







国外:
国内篇链接为:国内外大语言模型(LLM)超详细总结与代码实战(可用于面试或学习,持续更新)-----国外篇-CSDN博客
一、GPT 系列
1. GPT-1
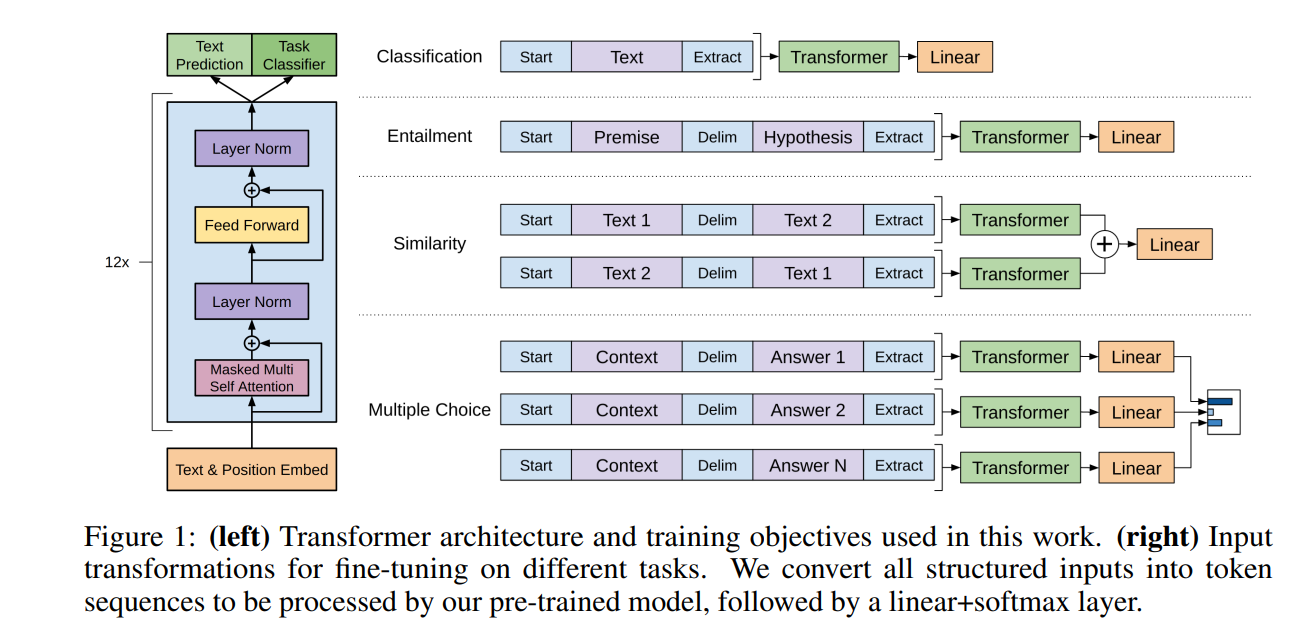
1. 基本用途
-
核心任务:无监督语言建模、文本生成
-
典型应用:
-
文章续写(给定上下文,自动生成后续文本)
-
对话生成(基于历史对话上下文生成回复)
-
2. 工作原理流程
-
输入表示
-
文本首先被拆分成 sub-word tokens(Byte-Pair Encoding),可以兼顾词汇覆盖和稀疏问题。
-
每个 token 被映射为一个高维向量(词嵌入),再加上与其在序列中位置对应的“位置编码”,以注入位置信息。
-
-
自回归 Transformer 解码器
-
Masked Self-Attention
-
每层都会计算序列中每个 token 对之前所有 token 的注意力权重,确保当前 token 只能看到左侧已生成内容,防止“看到未来”信息。
-
Attention 输出与残差连接后进入规范化(LayerNorm)。
-
-
前馈网络(Feed-Forward Network)
-
两层全连接网络,中间通过 GELU 激活函数引入非线性;上下文信息在这一过程中被进一步提炼。
-
同样有残差连接和 LayerNorm,保证梯度稳定与信息流动。
-
-
多层堆叠
-
GPT-1 堆叠了 12 层这样的解码器,每层都在逐步丰富对上下文的建模能力。
-
-
-
文本生成
-
推理时,模型以“起始符”(
<sos>)开始,每一步都将当前已生成的 token 序列输入解码器,预测下一个 token 的分布。 -
生成策略可选最大概率取样(greedy)、束搜索(beam search)或随机采样(top-k/top-p),直到生成结束符为止。
-
3. 完整代码示例
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 为了演示,这里用 GPT-2 small 模型来模拟 GPT-1
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
prompt = "In a distant future,"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=50, do_sample=True)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
2. GPT-2
1. 基本用途
-
核心任务:大规模无监督语言建模
-
典型应用:
-
长文本生成(新闻、故事续写)
-
零样本/少样本下的任务适配
-
2. 工作原理流程
-
架构升级
-
相比 GPT-1,GPT-2 将堆叠层数从 12 增加到 24、36、48(不同规模);隐藏维度、注意力头数也相应放大。
-
上下文窗口扩展至 1,024 token,能够在更长文本中捕捉远距离依赖。
-
-
大规模预训练
-
使用约 40GB 的高质量网页文本进行训练,模型学习到了更加丰富的语言模式与世界知识。
-
-
细节优化
-
增加学习率 warm-up、layer normalization 的位置微调,以及更稳健的优化器设置,提升了训练稳定性。
-
-
生成阶段
-
在解码器每层都沿用 Masked Self-Attention + 跨层残差,保持对长序列的高效建模。
-
同样支持多种生成策略,常见做法是 top-k + top-p 联合控制多样性与流畅度。
-
3. 完整代码示例
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2-xl")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-xl")
