







目录
前言
时域领域的特征提取主要思想:
某个一小段时间段里面的幅值,可能可以明显区别不同的类别,那么我们的目的就要找出这一小个时间段。然后取出这个小的时间段的波幅(求平均),来作为这个数据的特征之一。
数据说明:
被试01,C类别的数据(01_lxx_task_combine_maker_selectC._2s):
每个被试每个类别的数据的维度是 chan*t*epoch,其中chan是通道数,t是时间点,epoch是分段数。
特征提取的步骤
一、个体水平的叠加平均
沿着数据的分段叠加平均, 由chan*t*epoch得到chan*t
二、组水平的叠加平均
1、读出所有被试,C类别的数据(我自己复制的,假装有3个被试,分别是01、02、03)

被试01 chan*t*epoch
被试02 chan*t*epoch
被试03 chan*t*epoch
2、先对每一个被试的类别C的数据,分别进行个体间叠加平均,得到
被试01 chan*t
被试02 chan*t
被试03 chan*t
3、把第2步中所有被试的数据收集起来,得到 sub*chan*t 维度的数据。
ps:这一步得到的是所有被试,类别C,进行个体间叠加平均后的数据。
4、对上一步得到的数据,沿着sub维度进行组水平叠加平均,sub*chan*t ---> chan*t
对类别N、类别N、类别R、的数据也进行组水平的叠加平均(上述1-4的步骤)
这样我们就得到
类别C的组水平叠加平均后数据 chan*t
类别N的组水平叠加平均后数据 chan*t
类别R的组水平叠加平均后数据 chan*t
类别S的组水平叠加平均后数据 chan*t
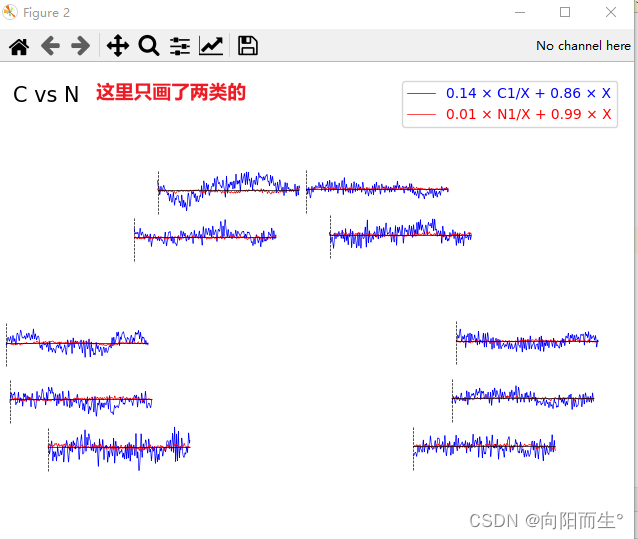
绘制这四个数据的波形图
(因为只是在测试,我只先搞了两个类别的数据,类别C和类别N的,类别C是蓝线,类别N是红线)
为啥10个波形图呢?因为10个位置对应10个通道
对类别C和类别N的数据进行T检验
这一步是为了找出不同类别之间,有显著区别的时间区间。
以便于后边提取这个时间段内的幅值,作为一个可以显著区别不同类别的特征
ps:这边是不是要对四个类别进行两两T检验,以找出四个类别间有显著区别的区间,我还不知道。
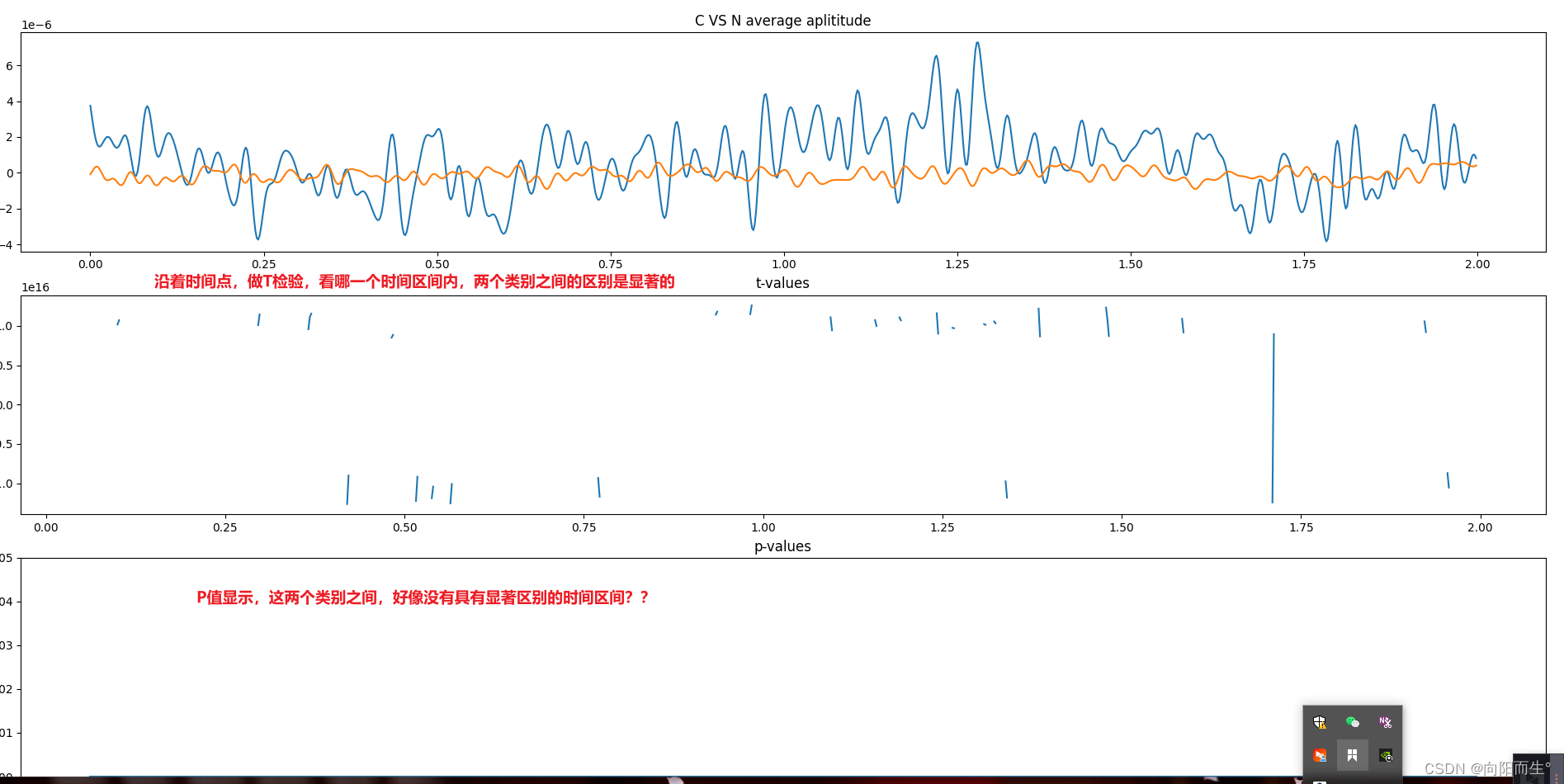
假设我在上面的图中找到的,类别间有显著区别的时间区间有两个,
分别是t1: 0.25s-0.5s,以及t2:1.25s-1.75s
我就把所有类别的数据,在进行组水平的叠加平均的第3步后得到的数据,t1、t2时间区间的数据取出来。
得到
sub*chan*t1、sub*chan*t2(类别C)
sub*chan*t1、sub*chan*t2(类别N)
sub*chan*t1、sub*chan*t2(类别R)
sub*chan*t1、sub*chan*t2(类别S)
对它们在时间上进行平均,得到
sub*chan、sub*chan(类别C)
sub*chan、sub*chan(类别N)
sub*chan、sub*chan(类别R)
sub*chan、sub*chan(类别S)
ps:这里假设,sub有三个被试,chan有10个通道,则sub*chan实际上是3x10维。一个类别有两个时间段的数据
对各个类别的时间段进行拼接得到
