,ne[0]没有意义
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1])j++;
ne[i] = j;
}//能理解的话最好,理解不了的话可以看一下印度阿三的b站流程讲解https://www.bilibili.com/video/BV18k4y1m7Ar?spm_id_from=333.337.search-card.all.click
// 匹配
for(int i=1,j=0;i<=m;i++){
while(j&&s[i]!=p[j+1])j=ne[j];
if(s[i]==p[j+1])j++;
if(j==n){
printf("%d ",i-n);
j=ne[j];
}
}
return 0;
}
trie树 字符统计
第一行包含整数 N,表示操作数。
接下来 N 行,每行包含一个操作指令,指令为 I x 或 Q x 中的一种。
先了解一下数组模拟树,既是tire树

这也是之前提到的find(find(a))找跟结点,当重复寻到的时候只是修改q[i]++;
因为一旦有不匹配的情况,就变成新的分支插入,如果从头到脚,走到标记点就输出
可以理解为一个庞大的二维填空表,只有符合第一层,才能通过对应的下标位序掉到第二层,如果之前没有洞口的话,就开辟一个新的洞口。
#include<iostream>
using namespace std;
const int N=1e5+10;
int trie[N][26],q[N],idx;
void insert(string x)
{
int p=0;
for(int i=0;x[i];i++)
{
int word=x[i]-'a';
if(!trie[p][word]) trie[p][word]=++idx;
p=trie[p][word];
}
q[p]++;
}
int query(string x)
{
int p=0;
for(int i=0;x[i];i++)
{
int word=x[i]-'a';
if(!trie[p][word]) return 0;
p=trie[p][word];
}
return q[p];
}
tire树 最大异或对
在给定的 N 个整数 A1,A2……AN 中选出两个进行 xor(异或)运算,得到的结果最大是多少?
也就是以tire的填空,但每次要走相反的方向
其实所有的tire都可以暴力,n^2;
当然用trie就可以变成n
第一维N是题目给的数据范围,像在trie树中的模板题当中N为字符串的总长度(这里的总长度为所有的字符串的长度加起来),在本题中N需要自己计算,最大为N*31(其实根本达不到这么大,举个简单的例子假设用0和1编码,按照前面的计算最大的方法应该是4乘2=8但其实只有6个结点)。
第二维x代表着儿子结点的可能性有多少,模板题中是字符串,而题目本身又限定了均为小写字母所以只有26种可能性,在本题中下一位只有0或者1两种情况所以为2。
而这个二维数组本身存的是当前结点的下标,就是N喽,所以总结的话son[N][x]存的就是第N的结点的x儿子的下标是多少,然后idx就是第一个可以用的下标。
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010;
int a[N], son[N * 31][2]; // 在trie树中 二维数组son存的是节点的下标
// 第一维就是下标的值 第二维代表着儿子 在本题中 只有0或1 两个儿子
int n, idx;
void insert(int x){
int p = 0; //
for (int i = 31; i >= 0; i--){
int u = x >> i & 1; // 取二进制数的某一位的值
if (!son[p][u]) son[p][u] = ++idx; // 如果下标为p的点的u(0或1)这个儿子不存在,那就创建
p = son[p][u];
}
}
int query(int x){
int p = 0, ret = 0;
for (int i = 31; i >= 0; i--){
int u = x >> i & 1;
if (!son[p][!u]) {
p = son[p][u];
ret = ret * 2 + u; // 这个地方与十进制一样 n = n * 10 + x;
}
else{
p = son[p][!u];
ret = ret * 2 + !u;
}
}
ret = ret ^ x;
return ret;
}
并查集
一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。
现在要进行 m 个操作,操作共有两种:
M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作;
Q a b,询问编号为 a 和 b 的两个数是否在同一个集合中;
也许这道题会让大家想起来上一篇算法基础里的最后一道题,但是这个这是溯源就可以
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int p[N];
int find(int x){ //返回x的祖先节点 + 路径压缩
//祖先节点的父节点是自己本身
if(p[x] != x){
//将x的父亲置为x父亲的父亲,实现路径的压缩
p[x] = find(p[x]);
}
return p[x];
}
int main(){
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i ++) p[i] = i; //初始化,让数x的父节点指向自己
