







这里采用的是MiT-B0架构。因为官方的代码比较多,有点冗余,是基于MMsegmentation的,我并不熟悉这个框架,所以这里采用的第三方实现的pytorch。https://github.com/lucidrains/segformer-pytorch
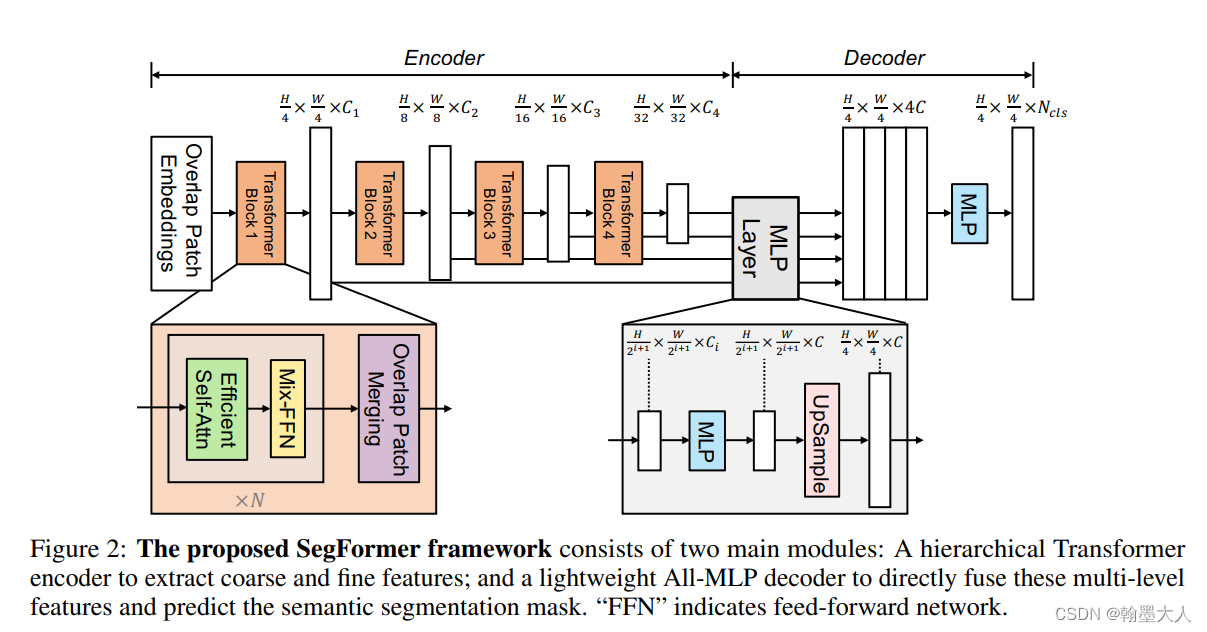
这里的详细配置如下:
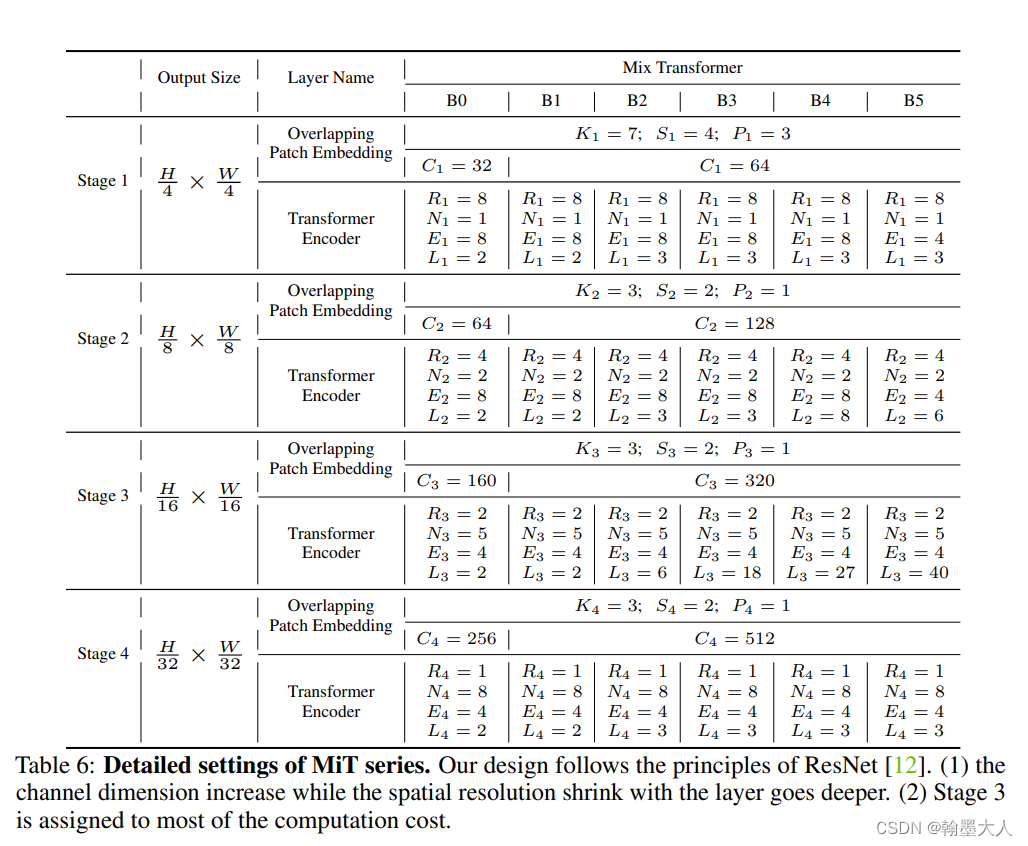

