






目录
一、前言
作为一名在校计算机烟酒生,深感师兄就业形势之严峻,我开始慌了,想着多水一些比赛来写写简历,提高自己的就业竞争力吧。
两年前做副业接到一个大学生单子,python进行数据分析,要在两小时内写给她,她要写文档,然后和她成为朋友,通过她了解了这个比赛,泰迪杯。
个人感觉这种比赛非常锻炼能力,在八个小时内对相关的数据进行分析求解并撰写解题报告提交,首先是锻炼数据分析的解题能力,然后锻炼AI工具运用能力(许多代码你要让AI帮你写)、还有就是文档编辑能力、团队协作能力(我负责代码编写调试,感谢我的队友,两个小姐姐对我很信任,并且完成了几乎所有文档撰写功能)。
个人还是非常推荐这个比赛的,我第一次参加,参赛队伍接近一千六百支队伍,总获奖率百分之四十(一等前8%,二12%-20%,三等20%-40%),最终我们队B题用了接近六小时,取得了二等奖这个结果,也是非常意外,下面我将对本次比赛的数据、问题、解题过程根据我们所撰写的结果文档做一个分享。
二、原题分析
2.1、研究背景与意义
特殊医学用途配方食品简称特医食品,是指为满足进食受限、消化吸收障碍、代谢紊乱或者特定疾病状态人群对营养素或者膳食的特殊需要,专门加工配置而成的配方食品,包括 0 月龄至 12 月龄的特殊医学用途婴儿配方食品和适用于 1岁以上的特殊医学用途配方食品。在降低死亡率、减少并发症、提升患者生活质量、缩短住院时间、降低医疗费用等方面起到重要作用,是为特殊医学状况人群开的“小灶”。特殊医学用途配方食品为全年龄段人群提供针对性营养支持,作为现代医疗保健体系中不可或缺的一部分,其弥补了传统饮食在特殊医疗需求前的不足,对整个医疗公共卫生领域产生了深远影响。
特殊医学用途配方食品在生产和销售前需要经过严格的审批和注册过程,包括安全性、有效性的评估。所以在我国对于特殊医学用途配方食品的审核有着非常严格的规定。截至 2024 年 4 月,国内仅审批通过了 182 款特医食品(含已注销)。分析 182 款特医食品的相关信息,统计特医食品生产概况并可视化,对特医食品产业发展现状不断完善及其治理意义重大。
2.2、问题重述
2.2.1、预期目标
对我国目前 182 款特殊医学用途配方食品(含已注销)的相关信息进行整理、统计和分析。具体目标如下:
1. 提取 182 款特殊医学用途配方食品产品标签、说明书(以下简称特医食品说明书)中的相关数据及 data.xlsx 数据进行预处理。
2. 统计 182 款特医食品生产概况并可视化。
3. 构建特医食品推荐系统。
2.2.2、任务要求
任务一:数据预处理
a) 读取 182 款特医食品说明书,按照表 1 的要求提取【营养成分表】中“每 100kJ”列的指定营养成分数据,将提取的数据保存到文件“result1.xlsx”中,同时在报告中列出每 100kJ(千焦)中蛋白质含量最高的三种特医食品(注意营养成分的单位)。注:格式见表 1;若该特医食品没有对应营养成分,填充为 0。PDF截图如下:
打开其中一个,截图如下:
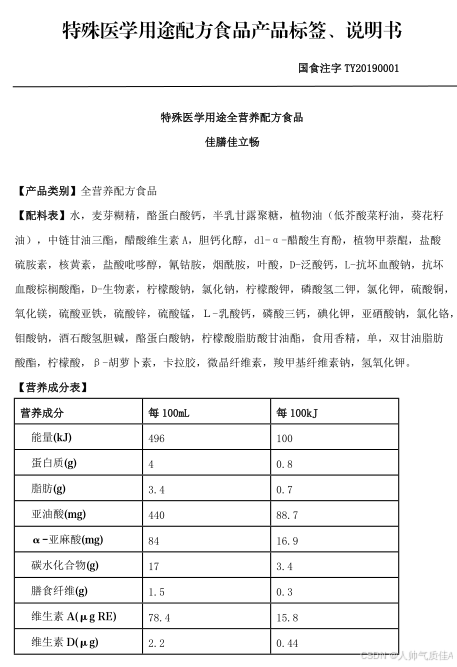
表1截图如下:
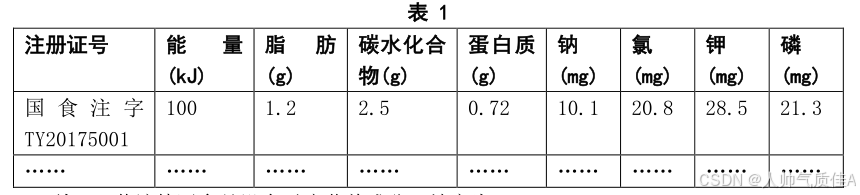
b) 提取 182 款特医食品说明书中【产品类别】、【组织状态】、【适用人群】的数据,在 data.xlsx 数据中新增“产品类别”、“组织状态”、“适用人群”三列并将提取的数据保存到文件“result2.xlsx”中,同时在报告中列前 5 款特医食品的结果(须说明特殊情况的处理)。注:格式见表 2;若该特医食品没有对应信息,留空即可。表2截图如下:
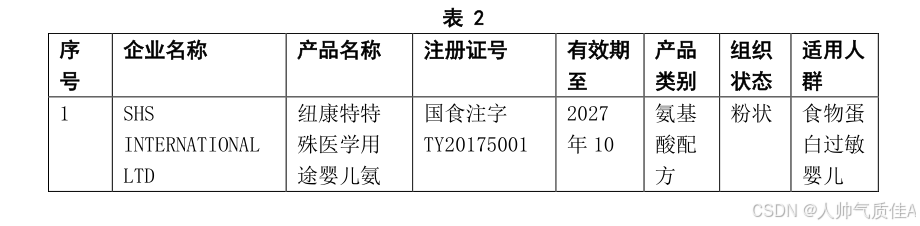
c) 根据提取的【适用人群】信息,在 result2.xlsx 中新增“适用人群类别”列,对 182 款特医食品的适用人群进行归类,类别分为“特医婴配食品”和“1岁以上特医食品”两种,将结果保存到文件“result2.xlsx”中。注:“特医婴配食品”是针对 0-12 月龄人群的特殊医学用途配方食品,“婴儿”特指 0-12 月龄人群。
