







4、现存的数据集
在本节中,我们简要回顾了四个现有的第三人称的视频问答数据集,这些数据集是公开可用的并且在以前的工作通常会使用到。 在表1中,我们采用[21]中的现有数据集的统计信息并对其进行了少量修改。 我们还将在下一部分将它们与我们建议的EgoVQA数据集进行比较。
如表1第三人称部分所示,所有现有的视频问答数据集都是第三人称的视角。 1)TGIF-QA [35]是一个关于71741幅动画图片的超过165,000个问题的数据集,源自TGIF数据集[41]。 在此数据集上形成了多个任务,包括计算所查询动作的重复次数,检测两个动作的转换以及基于图像的质量检查。2)MSVD-QA和MSRVTT-QA [54]是两个具有第三人称视频的数据集,分别源自MSVD[16]和MSVTT[55]。 在这两个数据集中形成的VideoQA任务是开放式问题(open-ended ),其类型是 what, who, how, when 和where,并且它们的答案集大小为1000。3)YouTube2Text-QA[60]是一个数据集,包含三个主要问题类型(what, who和other)的开放性问题和多项选择题(open-ended和multiple-choice)。其视频来源为MSVD [16],而问题来自YouTube2Text [28]视频描述语料库。

5、EgoVQA
在本文中,我们提出了一个以自我为中心的视频问答数据集,名为EgoVQA。基于现有的以自我为中心的视频数据集,我们用八种设计的问题类型手动注释了600多个问题答案对。
5.1 第一视角视频
EgoVQA的视频源是公共国际单位多视图数据集,该数据集是为多视图以自我为中心的视频研究而收集的[20,57]。在原始的国际单位多视图数据集中,有8套室内场景,每一套都有两个同步的第一人称视频,它是由两个不同的参与者在该场景中使用可穿戴式摄像机进行拍摄。每个第一人称视频持续5-10分钟,每个场景有3-4个参与者进行例如吃零食,握手,在白板上绘画等动作。我们用580个问答对对国际单位多视图数据集进行扩展,覆盖了相同数量的从16个较长的第一人称视频中选择的视频剪辑。每个视频剪辑持续20到100秒。我们手动选择满足以下一个或多个条件的视频剪辑:(1)摄像机佩戴者进行诸如喝酒,吃零食,打字等个人动作时;(2)相机佩戴者与其他人互动时(例如握手);(3)当其他参与者正在执行预期的动作时;(4)在相机佩戴者的视野中有可识别的物体。根据视频内容,我们注释了八种类型的问题,这些问题将在下一节中讨论。


在图2中,我们说明了现有的第三视觉的VideoQA注释和EgoVQA注释的区别。 MSVD [16]中排名前三的视频样本(Q1-Q3)表明典型的第三视觉的视频稳定且组成良好; 主要人物出现在画面的中心; 动作清晰可辨,定义明确。 相比之下,我们的EgoVQA数据集的底部三个视频样本说明以自我为中心的视频模糊;除了他们的手和胳膊之外,摄像头佩戴者并没有出现在他们自己的视频中;而且由于自身的姿态和相机角度,动作通常更难识别。
5.2 问题注释
为了从视频剪辑中生成视频问答对,我们花费了大约30个小时的人工时间在英语句子中注释问题和相应的正确答案。 每个问答对都在查询和回答视频剪辑的视觉相关内容。 在表2中,我们列出了EgoVQA数据集中八种主要问题的问答对示例。 第一个动作问题可询问相机佩戴者的自我中心动作,例如“我在做什么”; 第三个动作问题是从摄像机佩戴者的角度询问第三人称动作,例如“穿着红色衣服的人在做什么”; 询问与摄影机佩戴者互动的人,例如“我在和谁聊天”; 谁对其他人的查询行为提出疑问,例如“谁站在门旁”; 计数问题是询问场景中人员或物体的数量; 颜色问题是询问场景中参与者的主要物体或衣服的颜色。
5.3 生成答案
现在我们描述的方法用于为多项选择题生成候选答案,并为开放式问题生成答案集。 (1)VideoQA的多项选择题需要从K个候选答案中选择唯一的正确答案。在EgoVQA中,每个多项选择题都带有五个候选答案,其中一个是正确的。为了产生其他令人困惑的选项,我们将问题按“what action”, “what object”, “who”和“color”进行分类,然后针对每个类别将所有正确答案汇总为该类别的候选池。我们从没有替换的池中随机抽取四个候选样本作为负候选样本。我们运用这个策略来生成“what action”, “what object”, “who”和“color”等问题的候选项。对于“计数”问题,我们将候选答案固定为零到四个。这种采样策略避免生成简单的候选项,这些候选项可以在不理解视觉内容的情况下,通过问题的语法或上下文来推断。(2)开放式任务是从预定义的答案集中选择一个正确的单词或短语作为答案。我们通过聚合整个数据集的唯一正确答案来生成一个包含101个单词或短语的答案集。我们把这项任务留作以后研究。

