







目录
一、生成器
二、判别器
三、训练生成器
四、训练判别器
五、在MINIST数据集上运行Conditional-GAN
学习笔记:
GAN是两个敌人之间的战斗:生成器和判别器
- 生成器试图学习数据分布,通过随机噪声作为输入,并产生逼真的图像。
- 另一方面,判别器试图分类样本:来自真实的数据集or假的(由生成器生成)。
生成器
GAN中的Generator是一种神经网络,给定一组随机的值Z(服从多元高斯分布采样),通过一系列非线性计算产生真实的图像。该生成器产生假图像𝑋fak𝑒 。
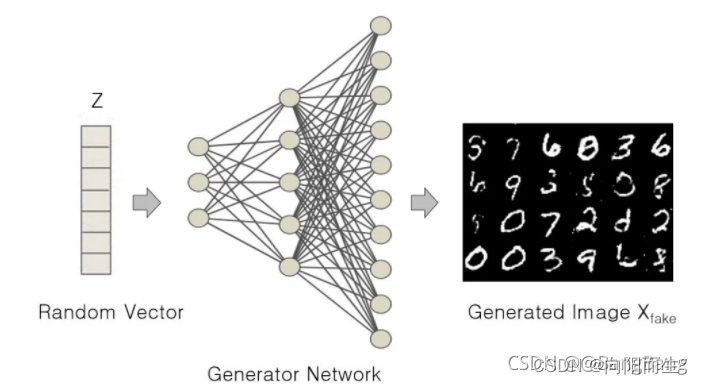
ps:
- 生成器的输入Z服从多元正态分布或高斯分布采样,并生成一个等于原始图像𝑋𝑟𝑒𝑎𝑙大小的输出。

- 和变分自动编码器(VAE)很像
- GAN的生成器的作用很像VAE的解码器,即,将潜在空间投射到图像(在抽象层面上)。
- 但与VAE不同的是,生成器的潜在空间不需要学习高斯分布,(直接从已有的正态分布中采样即)。如果强制执行,GAN虽然可以模拟更复杂的分布,但它们也会遭遇模式崩溃
生成器的作用是:
- 欺骗的判别器
- 产生逼真的图像
- 随着训练过程的完成,实现高性能生成效果
判别器
判别器基于判别建模的概念,它试图用特定的标签对数据集中的不同类进行分类。
因此,在本质上,它类似于一个监督分类问题。
此外,判别器对观察结果的分类能力不仅限于图像,还包括视频、文本和许多其他领域(多模态)。
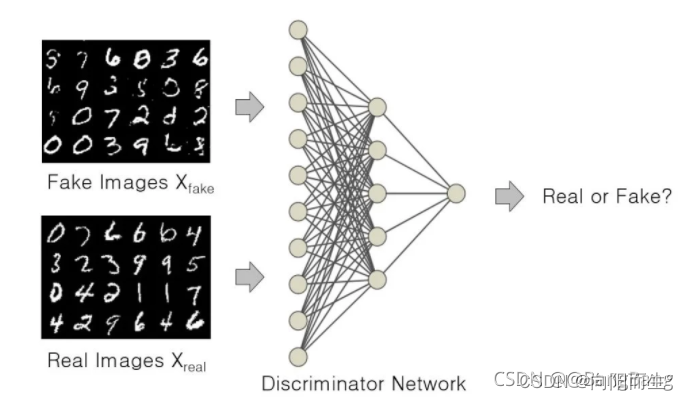
判别器的作用是:
- 解决一个二值分类问题,学习区分真假图像。
- 它是这样做的:
- 预测观察结果是由生成器(假的)生成,还是来自原始数据分布(真实的)。
- 在此过程中,它学习一组参数或权重。随着训练的进行,权重也在不断更新。
- 采用Binary Cross-Entropy(BCE)损失函数对判别器进行训练。
GAN中生成器和判别器的训练是交替进行的
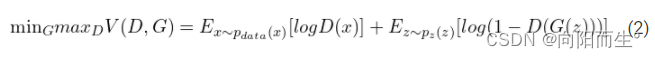
训练生成器:
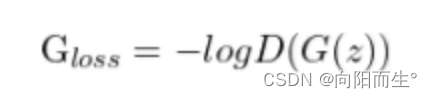
D(G(z)):生成的fake样本Gz被预测为真的概率,(我们希望越大越好)![]()
取负对数:变成loss函数,我们希望loss越小越好(本质上还是D(G(z))越大越好)![]()
生成器(generator)的loss:将判别器返回的对虚假样本的判别结果与1比较

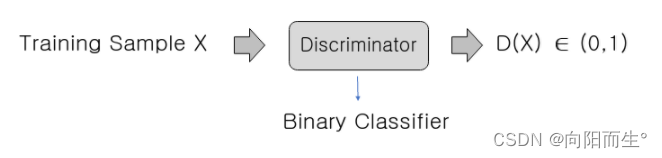
- 判别器(discriminator)是一种二元分类器,给定输入x,它输出的概率为D(x)在0和1之间。
- 概率D(x)更接近1意味着判别器预测输入X为真实图像。
- 接近于0的概率意味着判别器预测输入X是假的。
- 目标:我们希望fake样本最好能骗过判别器,即所有的fake样本被判别器预测的值接近1。
- 所以这里用判别器对fake样本预测的结果与全是1的标签进行比较,是为了计算有多少fake图片被识别出来,
- loss代表了判别器识别出了fake样本为假,loss越高说明生成的图片没有很好的骗过判别器。
- 我们希望被判别器识别出来的图片越少越好,所以要minimize
- 训练生成器的目的是,我们希望生成器生成的图片能尽量骗过判别器(生成的fake样本能被判别器识别为real)
计算出g_loss之后我们可以进行反向梯度传播进行更新

训练判别器(discriminator)
判别器的loss:
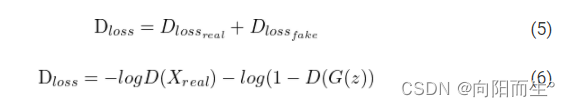
D𝑋𝑟𝑒𝑎𝑙:real样本被预测为真的概率
DGz:fake样本被预测为真的概率
1−DGz:fake样本被预测为假的概率

- Real_loss:用判别器对real样本的判别结果与全是1 的标签计算误差
- 我们希望判别器将real样本识别为真
- Fake_loss:用判别器对fake样本的判别结果与全是0 的标签计算误差
- 我们希望样本能将fake样本识别为假
- 训练判别器的目标是 希望判别器能最好的区分真假样本,所将上面两个loss相加取均值

每训练一轮,生成器生成图片用人工判断一下,看训练的如何
在MINIST数据集上运行Conditional-GAN
如何添加conditonal的信息
生成器(Generator)

在生成器的forward中,需要将标签信息和隐变量concat起来,再送入model,得到生成图片

判别器(discriminator)
在判别器的forward中,需要将标签信息和图像信息concat起来,再送入model,得到预测概率

Conditional GAN最主要的不同就是在生成器和判别器的输入会加上样本的标签(或其它)信息















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









