







前言
本文主要记录下关于斯坦福CS231n课程Lecture1——Lecture5中学习的笔记,以下部分内容为个人理解如有错误,敬请原谅。
一、传统机器学习和深度学习联系
不管是传统的机器学习还是深度学习,贯穿主线的就是特征,只不过传统的机器学习能够利用数学建模的方式将特征展现出来并推导分析,而深度学习更像是黑匣子其中的特征更加的抽象难懂无法直观地呈现出来,并且从数学上较难去推导分析;但是两者共同点都是需要数据驱动,现在地深度学习能更好地利用大数据进行训练寻找特征,以往传统机器学习难以解决的问题,放在深度学习能够高效的完成,就拿物体分类来说传统的机器学习个人认为难以在高维空间上进行数据的建模,而深度学习能很好地胜任,这样使得很多情况下物体分类的分类器能更加具有弹性能更好地拟合或是学习到真实数据的分布情况。
二、KNN
KNN最近邻算法应该是机器学习中最经典和简单的分类算法,主要用于分类和回归,属于监督学习,其主要原理是计算一个样本在特征空间中K个最相似的样本属于的类别,并将该样本归属于该类别,其中样本之间距离公式一般使用L1或L2距离公式。

三、SVM损失函数和SoftMax损失函数
SVM损失函数:在多分类情况下,SVM损失函数公式如下:
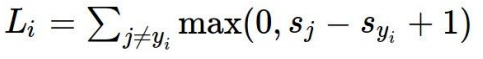

softmax损失函数:softmax较为简单,softmax实际上就是logistic的扩展,后者只能二分类,前者则能多分类,实际上都是返回每一类的概率值,在多分类应用时就是获得输出概率最大的即可
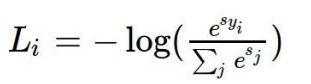
四、正则化
正则化的主要目的是为了防止过拟合现象,其使用主要在损失函数末尾如公式所示:
直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是网络深度却很深,它会使这个网络从过度拟合的状态更接近高偏差状态。

五、优化方法
梯度下降法:梯度下降法是深度学习中必不可少十分重要的一步,梯度下降法的目的很简单,找到最优点,在数学模型上就是转换成求最小值即谷底,如图所示利用梯度即导数和步长逐步找到最小值点:
如下图是随机梯度下降法的基本流程
当然目前随机梯度下降法早已得到改进,有基于动量的梯度下降和基于加速度的梯度下降等。


六、激活函数
个人认为激活函数的目的主要是为了使得网络能够具有非线性能力,能够使得网络拟合数据,如果没有激活函数只有单纯的连接,那么网络不管怎么构建都只是一个线性网络,这样的神经网络就失去了它最本质的核心。
1、Sigmoid激活函数
Sigmoid函数的表达式
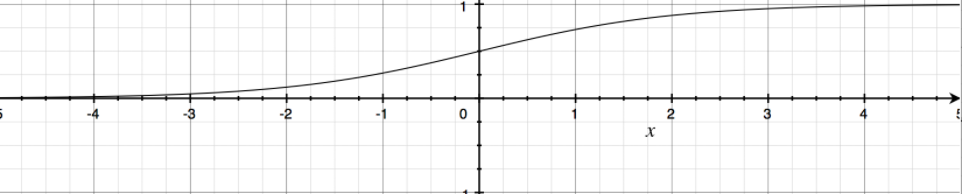
可以看到其数学特性,输出在0-1之间,输入为任意参数
但是Sigmoid函数的缺点就是存在梯度消失或梯度爆炸的问题,而且不仅如此,sigmoid函数的输入在-4,+4之间变换较为大,但超出该范围的输出变换基本将趋于0,这样在数据拟合上就显得更加局限,
2、tanh函数
tanh函数数学表达式和图形
可以看出来tanh函数其实就是sigmoid的拓展版,它在输出上具有更大的变化性,但是和sigmoid函数一样还是存在着梯度爆炸和消失的问题
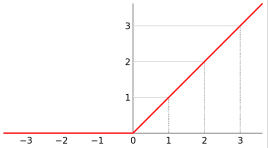
3、ReLu函数
ReLu函数可以说是深度学习或神经网络中特别常用的一个函数它的构造比较简单
可以看出在输入小于0的时候其输出为0,它的梯度较为平稳,不管怎么叠加,不会出现梯度消失或者爆炸问题,但是这也存在另一个问题,它的负领域可能会出现神经元死亡的问题,由此产生了变形的Relu函数比如Leaky Relu等
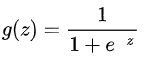
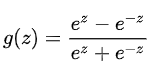

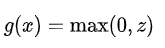















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