d) 特殊医学用途配方食品注册号的格式为:国食注字 TY+4 位年号+4 位顺序号,顺序号第 1 位数字为“5”表示该食品为进口产品,顺序号第 1 位数字为“0”表示该食品为国产产品;4 位年号为该食品的登记年份。基于任务 1.3 的result2.xlsx 文件,新增“产品来源”和“登记年份”两列,提取 182 款特医食品的产品来源和登记年份数据,其中产品来源分为“国产产品”和“进口产品”两种并以表 3 的格式将结果保存到文件“result2.xlsx”中,同时在报告中列出前 5 款特医食品任务 1.3和任务 1.4 的结果。
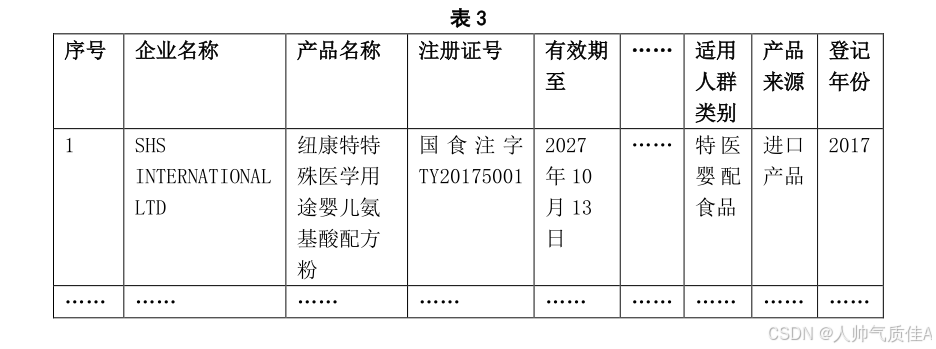
任务二:生产概况可视化
a) 统计不同登记年份不同产品来源的特医食品获批量,绘制双折线图,并在报告中对结果进行必要分析。
b) 根据特医食品产品来源与适用人群类别绘制内层为饼图的旭日图,其中内层表示适用人群类别,外层表示不同适用人群类别的产品来源分布,并在报告中对结果进行必要分析。
c) 统计不同产品类别的特医食品获批量,按获批量进行降序排列,绘制柱状图,x 轴为产品类别,y 轴为获批量,并在报告中对结果进行必要分析。
d) 在同一坐标系中,分别用不同颜色绘制 182 款特医食品脂肪和蛋白质含量的频数分布直方图,并在报告中对结果进行必要分析。
e) 根据 182 款特医食品的“适用人群”绘制词云图,并在报告中分析特医食品适用人群特征。
任务三:特医食品推荐
在任务 1 和任务 2 的基础上,合理运用现有数据完成推荐任务。基于客户的需求描述(如年龄段、症状、特殊说明),从 182 款特医食品中自动筛选出符合条件的产品选项,为客户提供个性化的特医食品推荐服务。实现方式不限,可以使用推荐算法或大模型,但须在报告中详细描述实现过程、推荐逻辑以及推荐结果。
基于构建的智能推荐模型(或系统),根据下列的客户需求进行特医食品的推荐。
a) 客户 1:婴儿、蛋白质过敏。
b) 客户 2:10 岁儿童、需要补充蛋白质、乳糖不耐受。
三、任务一:数据预处理
3.1、第一小问求解
先给出代码:
import os,pdfplumber
import pandas as pd
def get_pdf_filenames(folder_path):
"""
读取文件夹中所有PDF文件的名称。
Args:
folder_path: 文件夹的路径。
Returns:
一个包含PDF文件名称的列表。
"""
# 获取文件夹中所有文件的名称
files = os.listdir(folder_path)
# 筛选PDF文件
pdf_filenames = [file for file in files if file.endswith('.pdf')]
return pdf_filenames
def cal1(file):
with pdfplumber.open(file) as pdf:
page = len(pdf.pages)
print(len(pdf.pages))
text = ''
with pdfplumber.open(file) as pdf:
for i in range(page):
content_page = pdf.pages[i]
# 读取文本
text = text + content_page.extract_text()
return text
# 示例用法
folder_path = "D:/科研/研二上学期比赛/泰迪杯B题/数据/特医食品说明书/" # 替换为你的文件夹路径
pdf_filenames = get_pdf_filenames(folder_path)
text_all ={}
n=0
for i in pdf_filenames:
print(i)
print(f'正在提取第{n}个pdf文件!!')