prompt = "Once upon a time,"
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(**inputs, max_length=100, top_k=50, top_p=0.95)
print(tokenizer.decode(output[0], skip_special_tokens=True))
3. GPT-3
1. 基本用途
-
核心任务:超大规模语言理解与生成
-
典型应用:
-
会话助手(ChatGPT)
-
编程辅助(Copilot)
-
文本摘要、翻译、问答
-
2. 工作原理流程
-
架构规模
-
参数量达 1750 亿,层数可达 96 层,隐藏维度和注意力头数都大幅提升。
-
支持 2,048 token 的 context window,能处理更长对话和文本。
-
-
自回归生成
-
与前作相同,每一步输入当前已生成序列,更新注意力权重和前馈网络,输出下一 token。
-
-
少样本与零样本提示
-
在提示(prompt)中嵌入少量示例或任务说明,模型无需微调即可完成翻译、问答、分类等任务。
-
-
API 服务化
-
用户通过 REST API 提交 prompt,模型在后端完成推理并返回结果,无需本地部署。
-
3. 完整代码示例(OpenAI API)
import openai
openai.api_key = "YOUR_API_KEY"
response = openai.Completion.create(
model="text-davinci-003",
prompt="Translate to French: 'The weather is nice today.'",
max_tokens=60,
temperature=0.3
)
print(response.choices[0].text.strip())
4. GPT-3.5 / ChatGPT
1. 基本用途
-
核心任务:优化对话生成、指令执行
-
典型应用:
-
多轮对话系统
-
代码生成、文本校对
-
文档摘要与信息检索
-
2. 工作原理流程
-
在 GPT-3 基础上微调
-
行为克隆:先让模型模仿人类标注示例的对话格式。
-
强化学习(RLHF):用人类偏好反馈训练一个奖励模型,引导生成更符合用户意图和安全要求的回复。
-
-
多角色消息格式
-
系统(system)、用户(user)、助手(assistant)分角色输入,模型根据上下文角色切换生成。
-
-
对话管理
-
模型内部维护对话历史,结合当前用户输入决定下一步生成内容。
-
-
安全与对齐
-
在生成前后会有检测和过滤机制,避免输出有害或敏感内容。
-
3. 完整代码示例(Chat Completions)
import openai
openai.api_key = "YOUR_API_KEY"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum entanglement simply."}
]
)
print(response.choices[0].message["content"])
5. GPT-4
1. 基本用途
-
核心任务:更强的推理与多模态理解
-
典型应用:
-
图文问答(上传图片生成解释)
-
复杂指令执行(数学求解、代码编写)
-
专业领域咨询
-
2. 工作原理流程
-
架构改进
-
在标准 Transformer 基础上,加入跨模态融合层,能够同时处理文本和图像。
-
参数量和内部连接模式均有所优化,但官方未全部开源细节。
-
-
多模态输入处理
-
图像编码:先用视觉编码器(如改进版 ViT)将图像转为向量;
-
文本编码:与之前相同的文本嵌入 + 位置编码;
-
联合注意力:在解码器或特定融合层中同时对图像和文本 Key/Value 做注意力计算,从而跨模态交互。
