







入门基础
- string=‘C:\now’ 与string='C:\now’之间的差别
转义反斜杠是对于自身的转义。单个‘\’已经可以转义,双斜杠是为了解决特殊单斜杠遇到的问题
长分行操作就是三组重引号字符串轻松解决问题 
- 代码块实现转译函数
def convert_to_unicode_escape(path):
# 将非ASCII字符转换为Unicode转义序列
path = path.encode('unicode_escape').decode()
return path
- enumerate()生成二元组构成的一个迭代对象,每一个二元组是由可迭代参数的索引号及其对应的元素组成

字符串可以理解为,i与char的关系,类似于c++的iterator: - zip是继之前的元组 列表 字典之后行的新存取
用于返回各个可迭代参数共同组成的元组,可以理解做多组对应元组组合封装在一起

- 字典的使用非常常见,与序列不同,字典更加讲究映射,不讲求顺序,ta的key必须独一无二,value可以重复或者任何数类型,但必须是不可以变的。用大括号申明,可以对比记忆()【】与{}

可以理解为第一组是元组形式的字典,第二组是一一对照的填表式命名 - python独特的shadowing机制,保护全局变量,一旦函数内部视图修改全局变量,python就会在函数内部自动创建一个名字一模一样的局部变量,这样修改的结果只会修改到局部变量,而不会影响到全局变量。如果需要全程传递,那么就需要global,在之前自己写的伽马变换exe可视化界面的是偶,filename需要通过翻转执行全局化操作传递。
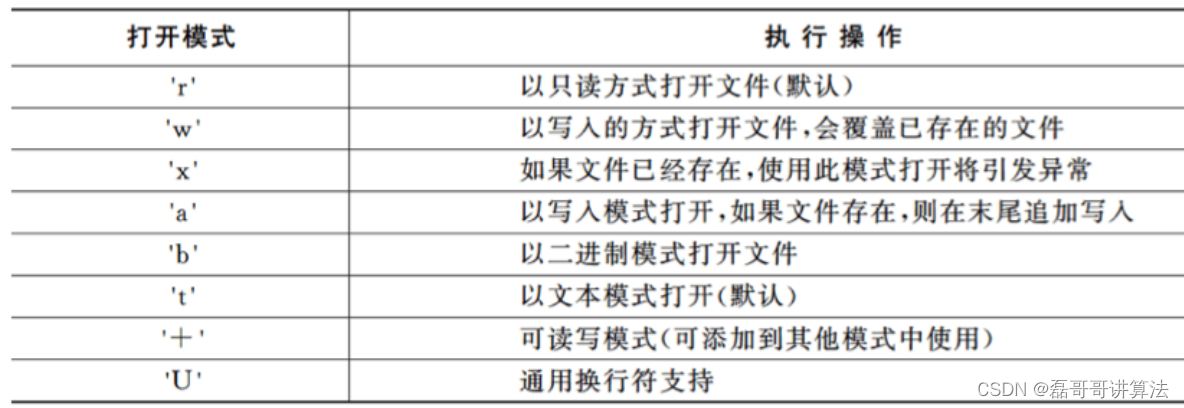
- openfile小技巧 open()这个函数来打开文件