path = os.path.expanduser("D:/科研/研二上学期比赛/泰迪杯B题/数据/特医食品说明书/"+i)
# print(cal1(path))
text_all[i] = cal1(path)
n=n+1
def cal2(name):
s = text_all[name]
s_sons = s.split("【配方特点/营养学特征】")[0].split("【营养成分表】")[1].split("\n")
print(s_sons[1])
re_text = ['能量(kJ)', '脂肪(g)', '碳水化合物(g)', '蛋白质', '钠', '氯', '钾', '磷']
ret = {}
if s_sons[1]=='营养成分 每100mL 每100kJ':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100mL 每100kJ']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100mL 每100kJ",'').strip().split(' ')[-1])
elif s_sons[1]=='营养成分 每100g 每100mL 每100kJ':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100g 每100mL 每100kJ']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100g 每100mL 每100kJ",'').strip().split(' ')[-1])
# print(i,j)
elif s_sons[1]=='营养成分 每100g 每100kJ':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100g 每100kJ']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100g 每100kJ",'').strip().split(' ')[-1])
elif s_sons[1]=='营养成分 每100mL 每100kJ 每份':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100mL 每100kJ 每份']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100mL 每100kJ 每份",'').strip().split(' ')[-2])
elif s_sons[1]=='营养成分 每100g 每100kJ 每份':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100g 每100kJ 每份']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100g 每100kJ 每份",'').strip().split(' ')[-2])
elif s_sons[1]=='营养成分 每100g 每100mL 每100kJ 每份':
for i in re_text:
for j in [x for x in s_sons if x != '营养成分 每100g 每100mL 每100kJ 每份']:
# print(i)
if i in j:
ret['注册证号']=name.replace(".pdf",'')
ret[i]=str(j.replace("营养成分 每100g 每100mL 每100kJ 每份",'').strip().split(' ')[-2])
return ret
result1 =[]
for name in text_all.keys():
cal2(name)
result1.append(cal2(name))
cal2('国食注字TY20180001.pdf')
import pandas as pd