-
-
增强推理能力
-
采用更深的注意力模式以及更大的 context window(最高 32K token),可以处理超长文档和复杂逻辑链条。
-
-
安全策略
-
集成更严格的内容审核与对话跟踪机制,适合高风险场景。
-
3. 完整代码示例(多模态示例)
import openai
from PIL import Image
import base64
openai.api_key = "YOUR_API_KEY"
with open("diagram.png", "rb") as f:
img_b64 = base64.b64encode(f.read()).decode()
response = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You can see images."},
{"role": "user", "content": "What does this diagram illustrate?"},
],
images=[{"data": img_b64}]
)
print(response.choices[0].message["content"])
二、BERT 系列
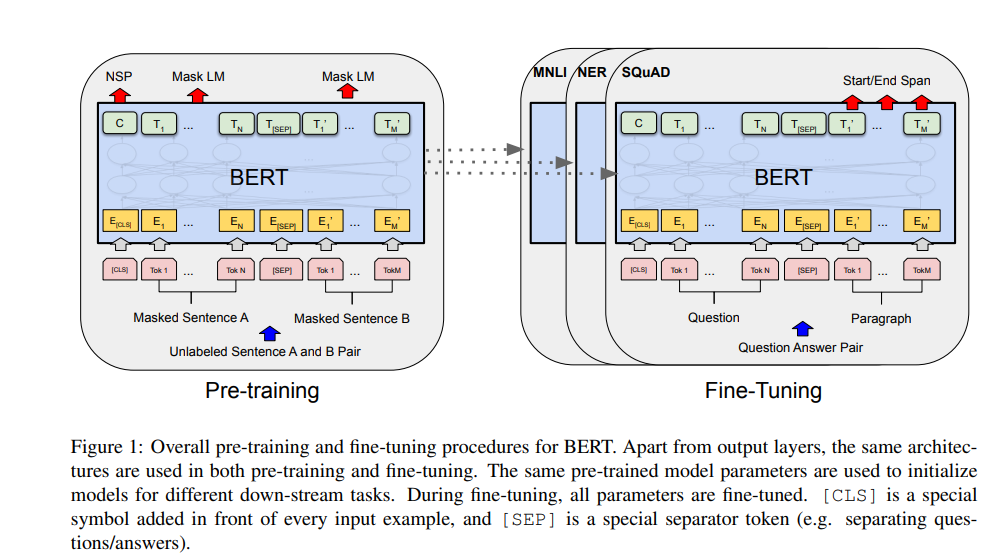
1. BERT-base
1. 基本用途
-
核心任务:双向掩码语言建模(Masked LM),下游任务微调
-
典型应用:
-
文本分类(情感分析、主题分类)
-
命名实体识别(NER)
-
问答(SQuAD、机器阅读理解)
-
2. 工作原理流程
-
输入表示
-
将整句文本切分为 WordPiece tokens,并在句首/句尾分别添加特殊标记
[CLS]、[SEP]。 -
每个 token 对应一个词嵌入(token embedding)、一个段落嵌入(segment embedding),再加上位置编码,一起输入模型。
-
-
双向 Transformer 编码器
-
多头自注意力:在每一层,所有 tokens 相互交换信息,既能看到左文也能看到右文;不同头负责关注不同类型的依赖关系。
-
前馈网络:对每个 token 的自注意力输出做两层全连接和 GELU 激活,提升表达能力。
-
残差连接 + LayerNorm:每一步都有残差通路和层归一化,保证梯度稳定。
-
层级堆叠:BERT-base 堆叠 12 层,层层递进地抽象句子语义。
-
-
预训练任务
-
Masked LM:随机掩码 15% 的 token,用上下文去预测被掩码的词。
-
Next Sentence Prediction(NSP):给定两句话,判断第二句话是否紧跟第一句话。
-
-
下游微调
-
在预训练基础上,针对不同任务加上少量特定头(classification head、span head),再用标注数据做几轮微调即可。
-
3. 完整代码示例
from transformers import BertTokenizer, BertForMaskedLM
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForMaskedLM.from_pretrained("bert-base-uncased").to("cuda")
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt").to("cuda")
with torch.no_grad():
logits = model(**inputs).logits
mask_index = (inputs.input_ids[0] == tokenizer.mask_token_id).nonzero(as_tuple=True)[0].item()
