







信息检索与智能问答
一、信息检索模型

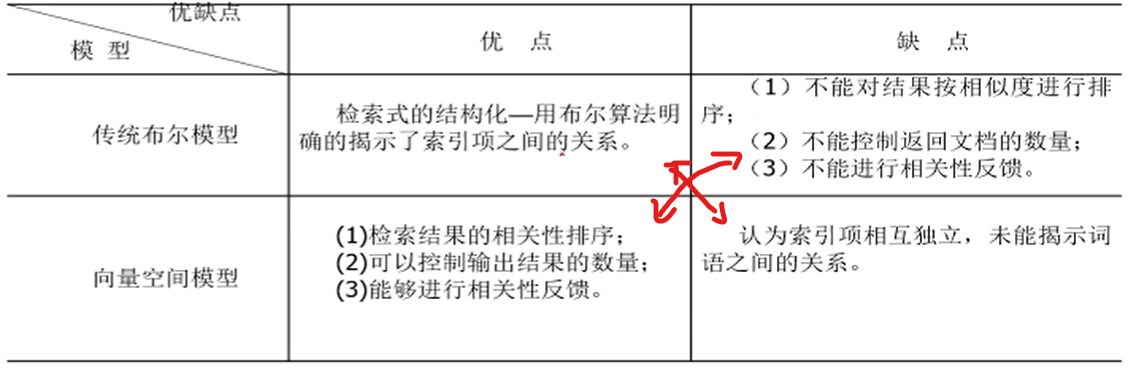
1. 布尔模型

将用户的查询式表示为==析取范式==:⽤连词v把⼏个公式连接起来所构成的公式叫做 析取
将文档根据用户关键词 表示为 布尔表达式
查询时直接 以文档的布尔表达式 和 用户查询析取范式 按位与

优点:
查询简单,易理解,查询速度快
可以揭示索引项(Term)之间的关系 - 可以通过布尔表达式刻画出来(A地 苹果 C地) (1 1 0)表示’A地的苹果‘

缺点:
关键问题:不能对 文档和查询 的相关性进行排序

2. 向量空间模型 - 由布尔模型不足(相似度不能排序)提出

将用户的查询也看成了一个 文档,再由文档 分出一个个 索引项(Term)
提出就是为了能够 计算两个文档相关程度的大小

查询和文档都可以 转化成Term及其权重组成的向量表示,因此就可以衡量两者的相关度
关键问题:
Term(索引项)的选择 - 可以描述文档的内容,可以区分当前文档与其他文档

索引项选择 - N-gram:是为了一些小语种,这样做简单有效

索引项的权重 - 刻画描述文档内容的能力,区分其所在文档与其他文档的能力 — TF-IDF
文本的长短会影响TF的值 —> 为了不影响计算,直接归一化(Normalization)



相似度计算 — 内积计算,余弦相似度,Jaccard系数
优点:(布尔模型的缺点 就是 向量空间模型的优点)
模型有很大的灵活性,只提供了一个框架,在实现时用户可以选择很多方法实现
布尔模型不能衡量相关度,该模型可以衡量相关度,所以可以排序,因此提高了检索性能

缺点:
为了简化模型,引入了索引项独立性假设,但现实并不是如此
没有严密的公式推理

3. 扩展布尔模型
二者具有高度的互补性
用向量空间模型 改进 传统布尔模型
4. 概率模型 - 二值独立检索模型
基本思想
概率模型 是在 布尔逻辑模型的基础上 为了解决检索中存在一些 不确定 性引入的
如下图第3点,信息检索系统有很多不确定性


