







回归分析
研究X与Y的相关性

- X — 自变量, Y — 因变量
- 回归的分类
- 解释性回归
- 预测性回归
- 回归分析的任务
通过研究X和Y的相关关系,尝试去解释Y的形成机制,进而达到通过去预测Y的目的 - 使用目的
- 判断那些X是与Y真的相关
- 相关的X与Y是正相关还是负相关
- 不同X有不同的权重(不同的回归系数),可以得到不同变量之间的相对重要性
- 回归分析的分类
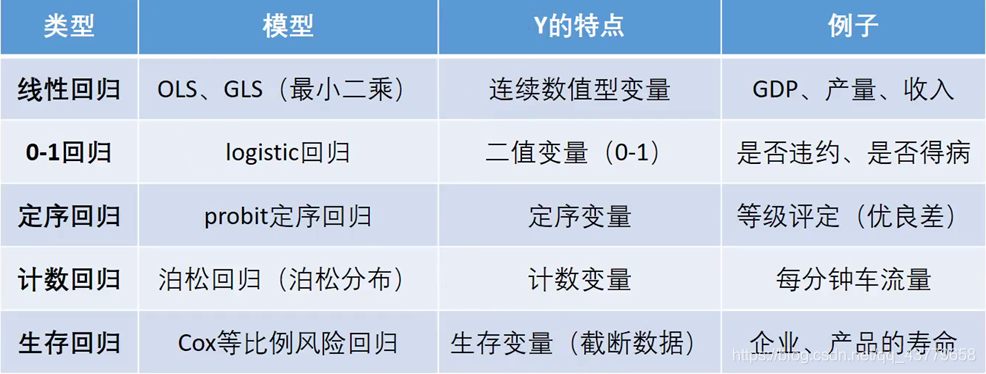
- 不同数据处理方法

数据分类 — 通过数据类别选择合适的建模方法
- 横截面数据 — 在某一时间点收集的不同对象的数据
比如:某年各省的GDP - 时间序列数据 — 对统一对象在不同时间所得数据
比如: 一个省每年的GDP - 面板数据 — 横截面数据与时间序列数据综合起来
比如: 2008-2018,各省份GDP

数据网站
【简道云汇总】110+数据网站
【汇总】数据来源/大数据平台
大数据工具导航
大数据查询导航
线性回归 — 横截面数据
对线性的理解
自变量和因变量可以通过变量变换而转化为线性模型

- 例如:将 y i = β 0 + β 1 l n x i + μ i y_i=\beta_0+\beta_1lnx_i+\mu_i yi=β0+β1lnxi+μi中的 l n x i lnx_i lnxi用一个新变量进行替换
用新变量替换时求对应的值可以使用Excel
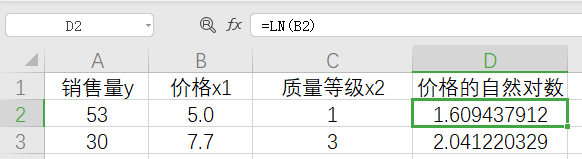
回归系数
回归系数解释


使用回归前,要检验扰动项是否满足某些条件 — 重点
扰动项 μ \mu μ的 内生性
- 误差项 μ \mu μ与自变量 x x x相关
- 扰动项 μ \mu μ中包含了与 y y y有关但没有放到模型中的变量

1.对于扰动项
μ
\mu
μ满足一定的条件为:不存在内生性,不存在异方差
2. 例如: 在仅有变量
x
x
x为产品品质时,会出现内生性
-
∵
\because
∵ 会有价钱也与
y
y
y有关,因为没有添加到模型中(即存在于
μ
\mu
μ中),而价格于品质
x
x
x有关
∴ \therefore ∴ 产生了内生性
外生性很难满足
∴ \therefore ∴为了降低了条件 — 引入核心解释变量和控制变量
解决外生性 — 核心解释变量和控制变量
 仅仅保证核心解释变量与
μ
\mu
μ无关,而不用保证控制变量与
μ
\mu
μ无关
仅仅保证核心解释变量与
μ
\mu
μ无关,而不用保证控制变量与
μ
\mu
μ无关
∴
\therefore
∴ 控制变量就是为了控制那些对核心解释变量影响的遗漏的变量(这些变量在
μ
\mu
μ中)
当式子中有对数时,对回归系数的解释
总结:四类模型回归系数的解释


多变量时
加一句:在控制其他自变量不变的情况下
变量
定性变量变为定量变量 — 引入虚拟变量

虚拟变量解释
例如研究性别与工资影响:
y
i
=
β
0
+
δ
0
F
e
m
a
l
e
i
+
β
1
x
1
i
+
β
2
x
2
i
+
.
.
.
+
μ
i
y_i=\beta_0+\delta_0Female_i+\beta_1x_{1i}+\beta_2x_{2i}+...+\mu_i
yi=β0+δ0Femalei+β1x1i+β2x2i+...+μi
-
F
e
m
a
l
e
i
=
1
Female_i =1
Femalei=1:表示第
i
i
i个样本为女性
F e m a l e i = 0 Female_i =0 Femalei=0:表示第 i i i个样本为男性
核心解释变量: F e m a l e Female Female
控制变量: x m ( m = 1 , 2 , . . . k ) x_m(m=1,2,...k) xm(m=1,2,...k)