pred_token_id = logits[0, mask_index].argmax(dim=-1).item()
print("Predicted token:", tokenizer.decode([pred_token_id]))
2. BERT-large
1. 基本用途
-
核心任务:与 BERT-base 相同,但更强表示能力
-
典型应用:相同任务下精度提升,尤其在长文本理解和复杂问答中表现更佳
2. 工作原理流程
-
结构升级
-
层数从 12 → 24,隐藏维度从 768 → 1024,注意力头数从 12 → 16。
-
更深更宽的网络学习更细粒度的语言模式和长距离依赖。
-
-
训练与预训练
-
使用相同比例的掩码 LM 和 NSP 任务,但用更多数据、更长的训练时间来提升性能。
-
-
微调策略
-
对于资源受限场景,可先冻结前 N 层,只微调上层及任务特定 head,再逐步解冻。
-
3. 完整代码示例
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
model = BertForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
# 微调示例:二分类
text = "This movie was fantastic!"
inputs = tokenizer(text, return_tensors="pt").to("cuda")
with torch.no_grad():
logits = model(**inputs).logits
print("Positive prob:", torch.softmax(logits, dim=-1)[0,1].item())
三、T5 系列
1. T5-base
1. 基本用途
-
核心任务:统一“文本到文本”框架,将各种 NLP 任务都转化为条件生成
-
典型应用:
-
翻译(translate English to German: …)
-
文本摘要(summarize: …)
-
问答(question: … context: …)
-
2. 工作原理流程
-
Seq2Seq 架构
-
编码器:将输入前缀 + 文本一起编码,捕捉整段上下文。
-
解码器:根据编码器输出和已生成序列自回归地生成目标文本。
-
-
任务前缀设计
-
在输入前添加任务说明,比如 “translate English to German: ”,模型根据提示切换能力。
-
-
预训练与微调
-
在 C4 大规模通用语料上预训练多种任务混合目标;
-
下游只需换 prefix、换输出格式,微调代价低。
-
-
生成策略
-
支持 beam search、top-p/top-k 采样,既可追求准确度也可兼顾多样性。
-
3. 完整代码示例
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
tokenizer = T5Tokenizer.from_pretrained("t5-base")
model = T5ForConditionalGeneration.from_pretrained("t5-base").to("cuda")
# 翻译示例
input_text = "translate English to German: How are you?"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
outs = model.generate(**inputs, max_length=40)
print("German:", tokenizer.decode(outs[0], skip_special_tokens=True))
# 摘要示例
input_text = "summarize: The quick brown fox jumps over the lazy dog."