while(m --){
char op[2];
int a, b;
scanf("%s%d%d", op, &a, &b);
if(op[0] == 'M') p[find(a)] = find(b); //将a的祖先点的父节点置为b的祖先节点
else{
if(find(a) == find(b)) puts("Yes");
else puts("No");
}
}
return 0;
}
连通块
给定一个包含 n 个点(编号为 1∼n)的无向图,初始时图中没有边。
现在要进行 m 个操作,操作共有三种:
C a b,在点 a 和点 b 之间连一条边,a 和 b 可能相等;
Q1 a b,询问点 a 和点 b 是否在同一个连通块中,a 和 b 可能相等;
Q2 a,询问点 a 所在连通块中点的数量;


p[find(a)] = find(b);
size[b] += size[a];//合并操作,归到跟结点,然后在size数组里面加起来
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int p[N], cnt[N]; // cnt[ ]是表示大小的集合
int find(int x) //查询祖宗结点
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
cnt[i] = 1;
}
while (m -- )
{
string op;
int a, b;
cin >> op;
if (op == "C")
{
cin >> a >> b;
a = find(a), b = find(b);
if (a != b)
{
p[a] = b;
cnt[b] += cnt[a]; //执行合并操作
}
}
else if (op == "Q1")
{
cin >> a >> b;
if (find(a) == find(b)) puts("Yes");
else puts("No");
}
else
{
cin >> a;
cout << cnt[find(a)] << endl; //只有祖宗结点的size[ ]是有意义的
}
}
return 0;
}
食物链
动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形。
A 吃 B,B 吃 C,C 吃 A。
现有 N 个动物,以 1∼N 编号。
每个动物都是 A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 N 个动物所构成的食物链关系进行描述:
第一种说法是 1 X Y,表示 X 和 Y 是同类。
第二种说法是 2 X Y,表示 X 吃 Y。
此人对 N 个动物,用上述两种说法,一句接一句地说出 K 句话,这 K 句话有的是真的,有的是假的。
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
当前的话与前面的某些真的话冲突,就是假话;
当前的话中 X 或 Y 比 N 大,就是假话;
当前的话表示 X 吃 X,就是假话。
你的任务是根据给定的 N 和 K 句话,输出假话的总数
做法还是压缩路径,其次是取模,求同类,因为始终是三角形管理
x 和 y 同类的情况
判断 x 和 y 是否是同类
- 首先判断 x 和 y 是否都在同一个 root 节点上
1.1 如果 x 和 y 的父节点(p1, p2)在同一个 root 节点上(说明 p1 和 p2 已经处理过关系了),判断距离是否相等 (d[x] % M == d[y] % M)
1.2 如果 p1 != p2,说明 x 和 y 还没有关系,可以进行合并
#include<bits/stdc++.h>
using namespace std;
int n;
int k;
int D;
int x;
int y;
const int N = 5e4 + 10;
const int M = 3;
int parent[N];
int d[N];
void init() {
for (int i = 0; i <= n; i++) {
parent[i] = i;
d[i] = 0;
}
}
int find(int x) {
if (x != parent[x]) {
int oldParent = parent[x];
parent[x] = find(parent[x]);
d[x] = (d[x] + d[oldParent]) % M;
}
return parent[x];
}
bool D1(int x, int y) {
int p1 = find(x);
int p2 = find(y);
// 如果 x 和 y 已经处理过了
if (p1 == p2) {
return d[x] % M == d[y] % M;
}
parent[p2] = p1;
d[p2] = ((d[x] - d[y]) + M) % M;
return true;
}
bool D2(int x, int y) {
int p1 = find(x);
int p2 = find(y);
// 如果 x 和 y 已经处理过了
if (p1 == p2) {
return d[x] % M == (d[y]+1) % M;
}
parent[p2] = p1;
d[p2] = ((d[x]-d[y]-1) + M) % M;
return true;
}
int main(void) {
int res = 0;
cin >> n;
init();
cin >> k;
while (k--) {
