







一、主成分分析PCA

所选超平面性质:最近重构性、最大可分性

可从重构角度设置一个重构阈值t,例如t=0.95,然后选取下式成立的最小d*值:
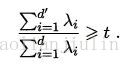
核化线性降维(KPCA):以核函数k(xi,xj)=Φ(Xi)TΦ(Xj)的形式代替XTX。

KPCA在计算降维后的坐标表示时,需要与所有样本点计算核函数值并求和,因此该算法的计算开销十分大
from sklearn.decomposition import PCA
pca=PCA(n_components=2)
X2D=pca.fit_transform(X)
pca.components_.T[:,0] #访问第0各主成分from sklearn.decomposition import KernelPCA
rbf_pca=KernelPCA(n_components=2,kernel='rbf',gamma=0.04)
X_reduced=rbf_pca.fit_transform(X)二、流形学习manifold learning
思想:若低维流形嵌入到高维空间中,则数据样本在高维空间的分布虽然看上去非常复杂,但在局部上仍具有欧氏空间的性质。因此,可以容易地在局部建立降维映射关系,然后再设法将局部映射关系推广到全局。
①等度量映射Isomap:试图保持邻域距离

注意:
1.Isomap仅仅只是得到了训练样本在低维空间的坐标,而对于之后没有参与进算法的新样本,我们利用训练数据的高维坐标作为输入,低维坐标作为输出训练一个回归学习器,从而用来预测新样本的低维空间坐标。
2.近邻图的构建通常有两种做法,①指定近邻点个数,例如欧氏距离最近的k个点为近邻点,这样得到的近邻图为k近邻图;②指定距离阈值ϵ,距离小于ϵ的点被认为是近邻点,这样得到的图就是ϵ近邻图。
存在问题:若邻域范围指定过大,则会造成“短路问题”,即本身距离很远却成了近邻,将距离近的那些样本扼杀在摇篮。 若邻域范围指定过小,则会造成“断路问题”,即有些样本点无法可达了,整个世界村被划分为互不可达的小部落。
补充:MDS算法
不管是使用核函数升维还是对数据降维,我们都希望原始空间样本点之间的距离在新空间中基本保持不变,这样才不会使得原始空间样本之间的关系及总体分布发生较大的改变。“多维缩放”(MDS)正是基于这样的思想,MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持。

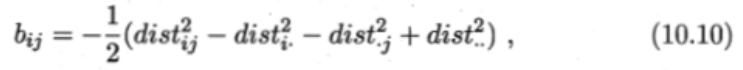
②局部线性嵌入LLE:试图保持邻域内的线性关系



补充:t 分布随机邻域嵌入(t-SNE)

三、距离可分性降维LDA

①目标: 类内间距小,类间间距大。
最大化目标为:
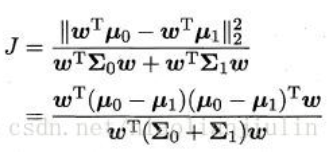
②定义
注:多分类问题中类间离散度矩阵的求解应考虑先验概率不相等的情况。
LDA用于分类:
>>> import numpy as np
>>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = LinearDiscriminantAnalysis()
>>> clf.fit(X, y)
LinearDiscriminantAnalysis()
>>> print(clf.predict([[-0.8, -1]]))
[1]LDA用于降维:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,y)
X_new = lda.transform(X)
plt.scatter(X_new[:, 0], X_new[:, 1],marker='o',c=y)
plt.show()














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