# 将列表转换为DataFrame
df1 = pd.DataFrame(result1)
# 找出所有可能的列名
all_columns = set()
for item in result1:
all_columns.update(item.keys())
# 将所有可能的列名添加到DataFrame中
for column in all_columns:
df1[column] = df1[column].fillna(0) # 使用0填充缺失值
# 使用replace方法将所有-替换为0
# df1 = df1.replace('-', 0)
# 注册证号 能量(kJ) 脂肪(g) 碳水化合物(g) 蛋白质(g) 钠(mg) 氯(mg) 钾(mg) 磷(mg)
# 企业名称 产品名称 注册证号 有效期至 产品类别 组织状态 适用人群 适用人群类别 产品来源 登记年份
df1 = df1.rename(columns ={'注册证号':"注册证号",'能量(kJ)':'能量(kJ)','脂肪(g)':'脂肪(g)','碳水化合物(g)':'碳水化合物(g)',
'蛋白质':"蛋白质(g)",'钠':'钠(mg)','氯':'氯(mg)','钾':'钾(mg)','磷':'磷(mg)'})
with pd.ExcelWriter("D:/科研/研二上学期比赛/泰迪杯B题/result/result1.xlsx", engine='xlsxwriter') as writer:
df1.to_excel(writer, index=False)
# 使用sort_values方法进行降序排序
df1['蛋白质(g)'] =df1['蛋白质(g)'].astype(float)
df_sorted = df1.sort_values(by='蛋白质(g)', ascending=False)
# 打印排序后的DataFrame
df_sorted.head(3)针对任务一的第一小问:
首先,由于 182 款特医食品说明书给出为 pdf 版本,所以本文首先编程将182 款特医食品说明书的注册证号(pdf 版本文件名称)保存到“result1.xlsx”的A 列。接下来,编程将 182 款特医食品说明书的 pdf 版本的所有数据(包括换行符)逐页提取出来。其次,编程提取出 182 款特医食品的营养成分,以字符串方式切分,从“【营养成分表】”开始提取、到“【配方特点/营养学特征】”结束提取。这样就得到了 PDF 中的营养成分表格数据,表格数据行与行之间用分隔符隔开,就把每行数据根据分隔符切分放到营养成分列表中。
接下来观察每个表格数据,存在以下特殊情况:首先是表头有六种类型,分别为‘营养成分 每 100mL 每 100kJ’,‘营养成分 每 100g 每 100mL 每 100kJ’,‘营养成分 每 100g 每 100kJ’,‘营养成分 每 100mL 每 100kJ 每份’,‘营养成分 每 100g 每 100kJ 每份’,‘营养成分 每 100g 每 100mL 每 100kJ 每份’。其次有的表格在 PDF 中跨页存在,也就导致了数据中多出一个表头。然后,题目要求提取指定营养类型的数据,而不是全部。然后针对这三种特殊情况,我构建了一个匹配列表,元素为营养成分名称。
然后根据营养成分列表的第一个名称是否是六种表头之一来用 if 语句提取,如果满足前三种表头名称,则在营养成分列表中删除值还等于该表头名称的数据(分页会导致这种现象),判断匹配列表中的元素是否在营养元素列表中,若存在,则对营养成分列表中的元素把表头名称去除,用空格分割,取最后一个元素,也就是对应的该营养成分每 100kJ 含量结果。如果满足后面三种表头名称,则取倒数第二个元素,为对应的所需数据,提取简要算法流程如下:

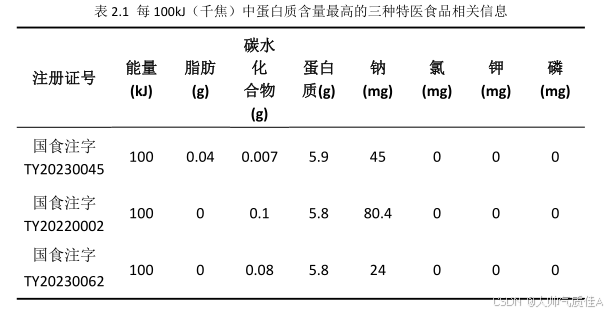
最后,提取完所有营养成分,将得到的结果存入“result1.xlsx”中。每 100kJ(千焦)中蛋白质含量最高的三种特医食品在表 2.1 中给出结果:
3.2、第二小问求解
先给出代码:
def cal3(name):
s = text_all[name]
add1=s.split("【产品类别】")[1].split("\n")[0].strip()
try:
add2=s.split("【组织状态】")[1].split("\n")[0].split("【适用人群】")[0].strip()
except:
add2=s.split("【组织状态】")[1].split("\n")[0].strip()
try:
add3=s.split("【适用人群】")[1].split("\n")[0].strip().split("【食用方法和食用量】")[0]
except:
add3=s.split("【适用人群】")[1].split("\n")[0].strip()
return add1,add2,add3
data = pd.read_excel("D:\科研\研二上学期比赛\泰迪杯B题\数据\data.xlsx")
dict_list = []
for i in text_all.keys():
dict_add={}
dict_add['注册证号'] = i.replace(".pdf",'')
add1,add2,add3 =cal3(i)
dict_add['产品类别'] = add1
dict_add['组织状态'] = add2
dict_add['适用人群'] = add3
dict_list.append(dict_add)
data_add = pd.DataFrame(dict_list)
data2 = pd.merge(data,data_add,on='注册证号', how="inner")
print(data2.shape)
with pd.ExcelWriter("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx", engine='xlsxwriter') as writer:
data2.to_excel(writer, index=False)根据任务一的要求,针对第二小问:
首先,根据第一小问提取出的 182 款特医食品说明书的 pdf 版本的所有数据(包括换行符)编程提取出“产品类别”、“组织状态”、“适用人群”。以“产品类别”为例,从“【产品类别】”开始,到“\n”结束,提取出两者之间的数据保存到文件“data.xlsx”中并命名为“产品类别”列。其次,在“data.xlsx”中的最左侧增加“序号”列,并将所有数据保存到文件“result2.xlsx”中。
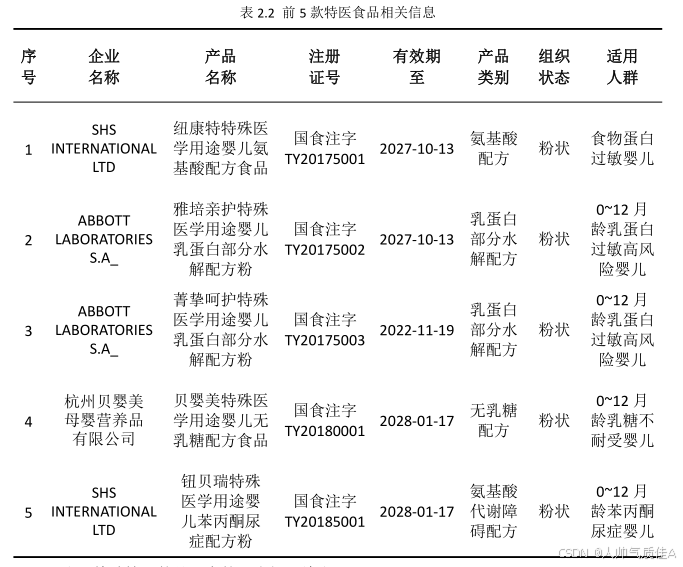
最后,根据上述所得工作表,前 5 款特医食品的结果在表 2.2 中给出:
3.3、第三小问求解
print(data2['适用人群'].value_counts())
add4 =[]
for i in data2['适用人群'].tolist():
if '10' in i:
add4.append('1岁以上特医食品')
elif '1岁以上' in i:
add4.append('1岁以上特医食品')
elif '0~12' in i:
add4.append('特医婴配食品')
elif '婴儿' in i:
add4.append('特医婴配食品')
elif '1~' in i:
add4.append('1岁以上特医食品')
elif '18' in i:
add4.append('1岁以上特医食品')
elif '50' in i:
add4.append('1岁以上特医食品')
data2['适用人群类别'] = add4
data2['适用人群类别'].value_counts()
with pd.ExcelWriter("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx", engine='xlsxwriter') as writer:
data2.to_excel(writer, index=False)根据任务一要求,针对对第三小问:
首先,通过统计“result2.xlsx”中“适用人群”列找出进行适用人群分类的关键数据。
然后,利用关键数据编程进行适用人群分类。“适用人群”列中出现“0~12”或“婴儿”输出为“特医婴配食品”,“适用人群”列中出现“10”或“1 岁以上”或“1~”或“18”时,输出为“1 岁以上特医食品”。
最后,将结果存放在”result2.xlsx”中。
3.4、第四小问求解
add5 = []
add6 =[]
for i in data2['注册证号']:
t=i[6:11]
add5.append(t[:4])
if t[-1:]=='0':
add6.append('国产产品')
elif t[-1:]=='5':
add6.append('进口产品')
data2['产品来源'] = add6
data2['登记年份'] = add5
data2
with pd.ExcelWriter("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx", engine='xlsxwriter') as writer:
data2.to_excel(writer, index=False)
data2.head(5)根据任务一要求,针对第四小问
首先,读取“result2.xlsx”中“注册证号”列。
然后,由于我们需要的数据位于“注册证号”中,所以采用字符串切片的方式提取第 6 到 11 位字符,并将所得新字符串的前四位存放于“result2.xlsx”中的“登记年份”列,对所得新字符串的最后一位字符进行判断,为“5”输出“进口产品”,为“0”则输出“国产产品”并将结果存放于“result2.xlsx”中的“产品来源”列。
最后,在表 2.3 中给出前 5 款特医食品“适用人群类别”、“产品来源”、“登记年份”的相关信息。
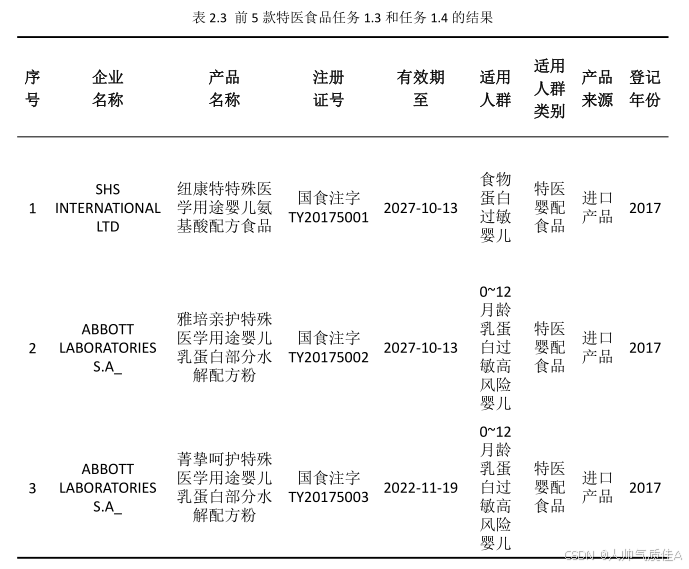
四、任务二:数据可视化
4.1、第一小问求解
import pandas as pd
data2 = pd.read_excel("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx")
data2
# 统计不同登记年份不同产品来源的获批量
result = data2.groupby(['登记年份', '产品来源']).size().unstack(fill_value=0)
# 打印统计结果
print(result)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
import matplotlib as mpl
from scipy.stats import norm
# 中文乱码的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常的显示负号
# 绘制双折线图
plt.figure(figsize=(8, 4))
plt.plot(result.index, result['国产产品'], color='b', linestyle='-', marker='o', label='国产产品', linewidth=2, markersize=10)
plt.plot(result.index, result['进口产品'], color='g', linestyle='--', marker='*', label='进口产品', linewidth=1, markersize=12)
# 设置图表标题和坐标轴标签
plt.title('不同登记年份特医食品获批量', fontsize=16)
plt.xlabel('登记年份', fontsize=14)
