







自我介绍:
您好,我们是一群热情洋溢的探索者,致力于深耕于知识图谱和大型语言模型(LLM)领域。我们的目标是挖掘、分析并分享那些能够启迪思维、推动科学进步的优质学术论文。我们坚信,知识的传播和交流是促进创新和社会发展的关键力量。
论文标题
KM-BART: Knowledge Enhanced Multimodal BART for Visual
Commonsense Generation
KM-BART:用于视觉常识生成的知识增强多模态BART
论文发表
ACL 2021
论文链接
https://aclanthology.org/2021.acl-long.44/
论文代码
https://github.com/fomalhautb/KM-BART
作者
Yiran Xing , Zai Shi , Zhao Meng ,Gerhard Lakemeyer , Yunpu Ma ,Roger Wattenhofer
RWTH Aachen, GermanyLMU Munich, Germany ETH Zurich, Switzerland
论文背景
视觉语言模型的早期工作主要集中在纯粹的理解任务上。这些模型虽然在理解任务(如视觉问答)方面提高了模型性能,但却无法完成多模态生成任务。为了缓解这一问题,研究人员提出了各种模型,用于基于视觉输入生成文本。这些模型主要在一般的视觉和语言理解任务上进行预训练,如掩码语言建模和掩码区域建模,使模型能够构建一个完整的模型。仅靠特征对齐不足以提高模型进行复杂的多模态常识推理的能力,需要模型理解对象之间的潜在关系和效果。
问题分析
常识推理传统上是在自然语言上研究的,而最近的作品则关注了具有联合视觉和语言输入的常识性推理。提出了视觉常识推理(VCR)的任务。然而,该任务侧重于理解而不是生成,因为它要求模型回答多项选择题。新引入的数据集,视觉常识生成(Visual Commonsense Generation, VCG),旨在推动模型发展,使其能够生成关于场景中潜在的前因后果以及角色当前行为意图的深层次常识性推断。
视觉语言任务(VL),如视觉问答(VQA)和图像-文本匹配这些都要求模型处理多模态输入并同时理解视觉和文本信息,这些多模态预训练模型使用transformer作为主干,并且是经过训练的去噪自编码器,用于预测图像文本对的对齐以及被屏蔽词和图像区域的语义。上面这些模型更侧重于理解任务,除了跨模态理解之外,模型还应该获得完成生成任务的能力。然而,直接将在VL理解任务上预训练的模型转移到生成任务是不可行的,因为这些模型仅仅是基于transformer的编码器,因此不适合生成任务。
相关概念
常识知识是指对大多数人常见的日常情况和事件的必要水平的实践知识和推理。例如,人们应该知道“水是用来喝的”和“阳光使人温暖”。虽然看起来很简单,但对于基于学习的模型来说,使人工智能能够进行常识性推理一直很困难。图的天然特性,可以很好的存储常识性知识,但基于图的方法需要大量的人力工程,这就使得它难以扩展。因此,作者使用COMET推断的监督信号隐式地利用外部知识,COMET是基于transformer的生成模型,在常识知识图(包括ConceptNet和Atomic)上进行预训练。给定一个自然语言短语和一个关系类型,COMET生成自然语言常识性描述。
ConceptNet:是一个知识图,节点表示一般概念,边表示概念之间的关系知识。另一个常识性知识图ATOMIC (Sap等人,2019)将节点扩展到自然语言短语,并将边缘扩展到意图、归属、效果等关系。
理论方法
KM-BART组成:KM-BART是一个基于变压器的模型,由一个编码器和一个解码器组成,并在精心设计的VCG任务上进行预训练。