这里看一下整体的代码:
from math import sqrt
from functools import partial
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
# helpers
def exists(val):
return val is not None
def cast_tuple(val, depth):
return val if isinstance(val, tuple) else (val,) * depth
# classes
class DsConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding, stride = 1, bias = True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
)
def forward(self, x):
return self.net(x)
class LayerNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
std = torch.var(x, dim = 1, unbiased = False, keepdim = True).sqrt()
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) / (std + self.eps) * self.g + self.b
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = LayerNorm(dim)
def forward(self, x):
return self.fn(self.norm(x))
class EfficientSelfAttention(nn.Module):
def __init__(
self,
*,
dim,
heads,
reduction_ratio
):
super().__init__()
self.scale = (dim // heads) ** -0.5
self.heads = heads
self.to_q = nn.Conv2d(dim, dim, 1, bias = False)
self.to_kv = nn.Conv2d(dim, dim * 2, reduction_ratio, stride = reduction_ratio, bias = False)
self.to_out = nn.Conv2d(dim, dim, 1, bias = False)
def forward(self, x):
h, w = x.shape[-2:]
heads = self.heads
q, k, v = (self.to_q(x), *self.to_kv(x).chunk(2, dim = 1))# q:(1,32,64,64)k:(1,32,8,8)v:(1,32,8,8)
# 1,(1,32),64,64-->((1,1),4096,32)
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = heads), (q, k, v)) #h=1
#q(1,4096,32),k(1,64,32),v(1,64,32)
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale#(1,4096,64)
attn = sim.softmax(dim = -1)#(1,4096,64)
out = einsum('b i j, b j d -> b i d', attn, v)#(1,4096,32)
out = rearrange(out, '(b h) (x y) c -> b (h c) x y', h = heads, x = h, y = w)#(1,32,64,64)
return self.to_out(out)
class MixFeedForward(nn.Module):
def __init__(
self,
*,
dim,
expansion_factor
):
super().__init__()
hidden_dim = dim * expansion_factor
self.net = nn.Sequential(
nn.Conv2d(dim, hidden_dim, 1),
DsConv2d(hidden_dim, hidden_dim, 3, padding = 1),
nn.GELU(),
nn.Conv2d(hidden_dim, dim, 1)
)
def forward(self, x):
return self.net(x)
class MiT(nn.Module):
def __init__(
self,
*,
channels, # 3
dims, #(32,64,160,256)
heads, #(1,2,5,8)
ff_expansion, #(8,8,4,4,)
reduction_ratio,#(8,4,2,1)
num_layers#(2,2,2,2)
):
super().__init__()
stage_kernel_stride_pad = ((7, 4, 3), (3, 2, 1), (3, 2, 1), (3, 2, 1))
dims = (channels, *dims) #(3,,32,64,160,256)
dim_pairs = list(zip(dims[:-1], dims[1:]))#[(3,32),(32,64),(64,160,(160,256))]
self.stages = nn.ModuleList([]) #
for (dim_in, dim_out), (kernel, stride, padding), num_layers, ff_expansion, heads, reduction_ratio\
in zip(dim_pairs, stage_kernel_stride_pad, num_layers, ff_expansion, heads, reduction_ratio):
#(3,32),(7,4,3),(2),(8),(1),(8)
get_overlap_patches = nn.Unfold(kernel, stride = stride, padding = padding) #(7,4,3)
overlap_patch_embed = nn.Conv2d(dim_in * kernel ** 2, dim_out, 1)#conv2d(147,32,1,1)
layers = nn.ModuleList([])
for _ in range(num_layers): #循环两次
layers.append(nn.ModuleList([
PreNorm(dim_out, EfficientSelfAttention(dim = dim_out, heads = heads, reduction_ratio = reduction_ratio)),
