







一、原YOLOv3模型
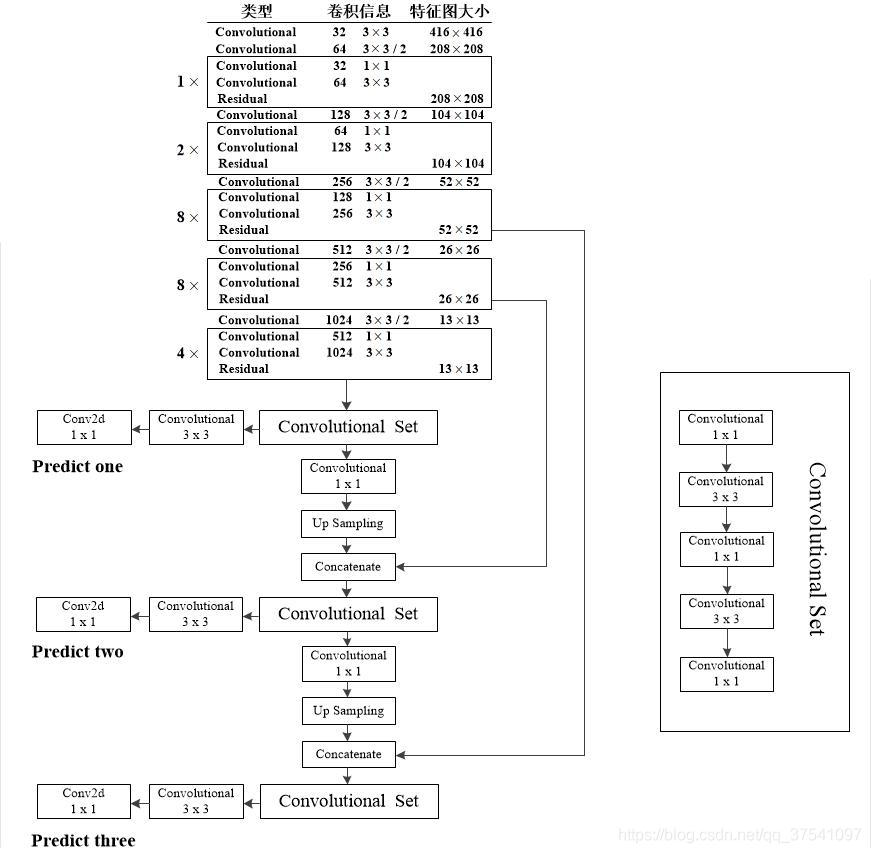
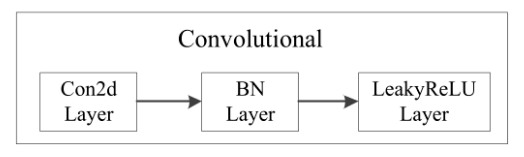
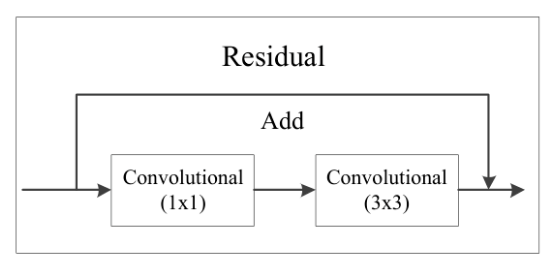
Predict 1输入尺寸是13×13;
Predict 2输入尺寸是26×26;
Predict 3输入尺寸是52×52;
尺寸越大,可预测的物体越小。
二、正样本匹配
anchor box 包含类别信息,以及与真实边界框的偏移量。训练时生成多个anchor box,一般是对训练样本进行聚类得到的。
针对每一个feature map:
(1)将每个gt box与每个anchor box根据交并比(IoU)进行匹配,得到标签(one-hot)、偏移量(4个)、标注(匹配为1);
(2)如果gt与某个anchor模板的IoU大于给定的阈值,则将gt分配给该anchor模板;
(3)将gt投影到对应预测特征层上,根据gt的中心点定位到对应cell,则该cell对应的anchor box为正样本。
三、Mosaic图像增强
将4张图片按照一定比例拼接在一起进行训练,提高batch size,提升小目标的检测性能。拼接方法有很多,如:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过尺寸比例调整后,放置在指定尺寸图的四个顶点位置。
(3)图片分割,对大图进行拼接。
(4)处理超过边界的检测框坐标。
四、SPP模块
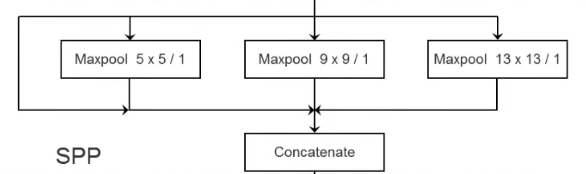
在predict之前的convolutional set中间插入spp模块,实现不同尺度的特征融合。
五、损失函数
(1)loc:计算正样本的定位损失CIoU
IoU、GIoU、DIoU、CIoU:https://zhuanlan.zhihu.com/p/94799295
(2)cls:正样本分类损失:bce loss
(3)obj:预测框中是否有目标
加权求和。
代码:https://github.com/ultralytics/yolov3















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