sub*(chan+chan)(类别C) 3x20维
sub*(chan+chan)(类别N) 3x20维
sub*(chan+chan)(类别R) 3x20
sub*(chan+chan)(类别S) 3x20
再沿着不同类别拼接

变成 (3个被试的C+3被试的N+3个被试的R+3个被试的S)*20,
也就是12*20维
现在时域已经有20个特征了
三、附上代码
# 引入必要的模块
import numpy as np
import matplotlib.pyplot as plt
import mne
import pickle
from scipy import stats
data_path = r'C:\Users\Dell\Desktop\脑电数据机器学习\数据结果\step6_reextract_data\01_lxx_task_combine_maker_selectC._2s.set'
eeg1 = mne.io.read_epochs_eeglab(data_path,uint16_codec='latin1') #通过“.”调用下层函数
avgs = eeg1.average() #对所有分段进行叠加平均
print(avgs)
from mne.viz import plot_evoked_topo
# 指定两个条件用什么颜色以及什么名称绘制
colors = 'red'
title = '01-lxx-C'
# 绘制波形图 所有的通道一次性显示 按照通道位置排列
plot_evoked_topo(avgs, color=colors, title=title, background_color='w')
plt.show()
avgs.plot_topomap(times=[0.5,1.5], size=3.,time_unit='s',average = 0.02)
# group_average
# 定义数据所在路径
Example_path = 'C:/Users/Dell/Desktop/脑电数据机器学习/数据结果/test/'
# 定义两个空列表方便储存后续的数据
c1_all = []
c2_all = []
# 对于每个被试
for i in range(1,4): #遍历所有被试
# 拼接完整的路径以及文件名称
filename1 = Example_path +str(0) + str(i) + '_lxx_task_combine_maker_selectC._2s.set'
filename2 = Example_path +'/N/'+str(0) + str(i) + '_lxx_task_combine_maker_selectN._2s.set'
# data1读取类别C的数据 data2读取类别N的数据
data1 = mne.read_epochs_eeglab(filename1,uint16_codec='latin1')
data2 = mne.read_epochs_eeglab(filename2, uint16_codec='latin1')
# 分别提取两个类别的数据,并进行叠加平均
c1 = data1.average() #对被试i的类别C的数据的 所有分段 进行 叠加平均 chan*t*epoch -> chan*t