PreNorm(dim_out, MixFeedForward(dim = dim_out, expansion_factor = ff_expansion)),
]))
self.stages.append(nn.ModuleList([
get_overlap_patches,
overlap_patch_embed,
layers
]))
def forward(
self,
x,
return_layer_outputs = False
):
h, w = x.shape[-2:] #256,256
layer_outputs = []
for (get_overlap_patches, overlap_embed, layers) in self.stages:
x = get_overlap_patches(x) #(1,147,4096)
num_patches = x.shape[-1] #4096
ratio = int(sqrt((h * w) / num_patches)) #4
x = rearrange(x, 'b c (h w) -> b c h w', h = h // ratio) #(1,147,64,64)
x = overlap_embed(x) #(1,32,64,64)
#stage每迭代一次,layer迭代2次。
for (attn, ff) in layers:
x = attn(x) + x
x = ff(x) + x #(1,32,64,64)
layer_outputs.append(x)
ret = x if not return_layer_outputs else layer_outputs
return ret
class Segformer(nn.Module):
def __init__(
self,
*,
dims = (32, 64, 160, 256),
heads = (1, 2, 5, 8),
ff_expansion = (8, 8, 4, 4),
reduction_ratio = (8, 4, 2, 1),
num_layers = 2,
channels = 3,
decoder_dim = 256,
num_classes = 4
):
super().__init__()
dims, heads, ff_expansion, reduction_ratio, num_layers = map(partial(cast_tuple, depth = 4), (dims, heads, ff_expansion, reduction_ratio, num_layers))
assert all([*map(lambda t: len(t) == 4, (dims, heads, ff_expansion, reduction_ratio, num_layers))]), 'only four stages are allowed, all keyword arguments must be either a single value or a tuple of 4 values'
self.mit = MiT(
channels = channels,
dims = dims,
heads = heads,
ff_expansion = ff_expansion,
reduction_ratio = reduction_ratio,
num_layers = num_layers
)
self.to_fused = nn.ModuleList([nn.Sequential(
nn.Conv2d(dim, decoder_dim, 1), #(input,256)
nn.Upsample(scale_factor = 2 ** i)
) for i, dim in enumerate(dims)])
self.to_segmentation = nn.Sequential(
nn.Conv2d(4 * decoder_dim, decoder_dim, 1),
nn.Conv2d(decoder_dim, num_classes, 1),
)
def forward(self, x): #(1,3,256,256)
layer_outputs = self.mit(x, return_layer_outputs = True)#四个输出
fused = [to_fused(output) for output, to_fused in zip(layer_outputs, self.to_fused)]#list:4
fused = torch.cat(fused, dim = 1) #(1,1024,64,64)
return self.to_segmentation(fused) #(1,num_class,64,64)
def main():
model = Segformer(
dims=(32, 64, 160, 256), # dimensions of each stage
heads=(1, 2, 5, 8), # heads of each stage
ff_expansion=(8, 8, 4, 4), # feedforward expansion factor of each stage
reduction_ratio=(8, 4, 2, 1), # reduction ratio of each stage for efficient attention
num_layers=2, # num layers of each stage
decoder_dim=256, # decoder dimension
num_classes=4 # number of segmentation classes
)
model.eval()
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
pred = model(x)
print(pred)
if __name__ == '__main__':
main()
首先x输入进self.mit函数,再跳到MIT类中,首先获得x的h和w。然后我们跳到self.stages,开始为一个空列表,往里面添加三个函数get_overlap_patches, overlap_patch_embed, layers。
在MIT函数中首先定义各个变量值,其中在zip函数中,每一个变量都是一个由四个值组成的列表。那么for循环就会遍历四次。而每一次for循环,内部又有两次for循环,那么layer就会有8个MIX-FFN和self-attention注意力模块。即四个stage,每个stage有两个MIX-FFN和self-attention。
代码get_overlap_patches是nn.Unfold函数,起到滑动窗口,提取局部区域块的作用,具体原理如下,图片来源。对应于原图中的overlap patch merging操作。

