






 本文介绍了深度学习在图像传输中的应用,提出DeepJSCC联合信源信道编码方案,以解决传统方法中的“悬崖效应”。通过神经网络模型,直接将图像映射为信道输入,从而在低信噪比环境下仍能保持良好性能,并在中高压缩率下优于传统通信系统。此外,这种方法还降低了计算复杂度。
本文介绍了深度学习在图像传输中的应用,提出DeepJSCC联合信源信道编码方案,以解决传统方法中的“悬崖效应”。通过神经网络模型,直接将图像映射为信道输入,从而在低信噪比环境下仍能保持良好性能,并在中高压缩率下优于传统通信系统。此外,这种方法还降低了计算复杂度。
本文是基于深度学习图像传输语义通信系统的经典论文,后续很多论文都是在此基础上进行扩展,既在此论文的基础上添加一些新的方法。
(1)基于分离的数字传输方案。
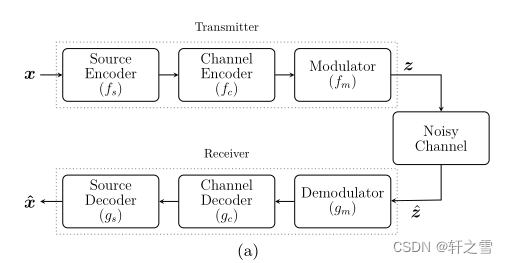
图(1) 传统图像传输方案
分离模型主要由三部分组成,分别是发送端,物理信道,接收端三部分组成。其中发送端由信源编码,信道编码和调制三部分组成。信源编码用于去除图像中的冗余信息(常用的图像信源编码为JPEG,JPEG2000,WebP等),接着对编码后的图像进行信道编码(霍夫曼编码,LDPC编码,Turbo编码等),信道编码后图像变为比特流,最后把比特流传进调制器,调制编码后传入物理信道。接收端则于发送端对称,执行相应的解调,信道译码,信源译码最后恢复图像。恢复后的图像与传输前的图像进行对比,通过均方误差,峰值信噪比,结构相似性等对图像进行评价。
传统图像传输会出现一个显著的缺陷:“悬崖效应”,悬崖效应是指当信道条件在低于某阈值时,性能会急剧下降直到最差水平。
(2)基于深度学习联合信源信道编码(Deep JSCC)
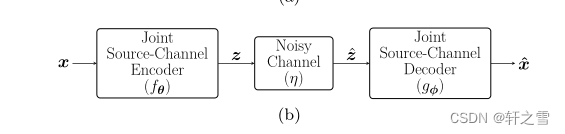
图(2)联合信源信道编码方案
Deep JSCC提出一种用于联合信源信道的编码方案。模型主要由三部分组成分别为发送端,物理信道,接收端。其中发送端通过神经网络联合训练信源信道编码,接收端也是由神经网络组成。整个模型通过训练神经网络得到全局最优解。Deep JSCC模型并不进行比特流 的传输,而是将图像映射为隐含变量z,然后将隐含变量恢复为输出图像。
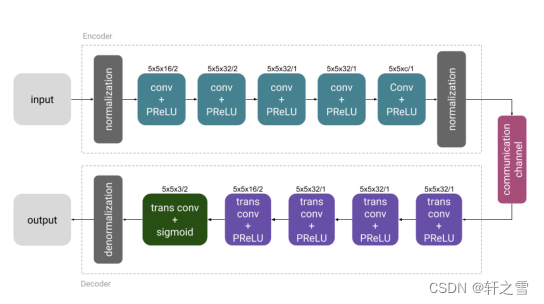
图(3)神经网络的联合信源信道编码模型
从图中可以看出图像模型由连部分组成,编码器和和解码器都是由卷积神经网络组成。具体的参数由上图所示。
具体代码如下所示:
class Encode(tf.keras.Model):
def __init__(self, c):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(filters=16, kernel_size=[5, 5], padding='same',
activation=tf.nn.relu, strides=2)
self.conv2 = tf.keras.layers.Conv2D(filters=32, kernel_size=[5, 5], padding='same',
activation=tf.nn.relu, strides=2)
self.conv3 = tf.keras.layers.Conv2D(filters=32, kernel_size=[5, 5], padding='same',
activation=tf.nn.relu, strides=1)
self.conv4 = tf.keras.layers.Conv2D(filters=32, kernel_size=[5, 5], padding='same',
activation=tf.nn.relu, strides=1)
self.conv5 = tf.keras.layers.Conv2D(filters=c, kernel_size=[5, 5], padding='same',
activation=tf.nn.relu, strides=1)
def call(self, input):
x = self.conv1(input)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
output = self.conv5(x)
return output
class Decode(tf.keras.Model):
def __init__(self):
super().__init__()
self.dconv1 = tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=(5, 5), padding='same',
activation=tf.nn.relu, strides=1)
self.dconv2 = tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=(5, 5), padding='same',
activation=tf.nn.relu, strides=1)
self.dconv3 = tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=(5, 5), padding='same',
activation=tf.nn.relu, strides=1)
self.dconv4 = tf.keras.layers.Conv2DTranspose(filters=16, kernel_size=(5, 5), padding='same',
activation=tf.nn.relu, strides=2)
self.dconv5 = tf.keras.layers.Conv2DTranspose(filters=3, kernel_size=(5, 5), padding='same',
activation=tf.nn.sigmoid, strides=2)
def call(self, input):
x = self.dconv1(input)
x = self.dconv2(x)
x = self.dconv3(x)
x = self.dconv4(x)
output = self.dconv5(x)
return output最后对图像的峰值信噪比和结构相似性进行比较。可以得出以下结论:
(1)所提模型可以克服“悬崖效应”,既在低信噪比环境下也能保持很好的性能。
(2)同时在中等压缩率和高信噪比下,所提模型的也远远高于传统通信系统,即使在高压缩率下也有一定的竞争力。
(3)相比于传统图像传输计算复杂度具有一定优势。
总结:
本文提出了一种新的深度JSCC架构,用于无线信道上的图像传输。在该架构中,编码器将输入图像直接映射到通道输入。编码器和解码器功能被建模为互补的CNN,并在数据集上联合训练,以最小化重建图像的平均MSE。将这种深度JSCC方案的性能与传统的基于分离的数字传输方案进行了比较,后者采用了广泛使用的图像压缩算法,然后是容量捕获信道码。本文通过大量的数值模拟表明,深度JSCC优于基于分离的方案,尤其是在有限的信道带宽和低SNR情况下。更重要的是,深度JSCC被显示为随着信道SNR而提供重构质量的优雅退化。然后,当在慢衰落信道上进行通信时,该观察结果被用于受益于所提出的方案;deep JSCC在所有平均SNR值下都表现得相当好,并且在任何信道带宽值下都优于所提出的基于分离的传输方案。在基于DL的JSCC的情况下,编码器和解码器网络不仅学会了在信道上可靠地通信,而且学会了有效地压缩图像。对于没有噪声的完美信道,如果源带宽大于信道带宽,即n>k,则编码器-解码器NN对等效于欠完全自动编码器,其有效地学习训练数据集的最显著特征。


















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