plt.ylabel('获批量', fontsize=14)
# 设置图例
plt.legend(loc='upper left', fontsize=12)
# 设置网格
plt.grid(True, linestyle='--', alpha=0.7)
# 设置坐标轴刻度字体大小
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# 显示图表
plt.show()根据任务二的要求,针对第一小问,本文基于任务一所得产品来源数据,给出不同登记年份不同产品来源的特医食品获批量双折线图:
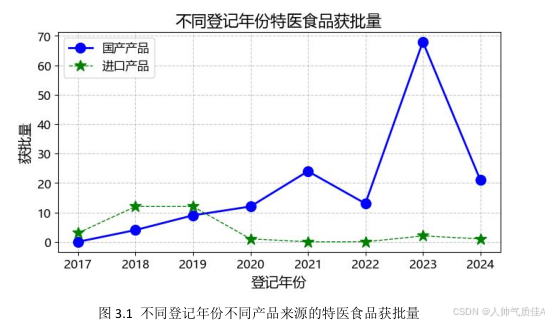
由图可得,国产产品获批量在 2017-2021 年间随着年份的变化呈上升趋势,在 2021-2022 年间有所下降,但在 2022-2023 年间迅速增多,随后再次大幅减少。进口产品获批量在 2017-2019 年间呈上升趋势,随后则随着年份变化总体呈下降趋势。
对比两种食品来源数据的折线图可以得到,在 2017-2019 年间,国产特医食品获批量与进口特医食品获批量有所差距,而在 2019 年之后,国产产品获批量遥遥领先,进口产品获批量再次减少之后基本没有变化。从总体获批量趋势可得,国产产品占据的份额越来越多。
4.2、第二小问求解
import pandas as pd
import plotly.express as px
# 假设 data2 已经定义并包含所需数据
df = data2
# 绘制旭日图
fig = px.sunburst(df, path=['适用人群类别', '产品来源'], values='登记年份',
color='适用人群类别', color_discrete_sequence=px.colors.qualitative.Pastel,
hover_data={'登记年份': ':.2f'})
# 更新布局
fig.update_layout(
title={
'text': '特医食品产品来源与适用人群类别旭日图',
'y': 0.95,
'x': 0.5,
'xanchor': 'center',
'yanchor': 'top'
},
margin=dict(t=50, l=25, r=25, b=25)
)
# 更新数据标签,显示百分比
fig.update_traces(
textinfo='label+percent entry',
insidetextorientation='radial'
)
# 显示图表
fig.show()针对任务二第二小问,本文根据特医食品的两种来源与适用人群类别绘制内层为饼图的旭日图。如图 3.2,图中内层为特医食品适用人群分布,外层为两种适用人群的产品来源分布。
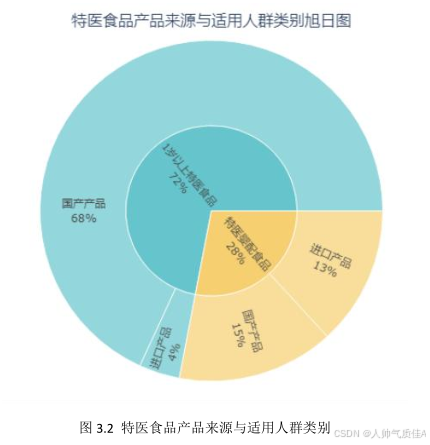
由图可得,一岁以上特医食品的占比为 72%,其中国产产品与进口产品的分布分别为 68%,4%;特医婴配食品的分布为 28%,其中国产产品与进口产品的分布分别为 15%,13%。
对比两种适用人群和产品来源分布可以得到,现今审批通过的特医食品(含已注销)大部分适用于 1 岁以上人群,且国产产品占比更大。在适用于婴儿的特医食品中,国产产品的占比仅以微弱优势领先进口产品。总体来看,国产产品目标更集中于一岁以上人群,进口产品则更专注于婴儿群体。
4.3、第三小问求解
import pandas as pd
import plotly.express as px
# 统计不同产品类别的特医食品获批量
product_count = data2['产品类别'].value_counts().reset_index()
product_count.columns = ['产品类别', '获批量']
# 按获批量进行降序排列
product_count = product_count.sort_values(by='获批量', ascending=False)