假设: 对用户的查询,都存在一个理想文档集R,只包含完全相关的文档
Term(索引项)的选择 - 可以描述文档的内容,字/词/短语 之类的
信息检索 -> 描述理想文档集(处理文档属性)-> 用索引项刻画属性 -> 引入概率论
模型定义,假设,过程
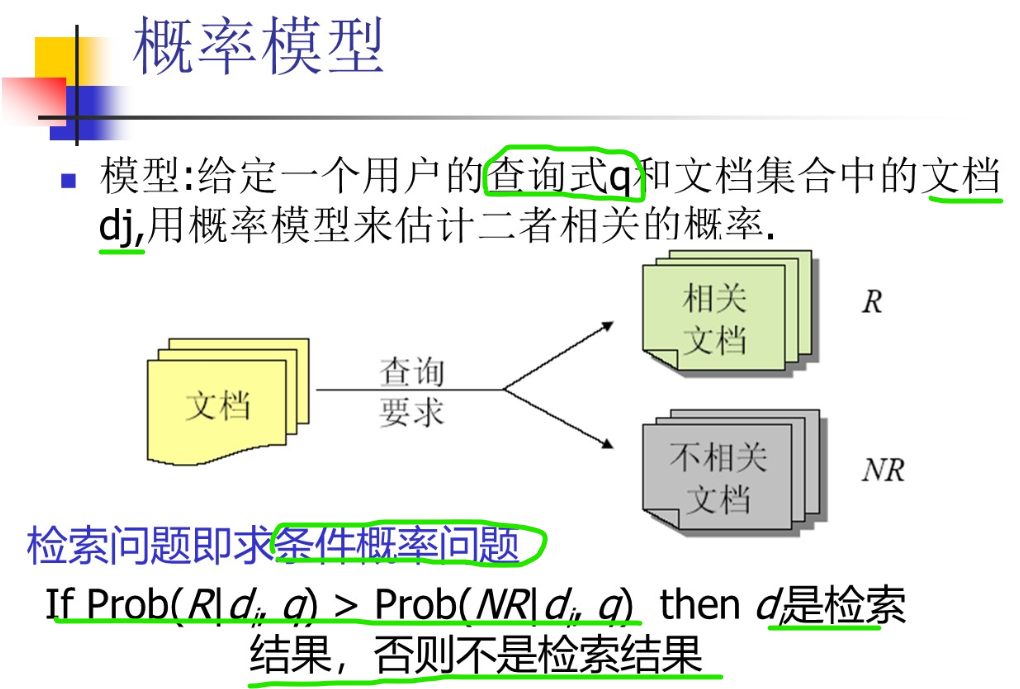
每个文档di 和 查询q 计算相关概率和不相干概率

二值独立检索模型 - 二值(文档相关性:相关和不相关),独立(索引项之间独立,文档和查询式相关性与其他文档独立)

**定义相似度:**类似TF-IDF,一个文档是否选择,即与相关文档集有关,又与非相关文档集有关
相似度 sim(dj, q) 是 文档与查询相关的概率 / 文档与查询不相关的概率
(**P(R/di):**是文档集和文档的相似度,这种相似度的计算需要转化到索引项上)

为了衡量文档集和文档之间的相似度 — 文档d被定义为: 索引项的向量(w1,j, …, wn,j)
使用已知量 对 两个概率进行估计

**相等的理由:**简单来说就是表示 - 随机抽取一篇文档 是否和 查询相关的概率

连乘是因为索引项独立
g i ( d j ) g_i(d_j) gi(dj)表示 索引项 是否同时出现在文档 d j d_j dj和查询中


初始化后 -> 就可以计算文档和查询相似度 -> 得到相关和不相关文档集 R , R ‾ R,\overline{R} R,R -> 之后就可以进行迭代,用新的集合计算上图概率值
即:新参数 和 新文档集 不断迭代
优缺点:
比向量空间模型 的数学推理 严密

缺点:
向量空间模型灵活: 有很多种实现方法; 概率模型 没有其灵活
因为该模型需要迭代,所以在速度上有劣势
5. 统计语言模型 - 马尔可夫链

计算一个序列出现的概率 - 不可以假设每个词之间独立,所以可以用链式规则进行解

如果用链式法则计算时,会出现参数太多的问题:比如文字有8000个,要计算每个P(w1,w2),就有8000*8000种可能
因为因为考虑的词多了,需要计算的可能排列就多了,所以可以使用马尔科夫链减少考虑的词

n元语言模型 最大似然估计
N元语言模型 == N-1阶马尔科夫链


可以估计 有限文本h情况下 所有排列的可能性

可能出现概率为0 的 情况,使用平滑

基于语言模型的IR - 相似性是生成查询的概率

重点:对每个文档得到一个语言模型 -> 将文档的语言模型生成查询q的概率 看成文档和查询的相似度
计算文档语言模型可以提前计算,因此在计算相似度时速度 会很快
优缺点:
优点:
概率模型,向量空间模型都有索引项独立的假设,但该模型没有