c2 = data2.average() #对被试i的类别N的数据的 所有分段 进行 叠加平均
# 把所有被试的叠加平均好的数据 累积
c1_all.append(c1)
c2_all.append(c2)
# 提取每个叠加平均好的对象的脑电数据 放在一个列表中
c1_all_list = [c1.data for c1 in c1_all] # sub*chan*t
c2_all_list = [c2.data for c2 in c2_all]
# 将列表中每个列表的数据值进行拼接 沿着以一个维度---> sub * ch * t
all_c1 = np.stack(c1_all_list, axis = 0)
all_c2 = np.stack(c2_all_list, axis = 0)
# 组水平的叠加平均 沿着all_c1的第一个维度 即被试的维度做平均
# 3d sub* ch * t ---> ch * t
mean_c1 = np.mean(all_c1, axis=0) #所有C类别的 被试间叠加平均
mean_c2 = np.mean(all_c2, axis=0) #所有N类别的 被试间叠加平均
# 由于使用mne绘图要用到特定的对象 而mean_l3只有电压值 是数组
# 复制l3_all中的第一个数据的类型
mean_c1_obj = c1_all[0].copy()
# 并将电压值替换为组水平叠加平均过的电压值
mean_c1_obj._data = mean_c1
mean_c2_obj = c2_all[0].copy()
mean_c2_obj._data = mean_c2
# 绘制组水平波形图
mean_evoked = [mean_c1_obj,mean_c2_obj]
colors = 'blue', 'red'
title = 'C vs N'
plot_evoked_topo(mean_evoked, color=colors, title=title, background_color='w')
# 绘制组水平的地形图
mean_c1_obj.plot_topomap(size=3)
mean_c2_obj.plot_topomap(size=3)
# 假如最感兴趣的是12号通道
index_ch = 3
# all_L3 sub*ch*t
# 提取所有被试 12号通道 所有时间的数据
# Cz_L3 sub*t
Cz_c1 = all_c1[:,index_ch,:]
Cz_c2 = all_c2[:,index_ch,:]
# 提取时间点个数的信息
time_num = Cz_c1.shape[1]
# 构造目标维度的空数组
tvals_time = np.empty((time_num))
pvals_time = np.empty((time_num))
# 对于每个时间点
for i in range(time_num):
# 分别提取所有被试 第i个时间点的数据 ---> sub
data1 = Cz_c1[...,i]
data2 = Cz_c2[...,i]
# 在第i个时间点下进行两个条件的配对样本t检验
[stat, p] = stats.ttest_rel(data1,data2)
# 储存每个时间点下的t值和p值
tvals_time[i] = stat