cin >> D >> x >> y;
if (x > n || y > n) {
res += 1;
} else {
if (D == 1) {
if (D1(x, y) == false) {
res += 1;
}
}
if (D == 2) {
if (D2(x, y) == false) {
res += 1;
}
}
}
}
cout << res << endl;
return 0;
}
堆排序
堆排序也有可能会考,但是这次会把他放在数据结构模拟这块
堆,就是大根堆,小根堆,类似于模拟树
重点理解一下for循环 是2的n次方存储,+1和偶存,H[1]是顶,每次读取完就删掉,堆进行换头
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
int h[N],s;
void down(int u){
int t=u;
if(u*2<=s&&h[u*2]<h[t])t=u*2;
if(u*2+1<=s&&h[u*2+1]<h[t])t=u*2+1;
if(t!=u){
swap(h[t],h[u]);
down(t);
}
}
int main(){
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i ++ ) scanf("%d", &h[i]);
s = n; //初始化size,表示堆里有n 个元素
for (int i = n / 2; i; i --) down(i);
while(m--){
printf("%d ",h[1]);
h[1]=h[s];
s--;
down(1);
}
return 0;
}
下面是有关跟堆的操作和图解
//如何手写一个堆?完全二叉树 5个操作
//1. 插入一个数 heap[ ++ size] = x; up(size);
//2. 求集合中的最小值 heap[1]
//3. 删除最小值 heap[1] = heap[size]; size -- ;down(1);
//4. 删除任意一个元素 heap[k] = heap[size]; size -- ;up(k); down(k);
//5. 修改任意一个元素 heap[k] = x; up(k); down(k);
考虑一下模拟堆中的映射关系
{
一般堆的定义为:
int h[maxn],kp[maxn],pk[maxn],idx,len;
h[maxn] 表示堆
kp[maxn] 表示堆 第 k 个数——> h中结点(point)编号的映射
pk[maxn] 表示堆 结点编号为 p 的 结点——> h中第 k 个数的映射
idx表示 已经插入 过 多少结点
//idx!=len
len表示堆中的所有结点的数量
}
#include<iostream>
using namespace std;
int const maxn =1e5+10;
int h[maxn],kp[maxn],pk[maxn],idx,len;
void h_swap(int a,int b)
{
swap(h[a],h[b]); //交换数值
swap(pk[a],pk[b]); //交换pk映射
swap(kp[pk[a]],kp[pk[b]]); //交换kp映射
}
void down(int u) {
int t=u;
if(2*u<=len && h[u*2]<h[t]) t=u*2;
if(2*u+1<=len && h[u*2+1]<h[t]) t=u*2+1;
if(t!=u) {
h_swap(t,u);
down(t);
}
}
void up(int u){
while(u/2 && h[u/2]>h[u]){
h_swap(u/2,u);
u/=2;
}
}
insert:将插入的元素放入最小根的底端然后进行up操作
delt:将删除元素t 与 最后一个元素交换 然后down(t)(这里的t是交换后最后一共元素现在所处的编号)len--
int main()
{
int n; cin>>n;
while(n--)
{
string aim; cin>>aim;
if(aim=="I")
{
int x; cin>>x;
h[++len]=x;
pk[len]=++idx;
kp[idx]=len;
up(len);
}
else if(aim=="PM")
{
cout<<h[1]<<endl;
}
else if(aim=="DM")
{
h_swap(1,len--);
down(1);
}
else if(aim=="D")
{
int k; cin>>k;
int u=kp[k];
h_swap(kp[k],len--);
up(u);
down(u);
//down就是调整,up是找根
}
else if(aim=="C")
{
int k,x; cin>>k>>x;
h[kp[k]]=x;
up(kp[k]);
down(kp[k]);
}
}
}
散列表 拉链法
维护一个集合,支持如下几种操作:
I x,插入一个数 x;
Q x,询问数 x 是否在集合中出现过
#include <cstring>
#include <iostream>
using namespace std;
const int N = 1e5 + 3; // 取大于1e5的第一个质数,取质数冲突的概率最小 可以百度
//* 开一个槽 h
int h[N], e[N], ne[N], idx; //邻接表
void insert(int x) {
// c++中如果是负数 那他取模也是负的 所以 加N 再 %N 就一定是一个正数131常用
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
