







目录
4、基于k-means的单被试EEG microstate类别识别流程
6、静息态EEG的Microstate分析与ERP的Microstate分析有哪些差异?
静息态EEG microstate分析对数据的要求
1、静息态
2、电极全脑覆盖且电极数目大于20个
3、数据长度:预处理后最终长度大于3 min(个人经验)
4、对数据质量及预处理的要求:全脑平均参考、各个电极有空间坐标、较高数据质量特别是对坏电极已经进行插补或移除
Global Field Power (GFP): 某个时间点地形图所有电极电压值的标准差,用于描述某个地形图电场的强度。
- 由于计算GFP是依据标准差,而计算标准差时减去了所有电极电压值的均值,故GFP是reference-free的指标。
1、EEG microstate 概述
- 对静息态脑电地形图时间序列进行观察时,发现地形图的拓扑结构不是随着时间而随机或连续变化的。地形图的拓扑结构总是在一定时间内保持相对稳定的状态,之后迅速转换为另一个在一定时间内保持相对稳定状态的拓扑结构 (对ERP 而言,是在某个ERP成分潜伏期内保持相对稳定)
- 在地形图拓扑结构保持相对稳定的时间范围内,地形图的强度(GFP)可能增大或降低、极性也有可能变化,但是地形图的总体拓扑结构保持稳定。
- 这些地形图拓扑结构相对稳定的时间段反映了人脑信息加工的最基本进程,即它们是人类意识的最基本组成模块。他们认为其为“思维的原子”(atoms of thoughts),将其称为脑电的微状态(EEGmicrostates)
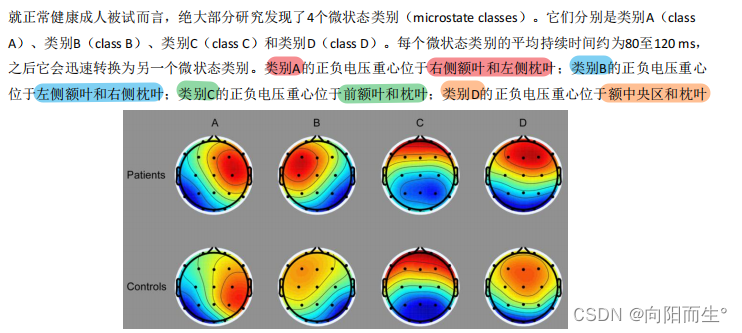
- 四种微状态类别:
- 微状态类别A(Microstate Class A)被发现与双侧颞上回和颞中回的负BOLD激活相关,而上述区域在语音加工中起关键作用。
- 微状态类别B(Microstate Class B)与双侧纹外视觉皮层的负BOLD激活相关。
- 微状态类别C(Microstate Class C)与前扣带回的后部、双侧额下回、右侧前脑岛和左侧屏状核的正BOLD激活相关,而这些脑区在执行控制功能中扮演着极其重要的角色。
- 微状态类别D(Microstate Class D)与额叶和顶叶的右背侧和腹侧区域的负BOLD激活相关
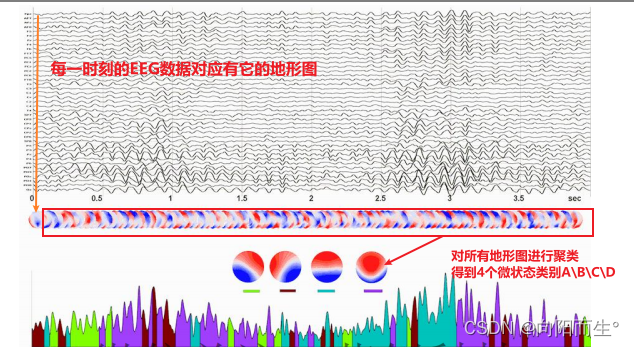
2、EEG microstate 指标体系
1、每个微状态类别的平均持续时间
2、每个微状态类别在一秒的时间内平均出现的次数
3、每个微状态类别的涵盖比例:它指的是每个微状态类别总的持续时间占全部静息态脑电时间长度
4、一个微状态类别向另一个微状态类别的转换概率
由于这四个微状态类别可以认为是“思维的原子”,且每种微状态类别与特定大脑神经加工网络相对应,因此这
些微状态类别的平均持续时间和出现频率与相应心理加工过程对应的平均持续时间和出现频率相一致。一个微状
态类别的平均持续时间过短提示相应的认知加工进程过早地终止了,而如果该微状态类别的出现频率过高,则意
