






利用K近邻(回归)KNeighborsRegressor进行回归训练并预测
说明:本文仅个人学习记录,欢迎批评指正
关于K近邻回归
k近邻有分类也有回归,其实两者原理一样:
- 定量输出是回归,进行预测比如明天的降水概率
- 定性输出是分类,需要定性的描述
kNN回归的原理:
- 通过找出一个样本的k个最近邻居,将这些邻居的某个(些)属性的平均值赋给该样本,就可以得到该样本对应属性的值。
关于sklearn内建boston数据集
- 类型是sklearn.utils.Bunch类型
- 13个特征(feature)每个特征506条记录 (506,13)
#导入数据集
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)
X = boston.data
y = boston.target
#(506,13)
选择合适的几个特征
样本一共有 13 个特征,建立模型时可以纳入全部特征也可以只纳入部分,我们选择后者。
不是所有的特征都对数据分析有利,这里通过sklearn内建函数筛选指定的k个有利特征,这里选择k=5:
from sklearn.feature_selection import SelectKBest,f_regression
#筛选和标签最相关的k=5个特征
selector = SelectKBest(f_regression,k=5)
X_new = selector.fit_transform(X,y)
#print(X_new.shape)
#print(selector.get_support(indices=True).tolist())#查看最相关的是哪几列
#(506, 5)
#[2, 5, 9, 10, 12] 里面竟然有黑人比例,而且是最高的影响因素……
关于SelectKBest,看起来非常厉害的函数实际上只是帮着做了计算的工作,至于选什么评分函数进行训练,k为几都需要自己来
比如回归可以使用这里的f_regression,分类可以使用chi2等等
*关于使用到的方法:
- fit(X,y),在(X,y)上运行记分函数并得到适当的特征。
- fit_transform(X[, y]),拟合数据,然后转换数据。
- 经过测试,k=3或者4时效果比较好,k值多了之后可能会不利于模型的泛化
这里选择了5是为了课设任务
划分数据集
from sklearn.model_selection import train_test_split
#划分数据集
X_train,X_test,y_train,y_test = train_test_split(X_new,y,test_size=0.3,random_state=666)
#print(X_train.shape,y_train.shape)
*关于train_test_split函数:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(X,y,test_size, random_state)- 该函数将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
- 参数解释:
X:被划分的样本特征集
y:被划分的样本标签
test_size:如果是浮点数,在0-1之间,表示测试集占比;如果是整数的话就是样本的数量
random_state:是随机数的种子。 - link函数详解
数据预处理
from sklearn.preprocessing import StandardScaler
#均值方差归一化
standardscaler = StandardScaler()
standardscaler.fit(X_train)
X_train_std = standardscaler.transform(X_train)
X_test_std = standardscaler.transform(X_test)
*关于standardscaler:
- 去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本
- 转换公式:z = (x - u) / s
- 尝试不进行标准化,结果也影响不大
进行训练
from sklearn.neighbors import KNeighborsRegressor
#训练
kNN_reg = KNeighborsRegressor()
kNN_reg.fit(X_train_std,y_train)
预测结果
#预测
y_pred = kNN_reg.predict(X_test_std)
评价和展示
1、评价
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print(np.sqrt(mean_squared_error(y_test, y_pred)))#计算均方差根判断效果
print(r2_score(y_test,y_pred))#计算均方误差回归损失,越接近于1拟合效果越好
#结果:
#4.281592178027628
#0.7430431315779586
2、绘图展示