缺点:
每一个文档建立一个语言模型,而一个文档数据量比较少,所以会出现稀疏性
6. 隐性语义索引模型LSI
问题提出 - 以词多义 一义多词

为了解决一词多义和一义多词
一词多义:会影响返回相关文档准确率下降
一义多词:相关文档会找不全
模型方法 - 统计的方法
LSI提出的目的是:绕过自然语言处理,用统计的方法达到目的 - 奇异值分解


奇异值分解 可以保留有用的信息,让语义变得紧凑
如果有一词多义和一义多词,会在语义上比较分散,通过分解后,语义被压缩,干扰语义的信息会被丢弃

d2,d3文档没有共同词汇,如果用其他方法模型计算相似度就为0
但是d2中电脑和d3中计算机是相关的


压缩后d2,d3就有了相似度
优缺点:


7. 检索系统评价指标 - 相关度排序
时间与空间性能 和 相关度排序性能

准备条件:

1> 基本评价指标
召回率和准确率 - 一个查询

对一个查询q:
召回率 = 系统输出结果是相关的文档数 / 相关的文档数 — (全不全)
准确率 = 系统输出结果是相关的文档数 / 检测的文档数 — (准不准)
准确率上升时,召回率下降

该方法画出的图 用于比较两个系统的性能
平均准确率 - 多个查询

2> 单值评价指标 - 都关注准确率
不关注召回率是因为 — 找出所有的相关文档是不现实的
但准确率只需要判断找出的文档是否相关,这个任务比召回率的简单

已检索相关文献的平均准确率均值 MAP

MAP公式解释:相关文档位置越靠前,值越高
检索出的结果:R1,R2,R3,R4 (黑体为相关的文档) — 2个相关文档,检出第一个相关文档准确率是1/2,第二个是2/3
MAP = 1/2 * (1/2 + 2/3)
P@10

R准确率 — P@R 对单个查询

准确率直方图 - 多查询

不足:

- 判断不完整,2. 高低相关度的差异未体现
3> 特殊的评价指标

Bpref指标 - 对经过判断的文档评价
对于每个结果文档,依次判断文档是否相关也比较难 (判断不完整)
Bpref 只考虑返回结果中 经过判断的文档,没有判断的不考虑


未判断的文档不计入不相干文档数
相关性判断完整的情况下,Bpref和MAP是一致的评价结果
N(D)CG - 对高相关性文档检索能力评价



CG — 用户依次看返回的文档时,用户获得的累计信息量
但该权值 不能很好的体现 文档位置对用户的价值

体现了文档位置对用户的使用体验

归一化结果表示:考察一定数量的文档时,达到了理想状态的百分之多少

单一相关文档检索的评价 - 只看最相关文档
用户只看第一个最相关的文档

排序倒数 RR - 没刻画相关度

位置的倒数 — 本质是一个准确率值(输出了r个文档,只有一个相关 )
没有刻画相关度程度:RR是基于而言相关判断基础的
平均排序倒数 MRR

反映了:效率 — 平均查看多少个文档 才能 找到相关文档
O-measure - 可评价相关度不同的文档

NWRR

二、文本索引和搜索


检索结果文档的后处理:对文本内容不适用索引技术进行查找,并进行过滤 或 加粗

1.倒排文件索引


维护倒排文档需要三种操作:插入,删除,更新
但更新需要较高的代价,所以用删除+插入代替

压缩


长字符串存储单词表,每个单词之间进行分割(\0)



2.后缀数组索引 - 倒排不足
便于词组(短语)查询,对于不存在词可以很好的查询,方便词组查询


3.签名文件索引
面向单词的索引结构,适合小规模文本


将多个单词分成一个块,块的签名是块中单词签名 按位或 操作


F位,m位置1:m越大,物件出现的次数就会增加;m减少,为了保证单词签名不同,F就会变大,m不能过大,也不可过小
4.文本搜索技术 - 单模式匹配
不能建索引时,可以使用文本搜索来标记 文本内容 中 关心的内容所在位置

BF算法 - 蛮力算法(简单,容易实现;复杂度高)

KMP算法

BM算法 - 更有效


两种情况,对应不同的策略
KMP研究的是模式字符
BM研究的是文本

三、Web检索(Web IR) - 搜索引擎
定义:针对互联网的文本数据,搜索引擎是最经典的代表


1.Web搜索引擎四个体系结构

Web数据采集

工作原理:


Web数据采集系统基本结构
集中式Web数据采集系统结构
分布式Web数据采集系统结构 - 主次结构 对等结构
数据采集系统的分类:

基于主题的采集:对热点主题单独进行采集
前三个都是被动的采集过程,采集不是很高效
迁移的数据采集:主动采集过程,当信息改变时,由网站通知采集,高效;之所以仍在理论研究,是因为信任问题
网页预处理
重心放在:将正文提取出来;去重
去重工作用模型(如:向量空间模型)做会比较困难,因为数据量多,计算成本太大

索引检索系统
上两章中的文本索引和搜索 和 信息检索模型
检索结果排序系统
经过索引检索系统后有一个排序结果,但其是基于文字内容的,有很多信息没有用到:忽略了标记和超链接等内容。
例如:人们更想用官方信息

PageRank算法 – 判断网页权威(重要程度)
利用网页的链接信息得到权威网页
和用户无关,所以可以线下计算好

如何标识重要程度:
一个网页被指向的越多,他的重要程度就越高;
指向它的网页重要程度越高,它就越重要
指向它的网页若指向其他网页个数越多,它越不重要


四、文本分类和聚类
如果把数据分成类别,在对用户查询的意图进行判断,那么查询的数据量就会减少很多





不需要训练过程


五、智能问答
信息检索和智能问答的关系

阅读理解式问答: 基于传统信息检索返回的文档,系统由用户的Q,从这些文档中找的答案A — 相当于二次删选
基于知识库的问答:固定的常识,非常依赖知识库,需要构建知识库,且覆盖度,时效性不够
知识库构建中的实体识别后又要加一个关系分类,这样会导致错误累计,所以现在主流方法直接使用三元组抽取
知识库表示:将知识库映射成具有语义信息的,可计算的形式。即:将知识库变成一个低维可计算的向量,可以得到“妻子”,“太太”是一种关系
智能问答分类:

1.基于知识库的问答:

1.实体关系三元组抽取
- 传统 - 基于Pipeline构建:
命名实体识别模型和关系分类模型被当作两个不同的模型研究

- 实体关系三元组的联合抽取:

基于生成的方法 — 生成文本的序列(将三元组当成文本的序列)

按序生成S,R,O,这样会得到三元组集合
性能最低 — 三元组集合中内容原本是无序的,但生成模型生成是有顺序的(即花了时间在生成循序上)
实体重叠:一个实体是由abc组成,另一个是由bcd组成,有共同的文本
实体嵌套:中国 中国北京
基于标注的方法

两个标注方法是基于标注的两个步骤:
先标头实体
在尾实体和关系同时标注时:对每个头实体,与每一个尾实体做匹配,得到两者对于每种关系的可能性
基于填表的方法

n * n * r:n * n是单位和单位(单位:字or词)的矩阵,r是之间的关系
即:每个关系都有n * n的表
优点:推理效率高,对比基于标注的方法的两个步骤,其是一步完成三元组抽取
缺点:填表是一个迭代操作,所以标注空间大;表中的写的标识tag不太好设计,希望tag能够体现出语义信息
2.实体关系三元组最新研究