味着相应认知加工过程需要重复更多次以便完成相应的心理加工
3、EEG microstate 识别技术
- 目前EEG microstate识别主流技术是K-means、Atomize & Agglomerate Hierarchical Clustering (AAHC)以及Topographic Atomize & Agglomerate Hierarchical Clustering (T-AAHC)
- Pascual-Marqui等人提出了一种基于K-means聚类算法的微状态模式识别算法 (Pascual-Marqui et al. 1995)。该算法以GMD(Global Map Dissimilarity)作为微状态分类时使用的指标。依据GMD指标,K-means聚类算法可以将GMD较低或者说相关性较高的地形图聚为一类,并可以得到能够最优化解释大部分数据方差的类别数目
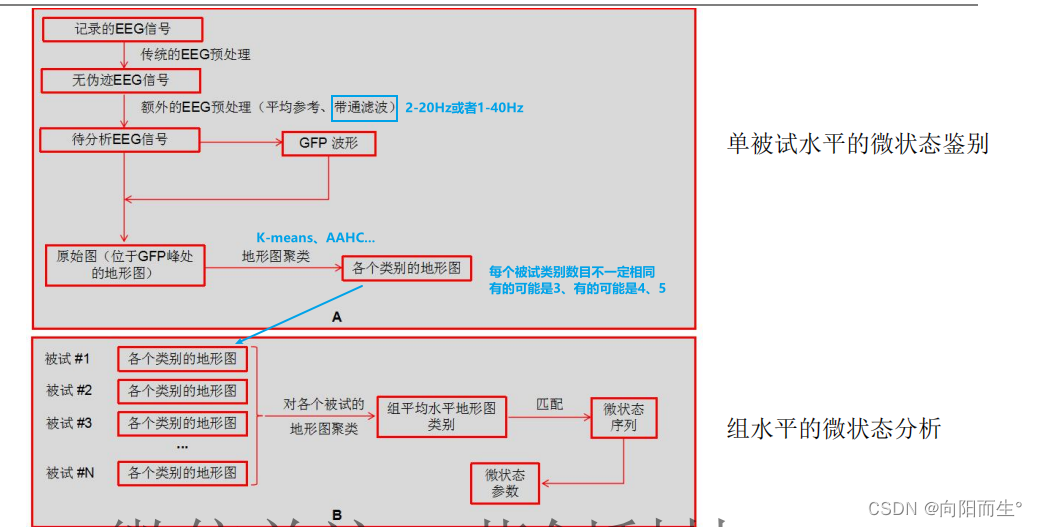
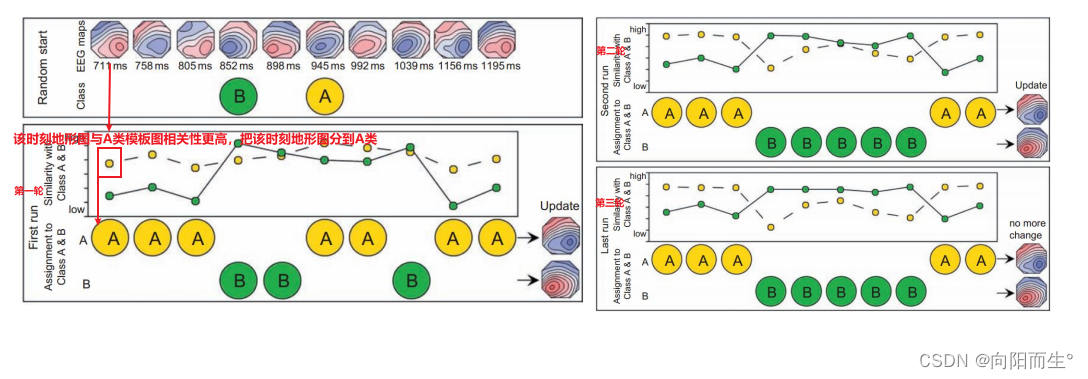
4、基于k-means的单被试EEG microstate类别识别流程

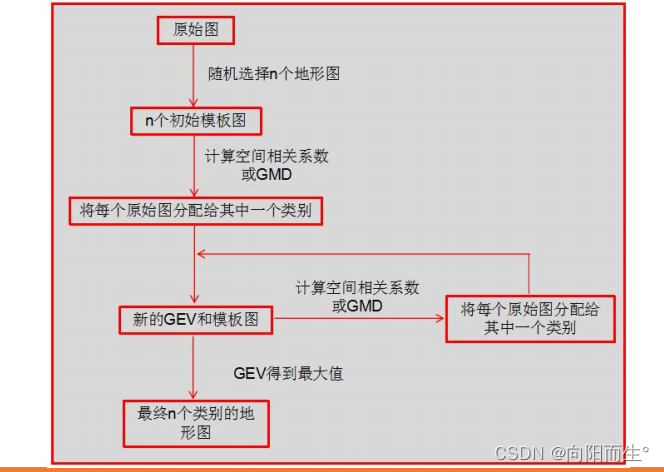
K-means方法步骤如下:
- 1. 假设有n个微状态类别。
- 其中n的最小值为1,最大值可为脑电数据记录时间点数目或地形图总数(实际研究中n 一般小于10)。
- 从所有的位于GFP峰处的地形图(即“原始图”)中随机选择n个地形图作为“初始模板图”(initialprototype maps)。
- 每一个“初始模板图”分别与所有的原始图进行比较,并将每个原始图标分类到与其空间相关系数最大(即GMD最小,忽略地形图极性)的“初始模板图”
- 2. 所有被标记为属于同一个“初始模板图”的原始图叠加平均,得到n个“合成模板图”(synthetic prototype maps)。
- 上述合成模板图的质量可以通过计算“总体方差解释比例”(Global Explained Variance,GEV)得到。
- GEV描述的是,使用上述“合成模板图”解释全部地形图序列时的准确程度。
- 上述合成模板图的质量可以通过计算“总体方差解释比例”(Global Explained Variance,GEV)得到。
- 3. 每一个“合成模板图”分别与所有的原始图进行比较,并将每个原始图标记为属于那个与其空间相关系数最大的“合成模板图”。
- 所有被标记为属于同一个“合成模板图”的地形图叠加平均,得到n个新的“合成模板图”,并得到新的“总体方差解释比例”(GEV)
- 4. 重复第3步,直至GEV不再增加(数值为70%-90%,小于70%噪音比较大)(或达到预先设定的迭代次数)
- 5. 重新选取一个微状态类别数目,并进行上述迭代过程(第1步~第4步)。
- 实际的研究中微状态类别数目最小为1,最大为10
- 6. 进行完上述不断重复的迭代过程之后,研究者需要确定最优的微状态类别数目。