具体计算K=7X7,则覆盖49个区域,原始图片3通道,则总共有147个通道。
padding=3,步长等于4,则长和宽都分别为有[(256+6-1x6-1)/4]+1=64.共有64x64=4096个块。
则原始的x(1,3,256,256)就会变为(1,147,4096)。num_patches=4096,ratio=4,x变换为(1,147,64,64)。接着是overlap_embed函数,作者在文中说通过一个3x3卷积就可以学到位置信息,overlap_patch_embed是一个nn.Conv2d,输入为147,输出为32。x变为(1,32,64,64)。

接着遍历layers,然后跳到PreNorm函数,首先进行LayerNorm,然后进行EfficientSelfAttention处理。
PreNorm(dim_out, EfficientSelfAttention(dim = dim_out, heads = heads, reduction_ratio = reduction_ratio)),
PreNorm(dim_out, MixFeedForward(dim = dim_out, expansion_factor = ff_expansion)),在自注意力中,我们首先生成qkv,然后进行多头划分,这里以第一层为head=1为例,q=1,(1,32),64,64-->((1,1),4096,32)。作者通过将kv进行卷积核为8,步长为8的计算,来降低计算量。然后进行Q与K计算,生成(1,4096,64)。然后softmax处理,与v相乘,(1,4096,32),然后reshape为(1,32,64,64)。最后再经过一个1x1卷积。回到主函数中,与x相加,生成结果经过ff。
ff函数对应于MixFeedForward函数,用两个1x1的卷积代替了MLP,还用3x3逐点卷积。
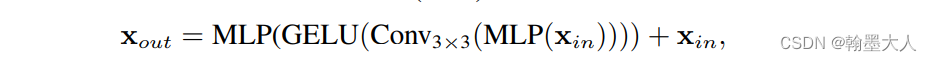
生成的结果添加到layer_out中,四个stage就生成四个列表。mit函数运行完毕。

接着我们遍历layer_out和to_fuse函数,to_fuse由一个卷积,一个上采样组成,卷积是为了让四个输出通道统一为256,upsample是为了上采样到原图1/4大小。这里to_fuse函数遍历四次,是因为每个encoder输出都要进行特征和大小的同一。fused也有四个输出。

我们将四个输出concat到一起,通道变为4c,然后经过一个1x1卷积变回原始大小,最后再通过一个输出通道为num_class的1x1卷积,获得最终分割图。(1,4,64,64)。
作者的代码并没用使用MLP,而是全部用1x1卷积代替的。作者的解释:
















 3699
3699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