5.4 划分
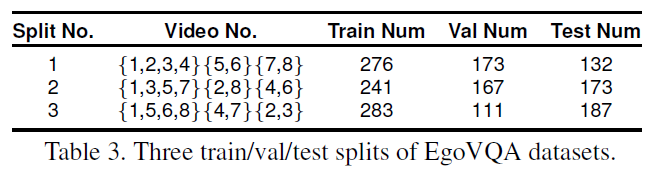
为了进行可靠的评估,我们将数据集中划分成了三个不同的训练,评估和测试部分。 对于IU Multiview数据集中的8个场景(从1到8编号),我们构建了3个训练/验证/测试集,场景编号为4:2:2。每组保留四个场景(8个视频,因为有两个第一人称摄像机)用于训练,两个场景(4个视频)分别用于验证和测试。 当我们从每个第一人称视频中提取多个视频片段(每个25-100秒)时,这种分割方式确保了来自同一视频的视频片段不会同时出现在训练集和测试集中。用于训练、验证和测试的视频片段总数如表3所示。
6、实验和讨论
我们使用我们的EgoVQA数据集评估了四个现有的第三视角的VideoQA模型,并以三个分组的测试集的百分比准确性报告了它们的性能。 具体来说,我们比较了ST-VQA [35] (w/,w/o注意机制),Co-Mem [27]和HME-VQA [21]在EgoVQA数据集的所有三个分割上的多项选择任务(五种分类)。注意所有模型最初都是为第三人称VideoQA设计的。由于我们的EgoVQA数据集在训练样本和词汇量方面相对较小,所以我们在YouTube2Text-QA[60]数据集上预先训练了所有四种不同的模型(详见表1),然后对EgoVQA数据集进行了微调。在没有预先训练的情况下,我们发现模型会很快过度拟合。
6.1 总体效果
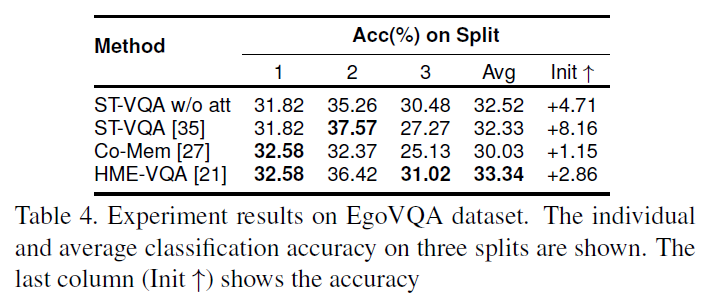
在表4中,我们报告了每个模型在三个分割(Col. 1,2,3)中的准确度百分比,所有分割中的平均准确度(Col. Avg)以及通过预训练的表现提高(Col. Init _)。总体而言,HME-VQA [21]优于其他三种方法,这与他们在第三人称视频数据集上的报告结果一致。令人惊讶的是,带有时间注意力的ST-VQA[35]在准确性上并没有优于没有注意力的ST-VQA。具有双重注意机制的Co-Mem[27]在所有其他方法中表现不佳。我们推测,以自我为中心的视频中强烈的自我动作导致了错误的关注,原因是缺乏将对佩戴者的关注与对第三人的关注区分开来的能力。 HME-VQA的记忆模块内的记忆槽通过隐式学习不同因素的单独关注,缓解了这一问题(见图1),但其性能优势小于1%。未来的工作可以集中在第一人称和第三人称注意力的分离上,去更好的找到相关的视觉内容。我们还发现在大型第三方数据集上对每个模型进行预训练,然后对EgoVQA进行微调,可以提高准确率达到8%,因为单词向量和视频编码器都得到了更好的训练。
6.2 结果
在表5中,我们进一步比较了不同模型在不同问题类型上的表现。从第1列和第2列中,我们观察到在性能最佳的HME-VQA中,第一人称行为查询的准确性比第三人称行为查询(32.84% vs . 41.67%)低约9%,ST-VQA和Co-Mem则低2%和5%。这表明相机佩戴者的动作分类通常比场景中第三人称的动作更难。这是可以理解的,因为佩戴相机的人不会出现在自己的视频中,只有自我运动的证据可以用于分类。此外,对第三人称视频的预训练也有助于第三人称对第一人称视频的查询。从第3和第4列中,我们观察到第一人称对象查询的准确性通常高于第三人称对象查询。这可能是因为佩戴相机的人与之互动的对象通常离相机很近,并且位于镜框的中央。类似的趋势也适用于谁查询,因为第一人称的谁查询通常比第三人称的谁查询更准确(第5列和6列)。对于颜色查询,我们发现大多数模型的表现都比随机猜测(20%)差超过5%。对被查询的对象进行局部化很可能已经是一项艰巨的任务,而为有噪声的局部像素分配颜色则更加困难。未来的工作可以使用目标检测或分割技术更好地定位查询对象,并在图像平面上更好地细化参与区域。

