







1 K-Means聚类
K-Means聚类是最常用的聚类算法,最初起源于信号处理,其目标是将数据点划分为K个类簇,找到每个簇的中心并使其度量最小化。该算法的最大优点是简单、便于理解,运算速度较快,缺点是只能应用于连续型数据,并且要在聚类前指定聚集的类簇数。
下面是K-Means聚类算法的分析流程,步骤如下:
第一步,确定K值,即将数据集聚集成K个类簇或小组。
第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。
第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心。
第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。
第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止。
第六步,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。
K-Means数学依据
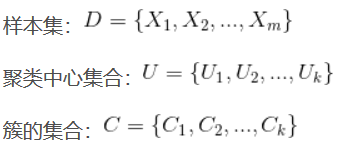
要将样本点划分成K类,我们希望每个样本点离它所以簇的聚类中心越近越好,即:
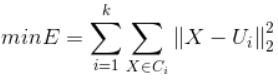

E越小,簇内相似度越高。
2 、利用opencv2实现k-means
cv2.kmeans(data, K, bestLabels, criteria, attempts, flags)
参数:
data: 分类数据,最好是np.float32的数据,每个特征放一列。
K: 分类数,opencv2的kmeans分类是需要已知分类数的。
bestLabels:预设的分类标签或者None
criteria:迭代停止的模式选择,这是一个含有三个元素的元组型数。格式为(type, max_iter, epsilon) 其中,type有如下模式: cv2.TERM_CRITERIA_EPS :精确度(误差)满足epsilon停止。cv2.TERM_CRITERIA_MAX_ITER:迭代次数超过max_iter停止。cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER,两者合体,任意一个满足结束。
attempts:重复试验kmeans算法次数,将会返回最好的一次结果
flags:初始中心选择,有两种方法: ——cv2.KMEANS_PP_CENTERS; ——cv2.KMEANS_RANDOM_CENTERS
返回值:
compactness:紧密度,返回每个点到相应重心的距离的平方和
labels:结果标记,每个成员被标记为0,1等
centers:由聚类的中心组成的数组
3、K-Means聚类对比分割彩色图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取原始图像
img = cv2.imread(r'C:\Users\ZUK\PycharmProjects\pictures\picture12.jpg', cv2.IMREAD_UNCHANGED)
print(img.shape)
# 图像二维像素转换为一维
data = img.reshape((-1, 3))
data = np.float32(data)
# 定义迭代条件 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置标签
flags = cv2.KMEANS_RANDOM_CENTERS
# K-Means聚类 聚集成2类
compactness, labels2, centers2 = cv2.kmeans(data, 2, None, criteria, 10, flags)
# 图像转换回uint8二维类型,并且用聚类中心值替代与其同簇内所有像素点的值
centers2 = np.uint8(centers2)
res1 = centers2[labels2.flatten()]
dst2 = res1.reshape(img.shape)
result= np.concatenate([img,dst2], axis = 1)
cv2.imshow('demo', result)
cv2.waitKey(0)
cv2.destroyAllWindows()

关于聚类中心替代簇内所有像素点的值解释
返回的聚类中心center2如下

labels2是一个(589824,1)的数组,里面的值有0,1两种 (K=2)
res1 = centers2[labels2.flatten()]
这句代码将labels2中值为1的数据点替换为center2中聚类中心1的数据,即(83,166,147),将labels2中值为0的数据点替换为聚类中心0的数据,这样res1的形状就是(589824,3),通过dst2 = res1.reshape(img.shape)将res1变成与img形状一样的数组
4、K-Means分割灰度图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
img1 = cv2.imread(r'C:\Users\ZUK\PycharmProjects\pictures\picture11.png', cv2.IMREAD_UNCHANGED)
'''灰度图像分割'''
# 转换为灰度图
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
# 将二维灰度图像转换为一维数据集
rows1, cols1 = img1.shape
data = img1.reshape(rows1*cols1, 1)
data = np.float32(data)
# 定义迭代参数,迭代停止条件为误差小于EPS(0.5),或者迭代次数超过MAX(20)
criteria = (cv2.TERM_CRITERIA_EPS+cv2.TermCriteria_MAX_ITER, 20, 0.5)
# 初始中心点选择为随机选择
flag = cv2.KMEANS_RANDOM_CENTERS
# 进行聚类
compactnessk2, bestlabelsk2, centersk2 = cv2.kmeans(data, 2, None, criteria, 20, flag)
img1k2 = bestlabelsk2.reshape((rows1, cols1))
img1k2 = cv2.convertScaleAbs(img1k2)
compactnessk3, bestlabelsk3, centersk3 = cv2.kmeans(data, 3, None, criteria, 20, flag)
img1k3 = bestlabelsk3.reshape((rows1, cols1))
img1k3 = cv2.convertScaleAbs(img1k3)
plt.rcParams['font.sans-serif'] = ['SimHei']
title = ['灰度原始图像', 'K = 2', 'K = 3']
image = [img1, img1k2, img1k3]
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
plt.imshow(image[i], 'gray')
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.show()
















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