pvals_time[i] = p
# 提取每个采样点下的时间信息(绘图的横轴)
t = mean_c2_obj.times
# 绘制三行一列的第一个图 绘制两个条件下的总平均波形
plt.subplot(311)
# mean_L3 ch * t
plt.plot(t, mean_c1[3,:])
plt.plot(t, mean_c2[3,:])
plt.title("C VS N average aplititude")
plt.subplot(312)
# t值
plt.plot(t,tvals_time)
plt.title("t-values")
plt.subplot(313)
# p值 看一下两个条件存在显著性差异的时间区间
plt.plot(t,pvals_time)
plt.ylim((0, 0.05))
plt.title("p-values")
plt.show()
# 只是看哪个区间显著差异,无需多重比较校正
# 找到感兴趣的时间范围内的采样点的位置信息
index_t1 = [i for i in range(len(mean_c2_obj.times)) if 1<= mean_c2_obj.times[i] <= 1.75] #感兴趣的时间段1
# 提取所有被试 所有通道 感兴趣时间范围内的数据
# 再沿着第三个维度即时间的维度做平均 ---> sub*ch
troi1_data_c1 = np.mean(all_c1[:,:,index_t1],axis=2)
troi1_data_c2 = np.mean(all_c2[:,:,index_t1],axis=2)
index_t2 = [i for i in range(len(mean_c1_obj.times)) if 0.364<= mean_c2_obj.times[i] <= 0.384] #感兴趣的时间段2
troi2_data_c1 = np.mean(all_c1[:,:,index_t2],axis=2) #sub*ch
troi2_data_c2 = np.mean(all_c2[:,:,index_t2],axis=2)
# 先分别对每个条件的不同特征进行横向拼接 沿着第二个维度进行拼接-->sub*(ch+ch)
c1_erp_all = np.concatenate((troi1_data_c1,troi2_data_c1), axis=1)
c2_erp_all = np.concatenate((troi1_data_c2,troi2_data_c2), axis=1)
# 对不同条件的数据进行拼接 沿着第一个维度进行拼接(行)---> (sub c1+sub c2)*ch(N2 59 P2 59)
erp_features_all = np.concatenate((c1_erp_all,c2_erp_all), axis=0)
# 储存数据
output1 = open('erp_features_all.dat','wb')
pickle.dump(erp_features_all, output1)
output1.close()

















 4514
4514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