实质是基于表填充的方法,定义一个标签tagging
隐含的三元组:a和b是同学,b和c是同班,所以a和c是同学;这是隐含在推理路径中


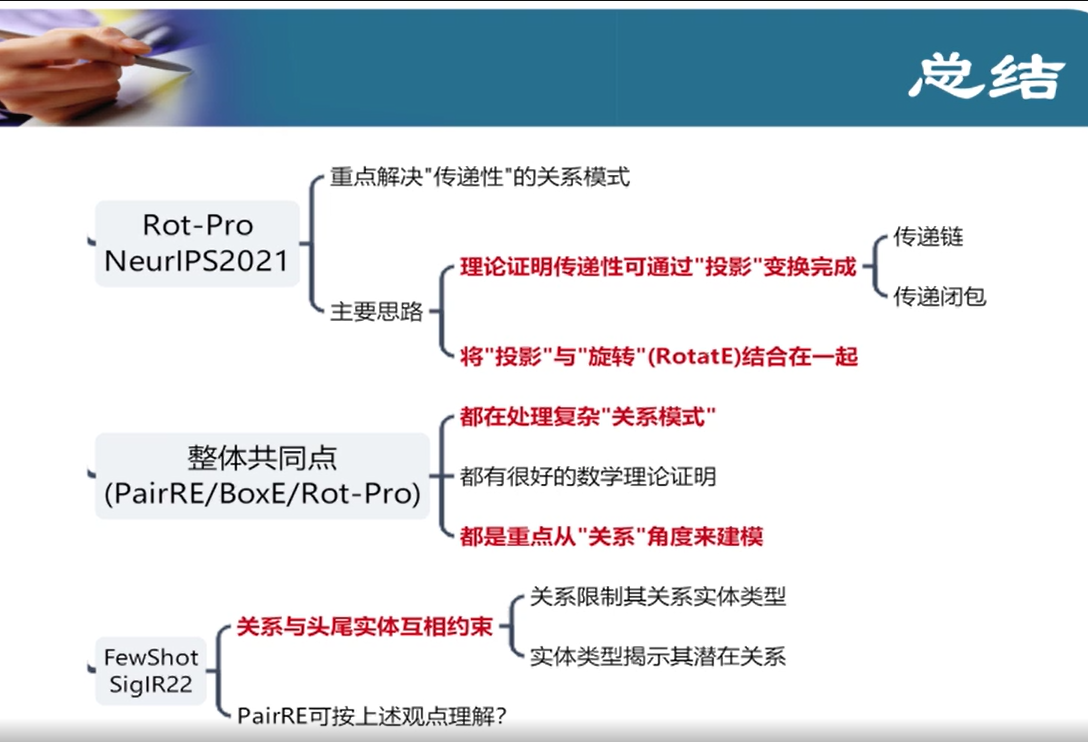
有很多实际情况,现时中的关系并没有在训练集中出现,这就有了Zero-Shot和Few-Shot
关系和实体之间相互约束


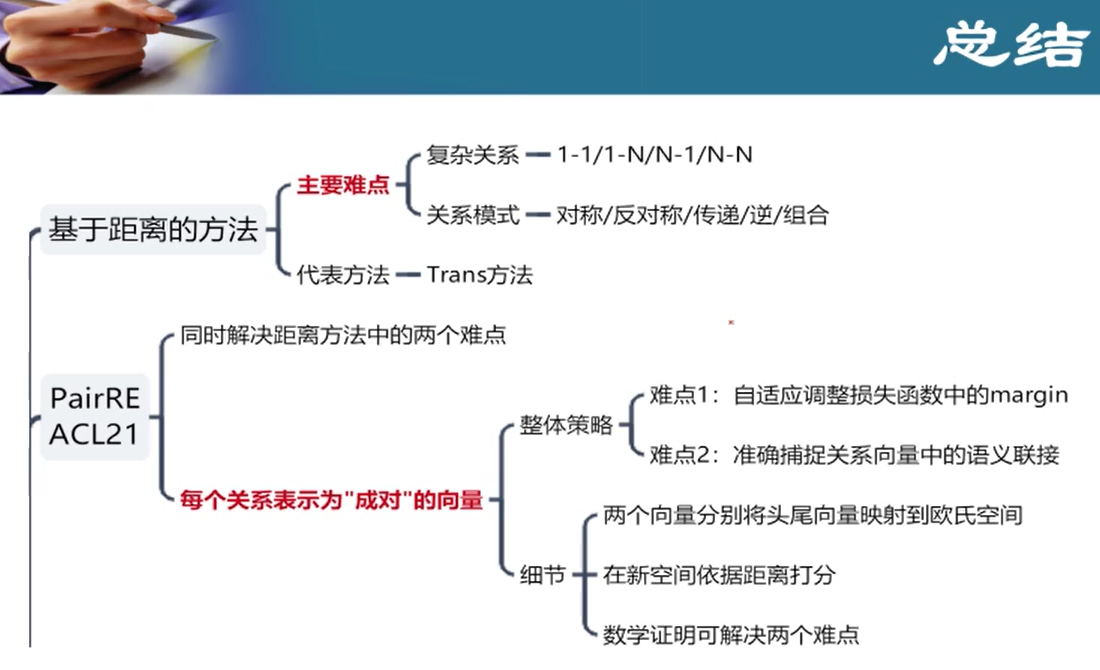
六、知识图谱表示KGE - 二元关系知识图谱



难点:
- 复杂的关系:关系类型多,1:1,1:N,N-1,M-N
- 复杂的关系模式:对称/反对称,逆,组合
**KGE: **实体映射成空间中的一个点,关系是空间中的一个操作
1.Trans系列