设置虚拟变量
为了避免完全多重共线性的影响,引入虚拟变量的个数一般为分类数 - 1
比如:定性变量(男/女),有两个分类,所以设置一个虚拟变量
当出现完全多重共线性时,回归系数无法计算
含有交互项的自变量
- 因变量受到一个核心解释变量和另一个核心解释变量共同影响
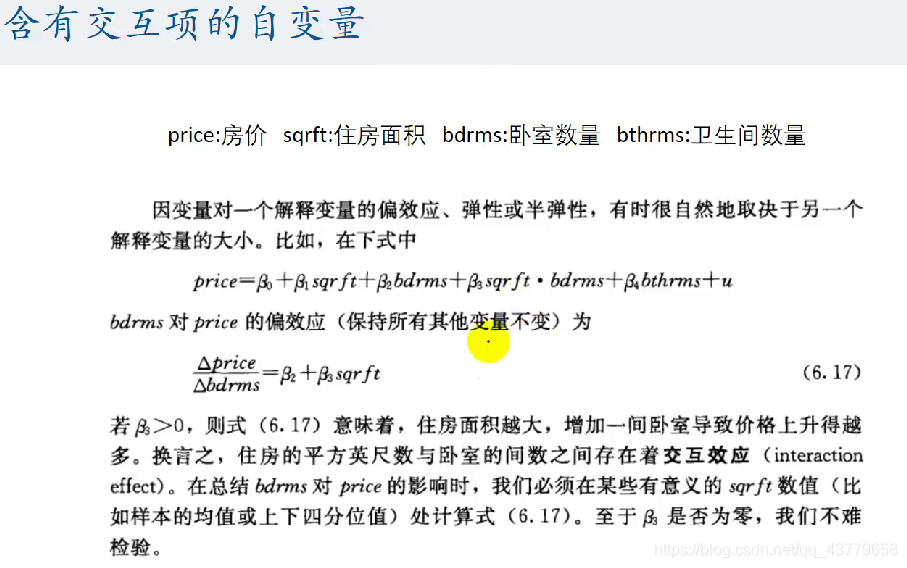
在论文对变量解释介绍
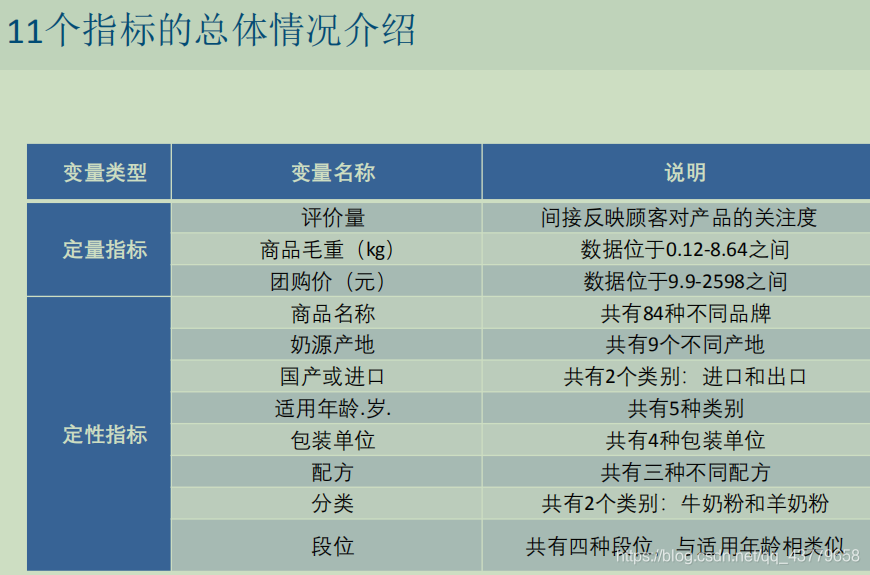
一元线性回归
- 与一元线性函数拟合本质类似
- 仅有一个自变量