6.3 未来工作
为了减轻第一人称和第三人称视频上的动作查询准确性的差距,我们推测第一步可能是分离第一人称和第三人称的注意力。作为一种直接的方法,值得尝试同时明确地评估自我动作和第三人称动作,并针对第一人称查询在重要的自我动作框架上学习第一人称注意力。 通过形成双重问题共同学习第一人称和第三人称注意力(相机A中的第一人称问题将成为相机B中的第三人称问题,反之亦然)也可以隐式地完善第一人称和第三人称注意力。 EgoVQA对同步多摄像头视频具有第一人称和第三人称查询,同时支持两个研究方向作为基准数据集。
6.4 实现细节
我们在PyTorch[45]中实现了基准神经网络,并使用Adam optimizer[38]更新了参数。在整个实验中,我们使用固定批处理大小为32,学习率为 1 0 − 3 10^{−3} 10−3 。对于每个模型中的视频和文本编码器,我们使用相同的隐藏大小为256的两层LSTMs。对于HME-VQA方法,我们将视频和问题记忆大小设置为与LSTM隐藏大小相同的大小。我们将发布EgoVQA数据集、预训练的模型和评估方法,以鼓励对这一主题的进一步研究。
7、结论
在本文中,我们提出了一个名为EgoVQA的以自我为中心的VideoQA数据集,据我们所知,这是第一个专门用于以自我为中心的视频研究的VideoQA数据集。 我们还通过评估现有的最新第三人称VideoQA方法建立了基线。 实验结果表明,现有方法通常缺乏处理自我运动或第一人称活动和第三人称活动单独注意力的能力。 我们将公开数据集和代码,以促进对该新颖而重要的研究主题的进一步研究。 作者还鼓励社区在较大的数据集(例如ImageCLEF Lifelog [17]和NTCIR Lifelog [29])上注释问题/答案对,以探索更大的神经网络设计。














 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