各个方法的差别:如何去理解知识图谱中三元组在空间中的形式

TransE
实体映射成空间中的一个点,关系是空间中的一个平移操作


TransH
空间中的多个点,可以映射到 超平面中 的某个点上
解决了1-n, n-1, m-n关系


TransR
每个实体都有多个语义面,而不同关系关注不同的语义面
关系定了后,语义也会被决定
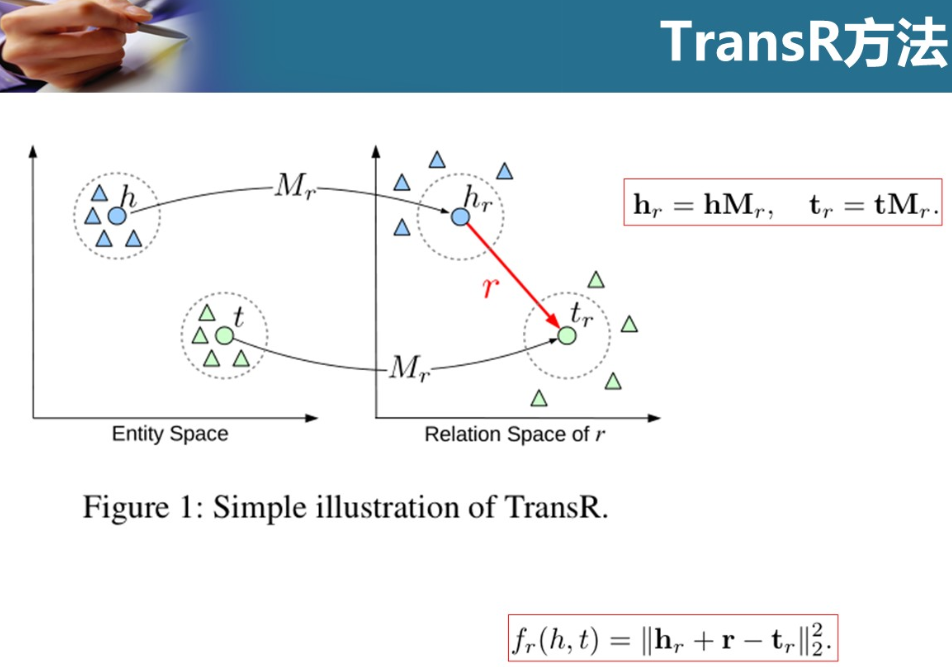
头实体和尾实体用了和一个矩阵进行映射,有研究觉得不合理
2.张量分解

打分函数:头实体 e i e_i ei 张量 M k M_k Mk 尾实体 e j e_j ej,通过这个函数判断头实体和尾实体有这个关系的可能性
不同模型的差别:张量的分解形式
双线性模型就是将实体映射到双线性空间中的某个点,而关系就是对应空间张量分解的操作


