







目前初步接触到的作用:
降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter(1 * 1 * 100)上做1*1的卷积,那么结果的大小为500 * 500 * 20。
升维同理。
深度学习中,卷积本质上是对信号按元素相乘累加得到卷积值:
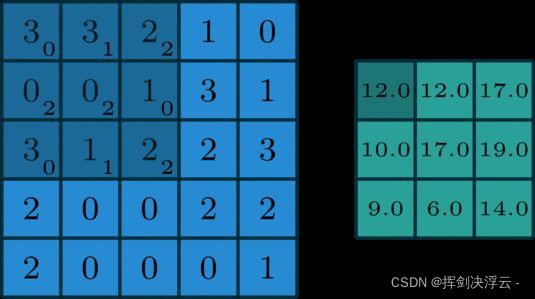
卷积:多通道形式
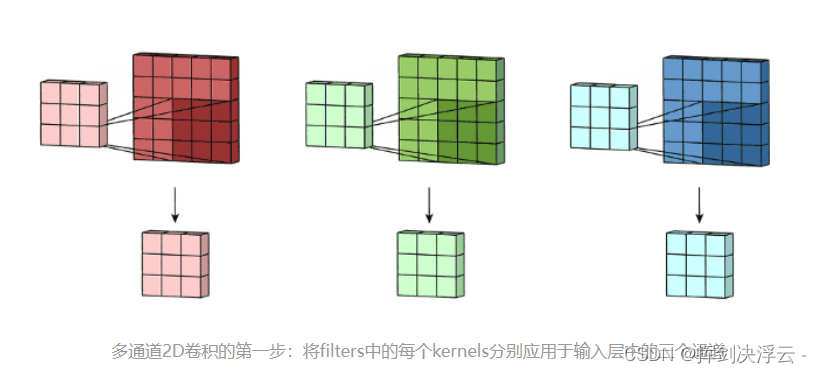
一个5 x 5 x 3矩阵,有3个通道,filters是3 x 3 x 3矩阵。首先,filters中的每个kernels分别应用于输入层中的三个通道,执行三次卷积,产生3个尺寸为3×3的通道:
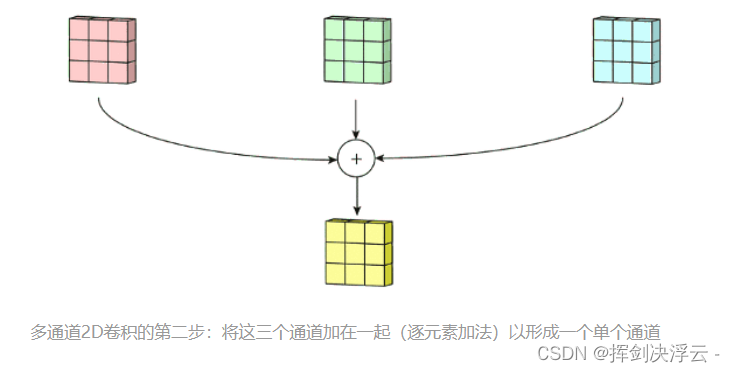
将这三个通道相加(逐个元素相加)以形成一个单个通道(3 x 3 x 1),该通道是使用filters(3 x 3 x 3矩阵)对输入层(5 x 5 x 3矩阵)进行卷积的结果:
可以将这个过程视作将一个3D-filters矩阵滑动通过输入层。注意,这个输入层和filters的深度都是相同的(即通道数=卷积核数)。
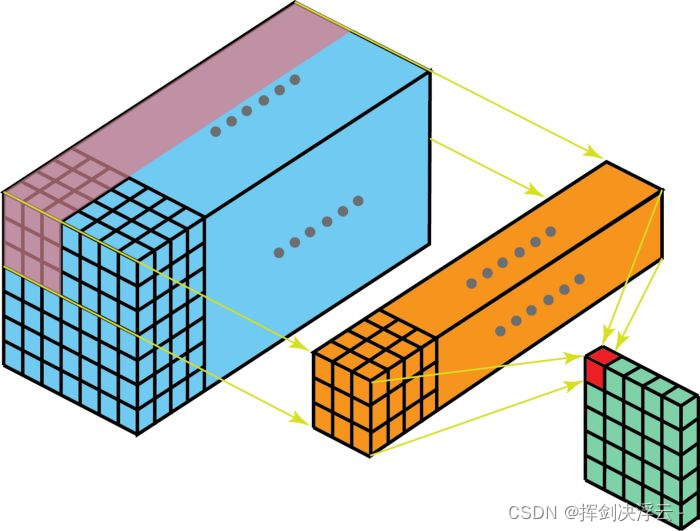
现在我们可以看到如何在不同深度的层之间实现过渡,假设输入层有 Din 个通道,而想让输出层的通道数量变成 Dout,我们需要做的仅仅是将 Dout个filters应用到输入层中。每一个filters都有Din个卷积核,都提供一个输出通道。在应用Dout个filters后,Dout个通道可以共同组成一个输出层。标准 2D-卷积,通过使用 Dout 个filters,将深度为 Din 的层映射为另一个深度为 Dout 的层:
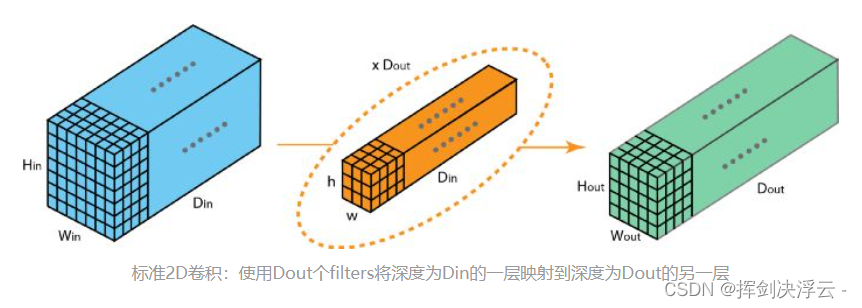
可以看出,当卷积核宽高为1*1时,我们只需要控制卷积核的个数就可以实现对输入信息通道数的控制,起到改变维度的作用,可以改变feature maps的channel数目。
本文图片来源:知乎@初识CV
这位大佬讲得很详细
https://www.zhihu.com/question/56024942/answer/1850649283















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