bool find(int x) {
//用上面同样的 Hash函数 讲x映射到 从 0-1e5 之间的数
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i]) {
if (e[i] == x) {
return true;
}
}
return false;
}
int n;
int main() {
cin >> n;
memset(h, -1, sizeof h); //将槽先清空 空指针一般用 -1 来表示
while (n--) {
string op;
int x;
cin >> op >> x;
if (op == "I") {
insert(x);
} else {
if (find(x)) {
puts("Yes");
} else {
puts("No");
}
}
}
return 0;
}
散列表也就是仗着1e5+3不出错,进行有节制的控制了存储范围,通过数组下标的跟踪来确定位置
字符串散列表也是,通过char的整数*10^位次总值%M来存储位置,散列表中的拉链法比较容易理解
哈希表散列
// select and founding.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
int main()
{
std::cout << "Hello World!\n";
}
/*查找类型
顺序查找,一般线性表的顺序查找时间复杂度成功(n+1)/2,不成功也就是n+1
有序表的顺序查找,用判定树来作为例子查找成功也就是(n+1)/2,不成功则是n/2+n/(n+1);
折半查找,就是二分法找mid,确定left and right,数组或者结构模拟一样的思维方式查找的次数不会超过树的高度。等价于平衡二叉树且是中序遍历,
等概率的情况下时间复杂度是log2(n+1)-1;适合顺序存储结构,而不是链式,因为不确定性
比如在单链表的数据项时,时间可能为n,主要存储的情况
分块查找时间复杂度在于切割的区块,索引查找时间+块内时间,将顺序查找和折半查找在分块查找融合起来
ASL=(B+1)/2+(S+1)/2=(S^2+2S+N)/2S,顺序
ASL=[log2(b+1)]+(s+1)/2;折半
*/
/*
b树结点关键字(m/2)向上取整-1<=n<=m-1确定b树每一级的存储,上下限用来区分
*/
/*
散列函数,一个把查找表中的不用关键词映射到对应地址的函数,记为hash(key)=address
开放定义地址法,就是数组放开了存,只要令映射不重复就可以了
拉链法是链表的另一种展示情况
*/
typedef int KeyType;
typedef int ValueType;
//哈希函数
typedef int (*HashFunc)(KeyType key);
const int HashMaxSize =50 ;
//键值对的结构体(用链表来处理哈希冲突)
typedef struct KeyValue {
KeyType key;
ValueType value;
struct KeyValue* next;
}KeyValue;
//哈希表
typedef struct HashTable {
KeyValue* data[HashMaxSize]; //哈希表中存放的是链表的头指针
size_t size;
HashFunc func;
}HashTable;
//初始化
void HashInit(HashTable* ht, HashFunc func){
if (ht == NULL)return;
ht->size = 0;
ht->func = func;
size_t i = 0;
for (; i < HashMaxSize; i++) ht->data[i] = NULL;
}
//销毁每个节点的链表 删除讲究的是逻辑性
void _HashDestroy(KeyValue* to_destroy){
KeyValue* cur = to_destroy->next;
free(to_destroy);
if (cur != NULL) _HashDestroy(cur);
}
//创建元素结点(因为是链表存储)
KeyValue* CreateNode(KeyType key, ValueType value){
KeyValue* new_node = (KeyValue*)malloc(sizeof(KeyValue));
if (new_node == NULL)return NULL;
new_node->key = key;
new_node->value = value;
new_node->next = NULL;
return new_node;
}
//插入元素
void HashInsert(HashTable* ht, KeyType key, ValueType value){
if (ht == NULL)return;
if (ht->size >= HashMaxSize * 10)return;
//1.先通过哈希函数求出当前元素在哈希表中的下标 offset
size_t offset = ht->func(key);
//2.在 offset 处头插入新元素,也就是新结点
//3.如果当前链表中存在与插入元素相同的 key 值,则直接返回,插入失败
KeyValue* cur = ht->data[offset];
while (cur != NULL){
if (cur->key == key)return;
cur = cur->next;
}