Trans系列方法对于上述两类问题解决
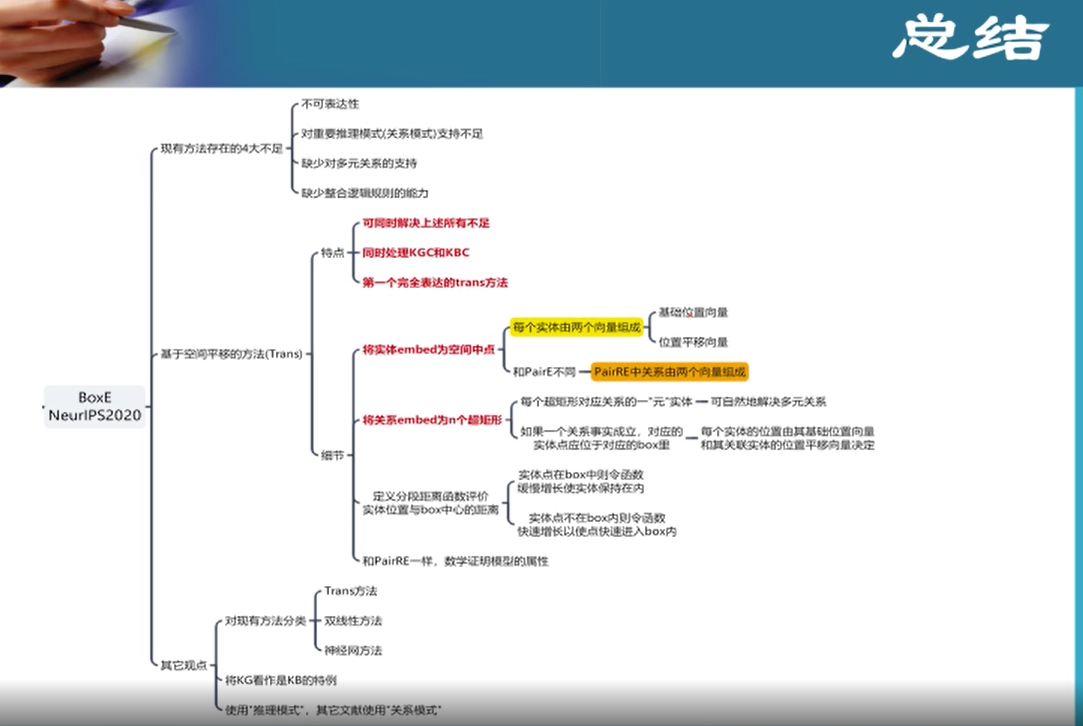
3.二元关系KGE最新研究进展
把实体和关系映射到一个空间,在该空间中将结构保留出来
把实体当成空间中的一个点,关系作为操作

PairRE - 正确的三元组,在经过关系的映射后,距离接近


4.三元关系最新发展





七、阅读理解式问答
Q —IR—》 D(相关文档) —MRC—》 A(直接从相关文档中利用阅读理解式问答提取答案)

基于知识库问答 - 覆盖率低,精度高
基于阅读理解式问答 - 覆盖率极广,精度没法太高

长文本处理:处理文本第一步使用预训练模型Embedding,但模型都对文本有限制(512字节),在做长文本任务时会超出限制
1.截断(重点会放在前面) 2.滑动窗口(把语义割裂了,语义不完整)
鲁棒性研究:泛化能力(训练在A,测试在B);few-shot,zero-shot(训练时就不充分);
过敏感(对输入太敏感了,容错能力低);过稳定(对输入不敏感,对于不同输入希望改变但却没变)
1.综述

给定一些文档和与文档相关的问题,让机器从文档中找出问题的答案


完形填空:给定挖空的文章,对应的答案,选择答案
多项选择:给定文本,给定问题,给出多个答案,选择答案
上面两个存在问题 - 单词或实体不足以回答问题,答案需要一些完整句子,难以构造答案
片段抽取:给定问题,文章,抽取连续的片段,有代表性的数据集 - 斯坦福的SQuAD
自由作答:给定问题,文章,答案不再限制于原文的句子
代表性数据集:微软的MS MARCO

DuREader - 中文数据集


ROUGE-L:包含最长公共子串任务

前三大步现在可以直接用Bert来进行
Answer Prediction:使用指针网络;边界模型 - 确定头位置,尾位置(文本中每个token有两个概率-作头的概率 s i s_i si,作尾的概率 e i e_i ei,最后答案 m a x s i ∗ e j ( i < j ) max s_i*e_j(i<j) maxsi∗ej(i<j)
很多研究者将自由作答式任务做成片段抽取式任务进行
现在自由作答任务:文本中抽取+字典中生成
抽取+生成 - 整个过程是一个以字为单位,序列生成的过程:
生成某位置时,要看这个字是从文本中copy过来的还是从字典中得到的,两个概率进行叠加,哪个词叠加概率最大,就生成出来
发展趋势:
基于知识的阅读理解会兴起

知识如何获取,知识如何融合

识别是否能回答,不仅仅是一个简单的二分类问题,它依赖模型对文档的理解
- 多文档机器阅读理解
- 对话式阅读理解,数据集:CoQA,QuAC
待解决问题:
外部知识引入
阅读理解系统鲁棒性
推理能力缺乏
2.不连续MRC
片段抽取时,使用边界模型就可找出片段,但有时候答案需要由多个片段组成















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