Stata对数据描述性统计
定量数据
summarize 变量1 变量2 ... 变量n

- 如果放入论文中,需要先放到Excel中,变成三线表,然后将三线表放到论文中
定性数据 — 生成虚拟变量
// 得到出现的次数(Freq)
tabulate 变量
- 该函数每次仅对一个变量进行分析

tab 变量 ,gen(A)
- 生成对应变量的虚拟变量 A 1... A n A1 ... An A1...An

- 例如图中,有两种配方,有两个虚拟变量
A
1
,
A
2
A1,A2
A1,A2
当为第一种配方的时候, A 1 = = 1 ; A 2 = = 0 A1 == 1 ;A2==0 A1==1;A2==0
当为第二种配方的时候, A 1 = = 0 ; A 2 = = 1 A1 == 0 ;A2==1 A1==0;A2==1
Excel画出变量的频率扇形图
- 插入 -> 数据透视表
- 选择所需字段

可以选择值显示的方式(数字或百分比) - 画出扇形图
分析 -> 数据透视图

-
在图中加入数字

-
为了让画出来的图有美感
可以先进行排序后再画开始 -> 排序
可以进行颜色的变更:页面布局 -> 颜色
Stata 回归 — 分析各个变量与因变量的关系
使用回归前,要检验扰动项是否满足某些条件 — 重点
对定量变量回归
regress y x1 x2 ...

- Model: 代表SSR,回归平方和
- Residual: 代表SSR,误差平方和
- Total: 代表SST
上面三个对应的值在SS列中
-
R-squared: 代表 R 2 R^2 R2,拟合优度
-
0 < = R 2 < = 1 0<=R^2<=1 0<=R2<=1
-
Adj R-squared: 代表调整后的拟合优度

-
df: 代表自由度
联合显著性检验 — P r o b > F Prob>F Prob>F的值看模型是否合理
- P r o b > F Prob>F Prob>F 对应的值要 < 0.05 <0.05 <0.05,否则模型设置不合理

检验回归系数使用的
t
t
t 回归统计量
- Coef: 估计出来的回归系数
- cons: 常数项的估计值
- 最后一列为置信区间
分析的变量选择 — 回归系数显著
只需要分析回归系数显著的变量(看 P > ∣ t ∣ 一 列 P>|t|一列 P>∣t∣一列,当值 < 0.05 <0.05 <0.05代表在 95 % 95\% 95%置信水平下,回归系数显著异于 0 0 0)
回归系数解释

- 在其他变量不变的情况下,团购价元 每增加1,会导致评价量减少35.49873
对定性变量回归
使用tab 变量 ,gen(A)产生的虚拟变量
A
1...
A
n
A1...An
A1...An
再使用regress y A1 A2 ...An
为了避免多重共线性的影响,会自动将某个虚拟变量设置为对照组
例如图中将G4看为对照组:

联合显著性检验 — P r o b > F Prob>F Prob>F的值看模型是否合理
- P r o b > F Prob>F Prob>F 对应的值要 < 0.05 <0.05 <0.05,否则模型设置不合理
图中含义:

检验回归系数使用的 t t t 回归统计量
- Coef: 估计出来的回归系数
- cons: 常数项的估计值
- 最后一列为置信区间
分析的变量选择 — 回归系数显著
只需要分析回归系数显著的变量(看 P > ∣ t ∣ 一 列 P>|t|一列 P>∣t∣一列,当值 < 0.05 <0.05 <0.05代表在 95 % 95\% 95%置信水平下,回归系数显著异于0)
回归系数的解释
例如:
有四个段位,观察段位与评价量的关系
reg 评价量 G1 G2 G3 G4

解释回归系数:
- G1回归系数(Coef对应的那列)
在控制其他变量不变的情况下,段位1与段位4比较,评价量相差 − 7595.045 -7595.045 −7595.045
Stata对回归分析结果用文档保存
regress 评价量 团购价元 商品毛重kg
// 下面的语句可帮助我们把回归结果保存在Word文档中
// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)
// ssc install reg2docx, all replace
// 将模型保存为m1
est store m1
reg2docx m1 using m1.docx, replace
// *** p<0.01 ** p<0.05 * p<0.1
- 注意加上
∗ ∗ ∗ p < 0.01 , ∗ ∗ p < 0.05 , ∗ p < 0.1 *** p<0.01, ** p<0.05, * p<0.1 ∗∗∗p<0.01,∗∗p<0.05,∗p<0.1 - 对生成的文档注意修改字体:
全选后选宋体,再全选后选新罗马字体
Stata标准化回归 — 分析各个变量对因变量的影响程度
- 只关注显著的回归系数
即需要分析回归系数显著的变量(看 P > ∣ t ∣ 一 列 P>|t|一列 P>∣t∣一列,当值 < 0.05 <0.05 <0.05代表在 95 % 95\% 95%置信水平下,回归系数显著异于0)

regress y x1 x2 ... xk, beta

求出的拟合优度 R 2 R^2 R2较低时
0 < = R 2 < = 1 0<=R^2<=1 0<=R2<=1

- 预测性回归需要 R 2 R^2 R2大
- 预测性回归拟合优度低时,使用第二点进行改进
- 解释性回归拟合优度低时,可能为第三点原因
拟合优度和调整后的拟合优度


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