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
outs = model.generate(**inputs, max_length=30)
print("Summary:", tokenizer.decode(outs[0], skip_special_tokens=True))
四、LLaMA 系列
1. LLaMA-1
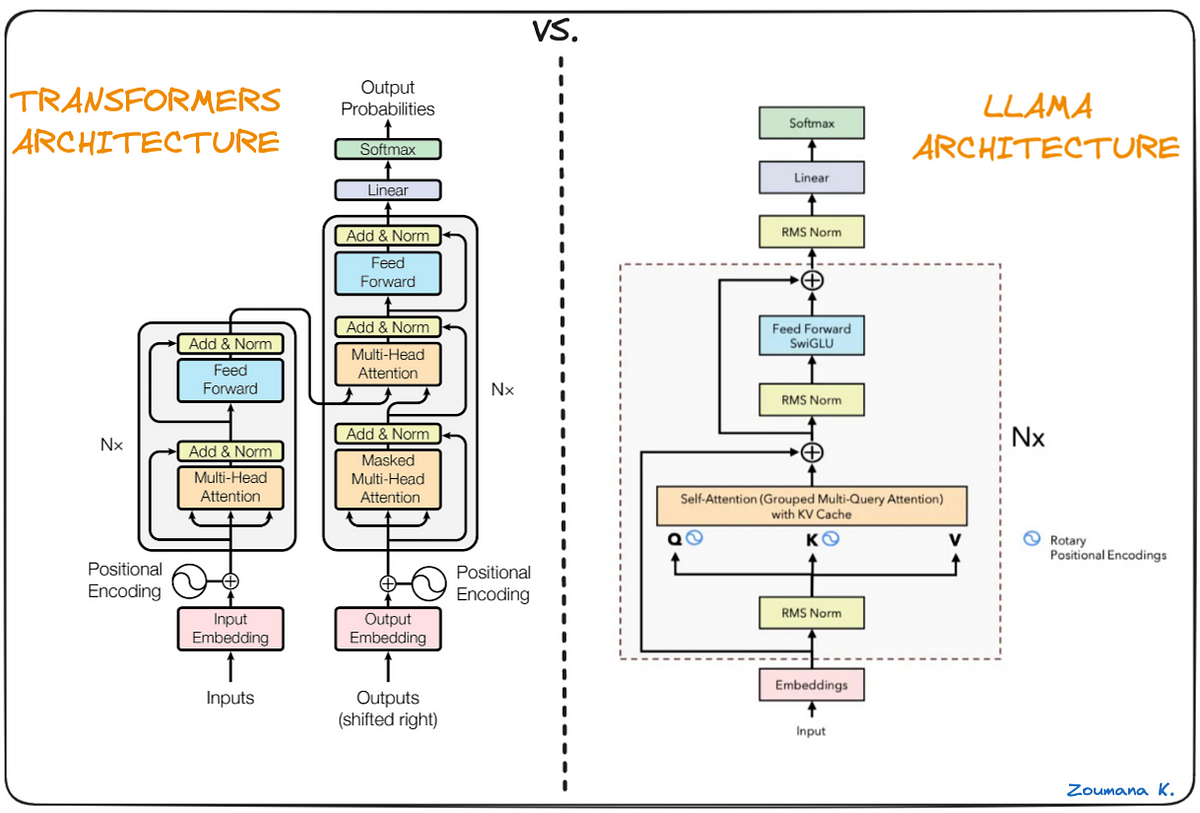
1. 基本用途
-
核心任务:开源高效自回归语言建模
-
典型应用:通用文本生成、研究基线
2. 工作原理流程
-
数据准备与预处理
-
汇集 CommonCrawl、书籍、维基、论坛等多源高质量文本;
-
对原始文本做语言检测、去重、长短文本均衡采样;
-
使用 SentencePiece 学习统一的 sub-word 分词器,既能覆盖罕见词也能保持处理速度。
-
-
模型架构
-
多层自回归解码器:每层结构──
-
Masked Multi-Head Self-Attention:
-
将每个 token 的嵌入映射为 Q/K/V 矩阵;
-
通过掩码确保位置 i 只能 attend 到 ≤ i 的位置;
-
多头并行;最后拼接并投影回隐藏维度。
-
-
前馈网络:两个线性层夹在 GELU 激活之间,逐 token 独立运算;
-
LayerNorm + 残差连接:Attention 和 FFN 之后各自跟残差与归一化,保证深层网络可训。
-
-
LLaMA-1 提供 7B/13B/33B/65B 几种规模,层数与头数随之线性扩展。
-
-
高效训练细节
-
混合精度训练:FP16 + 动态损失缩放,减少显存占用;
-
梯度累积:利用累积实现大 batch size;
-
分布式并行:Tensor Parallel + Pipeline Parallel,跨 GPU/节点拆分模型和数据;
-
优化器与调度:AdamW + cosine learning‐rate decay,线性 warm-up。
-
-
推理优化
-
FlashAttention:内存高效的 Attention 实现,降低显存峰值;
-
KV 缓存:在自回归解码中缓存前面所有层的 K/V,不重复计算;
-
并行解码:对超长生成可跨设备同时扩展;
-
-
生成流程
-
用户输入 prompt,经 tokenizer 转为 token IDs;
-
Embedding + 位置编码 → 一层层解码器运算(Attention + FFN);
-
每步输出 logits,经 softmax 得到下一个 token 分布;
-
采样策略(greedy/beam/top-p)选 token,加入序列,重复直至 EOS。
-
3. 完整代码示例
from transformers import LlamaTokenizer, LlamaForCausalLM
import torch
model_name = "meta-llama/Llama-1-7b"
tokenizer = LlamaTokenizer.from_pretrained(model_name)
model = LlamaForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
prompt = "Once upon a time,"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(**inputs, max_new_tokens=50, do_sample=True, top_p=0.9)
print(tokenizer.decode(gen[0], skip_special_tokens=True))
2. LLaMA-2
1. 基本用途
-
核心任务:开源对话与指令微调,提升多轮交互质量
-
典型应用:AI 助手、知识问答、编码辅助
2. 工作原理流程
-
基础预训练
-
沿用 LLaMA-1 的数据管道与大规模自回归训练;
-
加入更严格的去重和低质量过滤,提升预训练文本质量。
-
-
指令微调(Instruction Tuning)
-
构建数十万条“提示→完成”对:包括问答、摘要、翻译、代码等多任务;
-
用监督学习让模型学会根据提示产出更符合人类期望的格式和内容。
-
-
对话微调(Chat Tuning)
-
在清洗后的多轮对话数据集上进一步训练,使模型学会保持上下文连贯性、角色切换;
-
每轮对话保留系统/用户/助手角色标签,模型内部根据标签动态调整注意力分布。
-
-
安全与对齐
-
引入简单规则过滤器对抗暴力、色情、仇恨等;
-
结合少量人类反馈的优劣打分,微调一个轻量级评价器,在生成后筛选候选回复。
-
-
推理时序
-
格式化 Prompt:将对话历史拼成
"system:…\nuser:…\nassistant:…\n"; -
Tokenize → Embedding → 解码器层:同 LLaMA-1,但解码器中自注意力会优先关注最新用户提问;
-
缓存机制:对话每生成一轮,KV 缓存再利用,保障多轮对话效率;
-
生成与后处理:输出候选后再经过安全过滤,剔除不合规或不连贯回答。
-
3. 完整代码示例
from transformers import LlamaTokenizer, LlamaForCausalLM
import torch
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = LlamaTokenizer.from_pretrained(model_name)
model = LlamaForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the theory of relativity simply."}
]
prompt = "".join(f"{m['role']}: {m['content']}\n" for m in messages)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(**inputs, max_new_tokens=150, do_sample=True, top_p=0.95)
print(tokenizer.decode(gen[0], skip_special_tokens=True))
五、BLOOM