第二组参数的信息
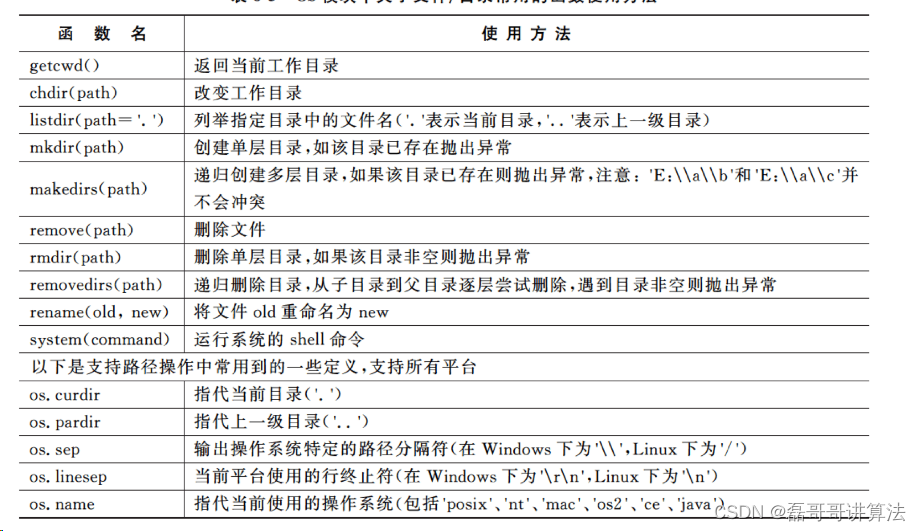
- os模块与cmd异曲同工
机器学习
kNN邻近
先搞一个小插曲,主打一个手搓代码实现,要是直接成为python库里也没办法,respect
from numpy import *
import operator
def createDataset():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.11]])
labels=['A','A','B','B']
return group,labels
def classify0(inx,dataset,labels,k):
datasetsize=dataset.shape[0]
diffmat=tile(inx,(datasetsize,1))-dataset
#在Python中,tile函数是NumPy库中的一个函数,它用于沿指定的轴复制数组的元素。tile函数的作用是将一个数组沿指定的轴重复多次,形成一个更大的数组。
sqdiffmat=diffmat**2
sqdistances=sqdiffmat.sum(axis=1)
# 如果axis为(0, 1),那么将沿着两个维度(行和列)同时进行求和,返回一个标量值。
# 如果axis为(0, ),那么将沿着第一个维度(行)进行求和,即在列的方向上进行求和,返回一个一维数组。
# 如果axis为(1, ),那么将沿着第二个维度(列)进行求和,即在行的方向上进行求和,返回一个一维数组。
distances=sqdistances**0.5
sortedDistIndices=distances.argsort()
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndices[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
# 打开文件
fr = open(filename)
# 按行读取文件
arrayOLines = fr.readlines()
# 得到文件行数
numberOfLines = len(arrayOLines)
# 创建用 0 填充的矩阵
returnMat = zeros((numberOfLines, 3))
# 创建用于存放标签的列表
classLabelVector = []
# 行的索引
index = 0
# 解析文件数据得到列表
for line in arrayOLines:
# 去掉所有回车字符
line = line.strip()
# 将整行数据分割成元素列表
listFromLine = line.split('\t')
# 选取前 3 个元素存储到特征矩阵中
returnMat[index,:] = listFromLine[0:3]
# 将最后一列存储到标签向量中
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
else:
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
def autoNorm(dataset):
minvals=dataset.min(0)
maxvals=dataset.max(0)
ranges=maxvals-minvals
normdataset=zeros(shape(dataset))
m=dataset.shape[0]
normdataset=dataset-tile(minvals,(m,1))
normdataset=normdataset/tile(ranges,(m,1))
return normdataset,ranges,minvals
然后再调用咱们手搓的代码
import kNN
import matplotlib.pyplot as plt
import array
import matplotlib
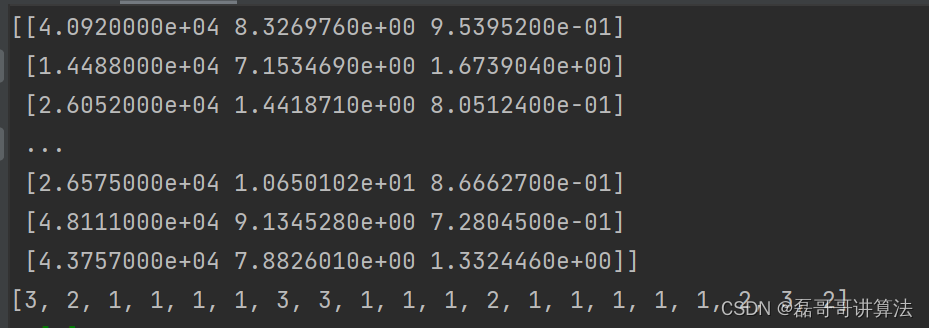
datingDataMat,datingLabels=kNN.file2matrix('datingTestSet.txt')
print(datingDataMat)
print(datingLabels[0:20])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
plt.show()
直接看点集合绘图吧也可以看下前几个数据类型,也可以预防一下数据的大体结构,为之后的处理更加方便

然后是手写数字的python使用KNN识别实现,也是使用手搓的实现代码
实现的思维如下

from os import listdir
import kNN
from numpy import *
import os
import operator
def img2vector(filename):
returnVect=zeros((1,1024))
fr=open(filename)
for i in range(32):
lineStr=fr.readline()
for j in range(32):
returnVect[0,32*i+j]=int(lineStr[j])
return returnVect
def handwriteingClassTest():
hwLabels=[]
trainingFileList=listdir('traningDigits')
m=len(trainingFileList)
trainingMat=zeros((m,1024))
for i in range(m):
filenameStr=trainingFileList[i]
fileStr=filenameStr.split('.')[0]
classnumStr=int(fileStr.split('~')[0])
hwLabels.append(classnumStr)
trainingMat[i,:]=img2vector('trainingDigits/%s'%filenameStr)
testFileList=listdir('testDigits')
errorCount=0.0
mTest=len(testFileList)
for i in range(mTest):
filenameStr=testFileList[i]
fileStr=filenameStr.split('.')[0]
classnumStr=int(fileStr.split('_')[0])
vectorUnderTest=img2vector('testDigits/%s'%filenameStr)
classfileresult=kNN.classify0(vectorUnderTest,trainingMat,hwLabels,3)
print("""the classifier came back with:%d,the real answer is
%d"\%(classfileresult,classnumStr)""")
if(classfileresult!=classnumStr):
errorCount+=1
print("\nthe total number of errors is %d"%errorCount)
print("\nthe total error rate us %f"%(errorCount/float(mTest)))
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