- Pascual-Marqui等人提出可以使用一个交叉验证准则(cross-validation criteria)来实现总体方差解释比例和自由度(the degrees of freedom)之间的平衡 (Pascual-Marqui et al. 1995)。
- 其他研究者则建议使用Krazanowski-Lai准则(Krazanowski and Lai criterion)来确定最优化的微状态类别数目 (Murray et al. 2008)
- 有的文献亦强制分为4类
- 7. 通过计算鉴别出的微状态地形图与每个时间点的地形图的空间相关系数(或GMD),确定每个时间点地形图的微状态归属(也可只计算微状态地形图与GFP峰处地形图的空间相关系数或GMD)
流程图:
- 1. 【迭代终止】随着迭代的进行,GEV不再增加或达到预定的迭代次数时,迭代终止
- 2.【初始值K的选择】 假设地形图类别数目为K时,第一步是从T个原始图中随机选择K个地形图作为“初始模板图”。
- 为避免初始值敏感问题,对于K取的每一个数值,都需将上述K-means过程重复上百次(如200 次),并从中选择GEV最高的那次结果
- 由于事先并不知晓类别数目,且一般假定K最高为10,所以需要将上述过程在K =2、K= 3直至K = 10时进行重复(K = 1无意义,不需要进行迭代)。
- 因此假设K最高为10且K取某一数值时上述完整的k-means过程需要重复200次,总共需要进行1800(200*9)次迭代.
- 4. 完成上述分析后,需要确定地形图类别数据------- 可依据某些准则或强制分为4类
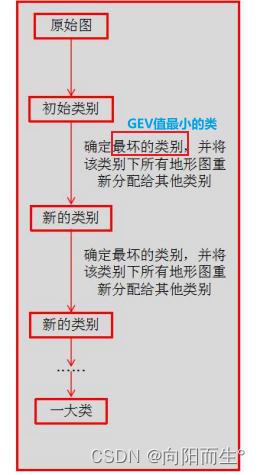
AAHC和T-AAHC
- AAHC和T-AAHC是由 Hierarchical Clustering发展而来的
- 首先假定每个原始图各为一个类别(cluster), 找到“总体方差解释比例”(GEV)最小的那个“类别”,认为它与和它相关系数最高的“类别” 属于一类。
- 在剩余的“类别”中找到“总体方差解释比例”最小的那个“类别” 。
- 假如这个”类别“有多个地形图,则分别计算其中每个地形图与剩余地形图的相关系数,并将每个地形图归属与与其相关最高的”类别“。
- 可见,每次循环迭代,”类别“数目就将降低一个,直至最终只有一个”类别“。
- AAHC和T-AAHC的区别是AAHC考虑到了地形图的强度,T-AAHC则没有考虑这一点。
- 一般上述三种方法K-means、AAHC、T-AAHC之间的差异不是很大(特别是信噪比较好的数据)。K-means由于要运行几十次,故比较耗时;而AAHC和T-AAHC运行较快
组水平的微状态分析
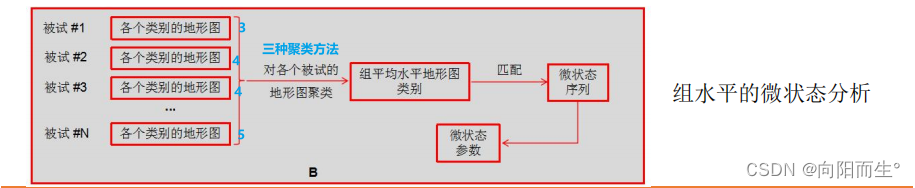
得到组平均水平的地形图后,确定每个时间点属于何种地形图类别
ü 方法一:
① 对每个被试而言,分别计算其每个时间点地形图与组平均水平地形图的空间相关系数(忽略地形图极
性、相关系数取绝对值);