1. BLOOM
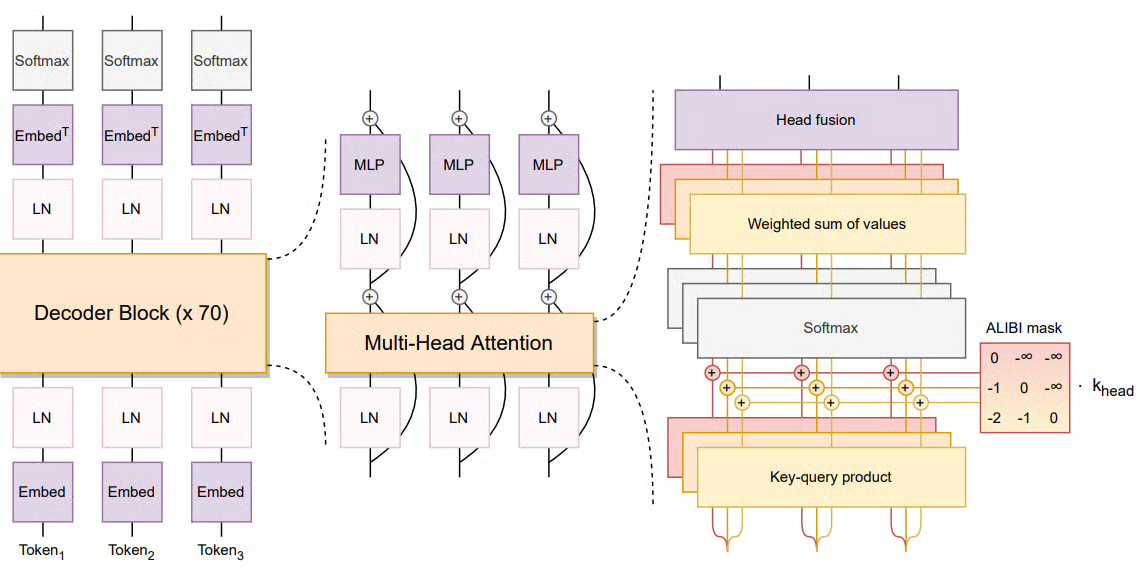
1. 基本用途
-
核心任务:多语种、大规模开源文本生成
-
典型应用:跨语言翻译、代码生成、对话系统
2. 工作原理流程
-
多语种大规模预处理
-
汇集 46 种语言、1,000+ 编程语言的海量语料;
-
按区域和语言分布做平衡采样,防止高频语种过拟合;
-
对代码文本做语法检查、缩进标准化;对自然语言做去重与长度剪裁。
-
-
解码器架构
-
Layer 架构与 GPT 类似:Masked Multi-Head Self-Attention → FFN → 残差 + LayerNorm;
-
参数并行:每层 Attention/QKV/输出投影在模型并行下拆分到不同设备;
-
稀疏专家(Mixture-of-Experts)(大模型版本中可选):部分 FFN 分支只对部分 token 激活,提高参数利用率。
-
-
训练优化
-
Megatron-DeepSpeed:结合 NVIDIA Megatron 和 Microsoft DeepSpeed,实现亿级参数高效并行训练;
-
动态批次与序列拼接:可变序列长度拼接,最大化 GPU 利用率;
-
梯度检查点:减半显存占用,允许更深层数训练。
-
-
推理与生成
-
并行解码:同 LLaMA-1 KV 缓存与 FlashAttention 思路;
-
多语种自适应采样:根据不同语种分布,动态调整 top-k/top-p 超参,保证低频语言生成质量;
-
专家路由(若启用 MoE):每个 token 会根据路由器分配到少数专家子网络,仅这些子网参与该 token 的 FFN 运算,减少计算量。
-
-
应用部署
-
可部署为 HuggingFace Pipeline、ONNX Runtime 或定制化 C++ 服务;
-
支持 CPU/GPU/TPU 后端,并可通过 Triton Inference Server 横向扩展。
-
3. 完整代码示例
from transformers import BloomTokenizerFast, BloomForCausalLM
import torch
tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom")
model = BloomForCausalLM.from_pretrained("bigscience/bloom", torch_dtype=torch.float16, device_map="auto")
prompt = "Hello, world! Translate to French:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
gen = model.generate(**inputs, max_new_tokens=50, top_p=0.9)
print(tokenizer.decode(gen[0], skip_special_tokens=True))

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