模型架构:
模型主干是一个BART,通过修改原来的BART,使模型适应图像和文本的交叉模态输入,通过添加特殊的token使得模型适应不同的预训练/评估任务。模型主要分三部分:1.视觉特征提取器2.编码器3.解码器。
1.视觉特征提取器
作者使用预训练的Masked R-CNN,对每张图片进行物体边界框提取。边界框内部的区域是感兴趣的区域(rol)。作者利用Masked R-CNN中的rol中间表示(就是中间特征值)来获得固定大小的rol嵌入V = {v1,…, vi,…, vN},其中i为roi的索引,N为一张图像的roi个数。第i个RoI vi的视觉嵌入为vi∈Rd,其中d为嵌入维数。对于每个roi,Masked R-CNN也输出类分布p(vi),稍后用于Masked区域建模。

上图person1,person2和book都是识别到的物体,其边框的内部就是感兴趣的区域(rol),这个编码器就是固定获得图像有意义物体的嵌入(特征)。
2.编码器
跨模态编码器:作者先引入特殊的token来标记预训练和下游评估任务。每个示例都以一个特殊的token开始,该token指示当前示例的任务类型。
对于基于知识的常识生成的预训练任务,使用 < b e f o r e > , < a f t e r > <before>, <after> <before>,<after>或 < i n t e n t > <intent> <intent>作为起始特殊标记。
对于归因预测和关系预测,使用 < r e g i o n c a p t i o n > <region caption> <regioncaption>。
最后,对于遮罩语言建模和遮罩区域建模,使用 < c a p t i o n > <caption> <caption>。
此外,为了告知模型输入的不同模式,添加了三组不同的特殊标记:对于图像,分别使用 < i m g > 和 < / i m g > <img>和</img> <img>和</img>来表示视觉嵌入的开始和结束。对于文本,引入了不同的特殊标记来区分两组文本输入:事件和标题。事件是模型用于推理未来/过去事件或常识生成任务中字符当前意图的图像描述,而标题是用于掩码语言建模的,其中语言信息起着更重要的作用。
因此,为了告知模型这两种类型的文本输入,使用 < e v e n t > 和 < / e v e n t > <event>和</event> <event>和</event>表示事件,使用 < m l m > 和 < / m l m > <mlm>和</mlm> <mlm>和</mlm>表示标题。在下面的部分中,我们用W = {w1, …, wT}来表示单词和特定标记的文本输入其中T是文本输入的长度。对于token w,它的嵌入是e∈Rd,其中d是嵌入的维数。
上面这个部分可以比较难以理解,没关系看到下面这个图就会好理解很多:
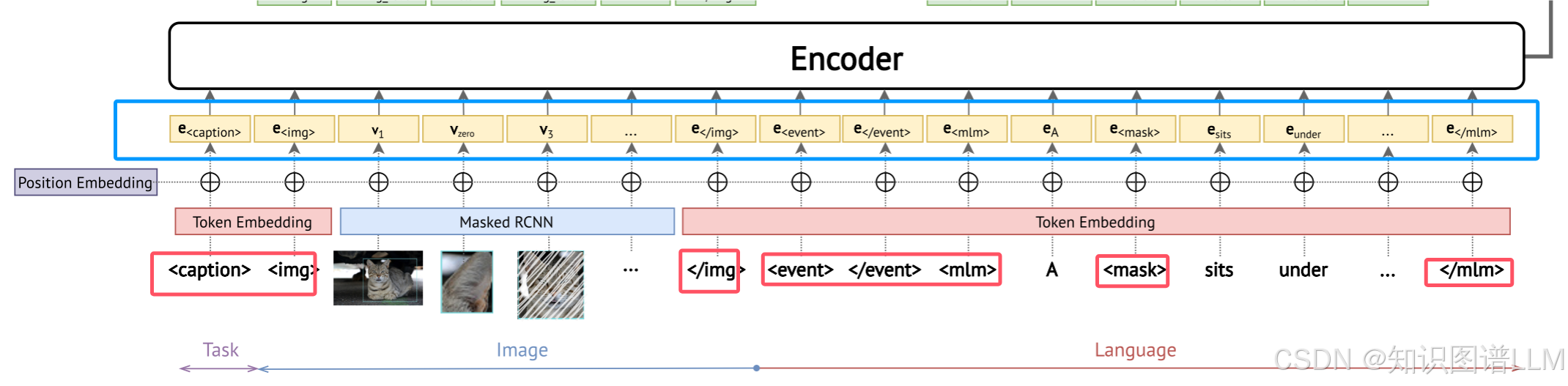
上面弄了一大堆特殊的标记,其实告诉模型,具体每个阶段的token是含义的token。譬如,Task,Image,Language。这个在NLP领域应该都知道是什么意思。在红色的框框内。至于蓝色的,我觉得就是token w 。PS:希望可以有大神告诉我那个w是什么
3.解码器
模型是一个多层的transformer,编码器是双向的,但解码器是单向的。解码器不把视觉嵌入作为输入。相反,使用特殊标记 < i m g f e a t > <img_feat> <img
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