KeyValue* new_node = CreateNode(key, value);
new_node->next = ht->data[offset];
ht->data[offset] = new_node;
++ht->size;
}
//删除指定元素
void HashRemove(HashTable* ht, KeyType key){
if (ht == NULL)return;
//1.先通过哈希函数求出哈希表的下标 offset
size_t offset = ht->func(key);
KeyValue* prev = NULL;
KeyValue* cur = ht->data[offset];
while (cur != NULL){
//2.在该位置的链表中找到该元素
//3.先保存前一个节点,才能删除当前要删除的结点
if (cur->key == key && prev == NULL){
ht->data[offset] = cur->next;
free(cur);
return;
}
else if (cur->key == key && prev != NULL){
prev->next = cur->next;
return;
}
prev = cur;
cur = cur->next;
}
return;
}
//查找指定元素
KeyValue* HashFind(HashTable* ht, KeyType key)
{
if (ht == NULL)
{
return NULL;
}
//1.先通过哈希函数找到当前 key 在哈希表中的下标
size_t offset = ht->func(key);
//2.找到以后遍历链表,找到就返回,找不到就退出
KeyValue* cur = ht->data[offset];
while (cur != NULL)
{
if (cur->key == key)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
/*
* 在查找运算中,需要对比关键字的次数称为查找长度
ASL查询成功是分配链表的位置层数*分配因子个数合/链表位置个数或者用对比次数合/链表个数,
由于冲突的存在降低了效率,广列法就是O(1)
查询失败是每个点能查到几个合/查找位结点==装填因子a=表中记录数/散列表长度
*/
散列表装填
除数残留法
- 确定残留除余法确定最好选择情况是散列表长度的最大质数,减少发生数据冲突的可能
- 散列表的存储有两种大题考虑形式来计算ASL成功和失败
- 先引入装载因子,α=状态数量/散列表表长
- 如果没有给表长,只给了数量和mod,那表长默认是mod的值,mod11就是11,0-10之间的存放空间
线性
第一种是线性,也就是表从0摆开,用% 算存放在哪里,线性的特点就是,如果存在存储冲突,那么这个点继续向后推,知道遇到空的存放空间,但也有意外,就是全部都冲突了,那就外延mod的空间,比如是mod7存放已经满了,那就新建出14的空间,并且计算出的值如果在之前被鸠占鹊巢了,那也要继续往后延,但是要记录好自己应该的位置。
- ASLsuccessive计算是每个点会被检索次数加和/装载数据的个数,检索不到的话就往后延伸,所以检索次数不一定一定是1
- ASL UNsuccess计算的是划重点
- 查找失败情况下比较的次数,是该元素到其右边第一个空白位置的距离
- 如果在表长未满的情况下,有剩余,这个点也要算是空查找的1次
- 查找失败时比较了多少次呢?这里就要考虑到mod(取模%)的作用了,联系循环队列中的%,%的作用是把rear指针从数组的高位变到了低位使得整个数组循环了起来。
如果一个重点是散列表给了最大表长,遇到存放到满额的话就删掉这个点
例如(其他题拉过来的,mod是13,表长是15)
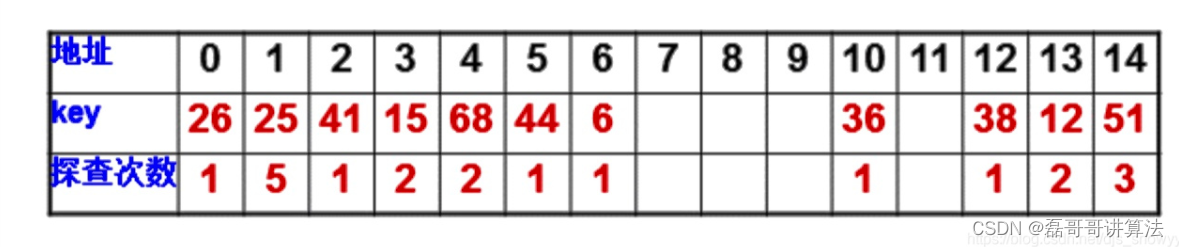
位置12要比较的次数,是其右边的元素个数+从0开始到第一个空白的个数,即位置12,13,14,0,1,2,3,4,5,6,7,共11次。
位置13,14要不要考虑呢?答案是不需要。一个解释方式是通过哈希函数来解释,哪个数字经过哈希函数的映射之后能映射到13或者14?即哪个数字对13取模之后能得到13或者14?这个数字是不存在的,也就是说根本就不存在能够通过哈希函数映射到13或者14的元素,也就不会有查找失败了。 - 最后的分母是模长。
一道例题

查找失败可能对应的地址有7个,比较完0-8号地址才能确定是否存在在表中。
要特别注意的是,散列表不能计算出地址7,所以就变成只计算7个点,而不是一开始的8个数字,分母是模长7,这道题选c
拉链法
也就是遇到冲突后在这个点的基础上外延存储空间,类似于邻接链表的样子。
- ASLsuccessive计算的是查找各个数字需要的次数之和/查找的元素个数
- 所以检索成功与否就是看这个点外延的个数就行,
- 查找成功时,分母为哈希表中元素个数,
- ASLunsuccess计算的是检索失败也就是在点外延了几项
- 外延个数,加和,例如指针点1外延了3个结点,那么就是用3+1去加和
- 查找不成功时,分母为哈希表长度。
- ASLunsuccess另一中算法是要计算空指针,那么就是每一个指针外延+1,加和然后除以长度,空结点也算 ,按照天大书上写的
线性探测法
还是先用hash表的装填方式,如果出现冲突的情况,那么就用hi=(H(key)+di)%表长,di的选择是从冲突次数1往上加
















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