import numpy as np
import matplotlib.pyplot as plt
#绘图展示预测效果
y_pred.sort()
y_test.sort()
x = np.arange(1,153)
Pplot = plt.scatter(x,y_pred)
Tplot = plt.scatter(x,y_test)
plt.legend(handles=[Pplot,Tplot],labels=['y_pred','y_test'])
plt.show()
绘图结果:
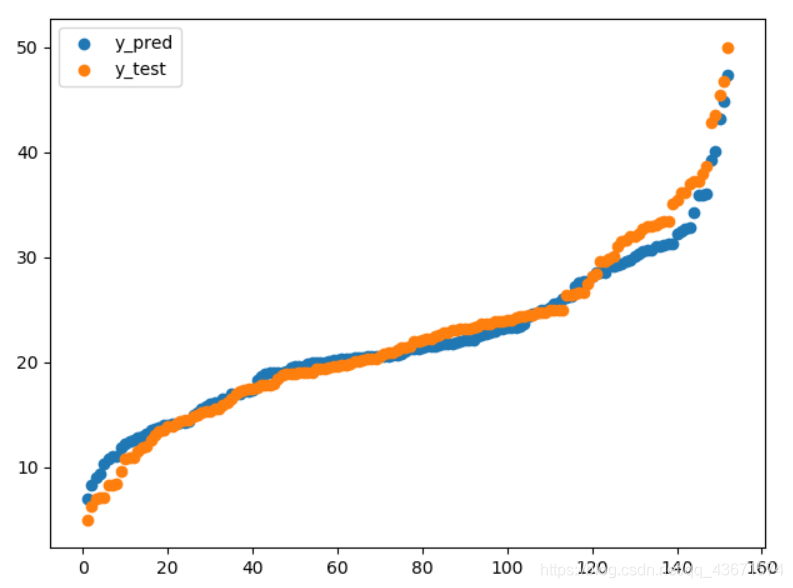
发现结果已经不错了
全部代码展示如下:
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.datasets import load_boston
from sklearn.feature_selection import SelectKBest,f_regression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
#加载数据集
boston = load_boston()
print(boston.data.shape)#boston是sklearn.utils.bunch类型,里面有data506行13列
X = boston.data
y = boston.target
#筛选和标签最相关的k=5个特征
selector = SelectKBest(f_regression,k=4)
X_new = selector.fit_transform(X,y)
print(X_new.shape)
print(selector.get_support(indices=True).tolist())#查看最相关的是那几列
#划分数据集
X_train,X_test,y_train,y_test = train_test_split(X_new,y,test_size=0.3,random_state=666)
#print(X_train.shape,y_train.shape)
#均值方差归一化
standardscaler = StandardScaler()
standardscaler.fit(X_train)
X_train_std = standardscaler.transform(X_train)
X_test_std = standardscaler.transform(X_test)
#训练
kNN_reg = KNeighborsRegressor()
kNN_reg.fit(X_train_std,y_train)
#预测
y_pred = kNN_reg.predict(X_test_std)
print(np.sqrt(mean_squared_error(y_test, y_pred)))#计算均方差根判断效果
print(r2_score(y_test,y_pred))#计算均方误差回归损失,越接近于1拟合效果越好
#绘图展示预测效果
y_pred.sort()
y_test.sort()
x = np.arange(1,153)
Pplot = plt.scatter(x,y_pred)
Tplot = plt.scatter(x,y_test)
plt.legend(handles=[Pplot,Tplot],labels=['y_pred','y_test'])
plt.show()
优化:使用网格搜索优化模型
from sklearn.model_selection import GridSearchCV
#尝试使用网格搜索优化
param_grid = [{'weights':['uniform'],
'n_neighbors':[k for k in range(1,8)]
},
{'weights':['distance'],
'n_neighbors':[k for k in range(1,8)],
'p':[p for p in range(1,8)]
}
]
kNN_reg = KNeighborsRegressor()
grid_search = GridSearchCV(kNN_reg,param_grid=param_grid)
grid_search.fit(X_train_std,y_train)
kNN_reg = grid_search.best_estimator_
y_pred = kNN_reg.predict(X_test_std)
print(np.sqrt(mean_squared_error(y_test, y_pred)))#计算均方差根判断效果
print(r2_score(y_test,y_pred))#计算均方误差回归损失,越接近于1拟合效果越好
#结果并不好,以后再来调整:
#10.913353790790158
#-0.6694218869887143
第一次机器学习模型尝试,冲冲冲!

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