② 认为每个时间点属于与其空间相关系数最高的地形图类别;
③ 平滑操作
ü 方法二:
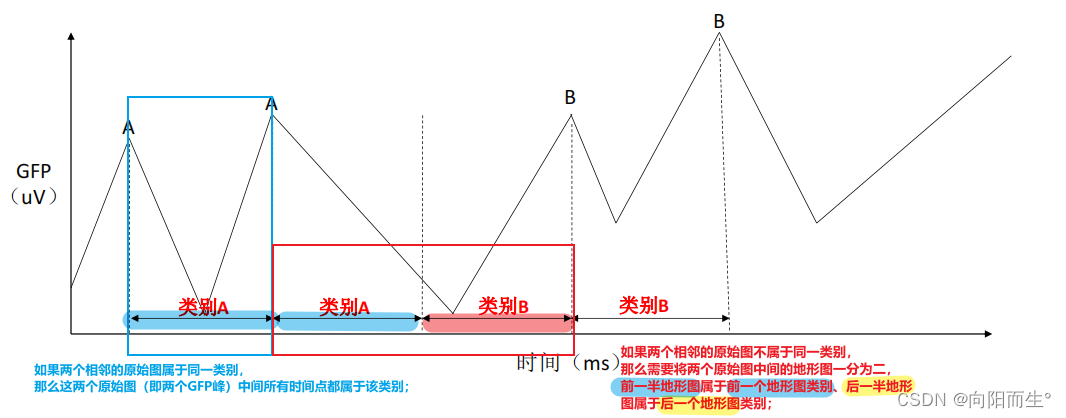
① 对每个被试而言,分别计算其每个原始图(即GFP峰处地形图)与组平均水平地形图的空间相关系数 (忽略地形图极性、相关系数取绝对值),进而确定每个原始图所属地形图类别;
② 如果两个相邻的原始图属于同一类别,那么这两个原始图(即两个GFP峰)中间所有时间点都属于该类别;
② 如果两个相邻的原始图不属于同一类别,那么需要将两个原始图中间的地形图一分为二,前一半地形图属于前一个地形图类别、后一半地形
图属于前一个地形图类别;
③ 平滑操作
5、EEG microstate 总结
- 1、聚类的方法:K-means、Atomize & Agglomerate Hierarchical Clustering (AAHC)以及Topographic Atomize & Agglomerate Hierarchical Clustering (T-AAHC)
- 2、如何确定地形图类别的数目:(1)强制为4个;(2)使用特定准则判断最优类别数目
- 3、可得到哪些指标:
- (1)每个地形图类别(Class A、B、C和D)的平均持续时间(单位 毫秒);
- (2)每个地形图类别单位时间内出现的次数(单位 次/秒);
- (3)每个地形图类别的涵盖时间百分比(单位 %);
- (4)四个地形图类别之间相互转换的概率
- 4、如何确定聚类得到的四个地形图反映的是哪些大尺度功能网络:
- (1)对地形图进行源定位;
- (2)借助任务操纵确定;
- (3)前人的研究结论,如Britz et al. (2010)
- 5、如何解释各个指标在组别/条件之间的变异?
- 提供精神/神经疾病的生理指标:对于不同的疾病而言,一个较为一致的发现是:相对正常健康被试而言,罹患上述疾病的病人某些微状态类别的持续时间变短,而另一些微状态类别的出现频率则增加。但是,对于不同的神经心理疾病而言,出现上述变化的静息态脑电微状态也不相同。例如,通过对近15年来的精神分裂症静息态脑电微状态研究进行元分析,研究者发现精神分裂症患者微状态类别C的出现频率更高、微状态类别D的平均持续时间更短 (Rieger et al. 2016)。而对额颞痴呆患者进行的研究则发现,相对正常健康被试而言,额颞痴呆导致微状态类别C的平均持续时间变短
- 提供刻画不同群体脑活动差异的生理指标
- 提供刻画同一个人在不同实验条件下脑活动差异的生理指标
6、静息态EEG的Microstate分析与ERP的Microstate分析有哪些差异?
• 1、地形图的极性
• 2、选取所有时刻点的地形图?GFP峰处的地形图
• 3、Microstate class的数目及其意义
• 4、可提供的指标的差异
• 5、滤波的差异

















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