# 绘制柱状图
fig = px.bar(product_count, x='产品类别', y='获批量',
color='产品类别', color_discrete_sequence=px.colors.qualitative.Pastel,
title='不同产品类别的特医食品获批量')
# 更新布局,使图表更美观
fig.update_layout(
xaxis_title='产品类别',
yaxis_title='获批量',
title_x=0.5,
showlegend=False
)
# 显示图表
fig.show()针对任务二第三小问,将获批量按降序排列,绘制不同产品类别的特医食品获批量柱状图。
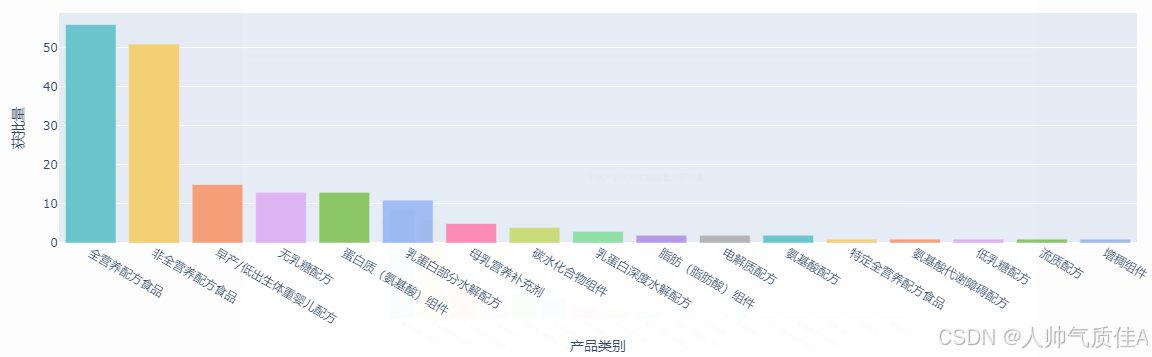
由图可得,在已获批的特医食品中(含已注销),全营养配方食品数量最多,非全营养配方食品次之,随后为早产/低出生体重婴儿配方、无乳糖配方、蛋白质(氨基酸)组件、乳蛋白部分水解配方,其余产品数量很少。总体来看,市场上已获批的能满足某些特定人群的特医食品并不多。
4.4、第四小问求解
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(0)
data = pd.read_excel("D:/科研/研二上学期比赛/泰迪杯B题/result/result1.xlsx")
data = data.replace('-', 0)
data1 = data['蛋白质(g)'].astype(float)
data2 = data['脂肪(g)'].astype(float)
fig, ax = plt.subplots(figsize=(10, 6))
ax.hist(data1, bins=50, alpha=0.3, label='蛋白质(g) ', color='blue')
ax.hist(data2, bins=50, alpha=0.3, label='脂肪(g)', color='orange')
ax.set_title('蛋白质和脂肪含量直方图', fontsize=16)
ax.set_xlabel('Value', fontsize=14)
ax.set_ylabel('Frequency', fontsize=14)
ax.legend(loc='upper right')
plt.tight_layout()
plt.show()针对任务二第四小问,本文用两种颜色绘制 182 款特医食品脂肪和蛋白质含量的频数分布直方图。结果如图 3.4 所示:
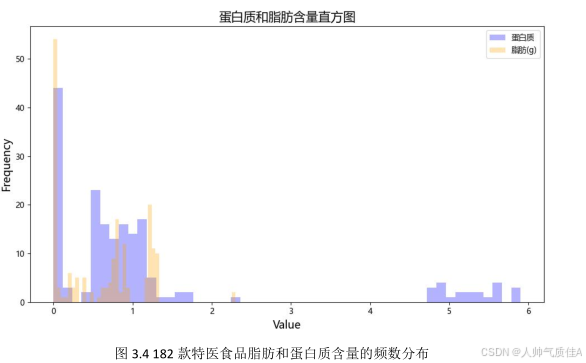
图中横轴代表特医食品的脂肪与蛋白质的含量,纵轴代表特医食品的频率数。由图可得,脂肪含量与蛋白质含量均在在[0,2]中的特医食品数量最多,此外,也有部分产品的蛋白质含量分布在[4.5,6]中。
4.5、第五小问求解
# 直接生成版
from pyecharts import options as opts
from pyecharts.charts import WordCloud
data2 = pd.read_excel("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx")
text = ''
for i in data2['适用人群']:
text = text+str(i)
print(text)
import jieba
from collections import Counter
#传入文本进行切分,并统计词频
def get_words(txt):
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x ) >1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k ,v) in c.most_common(100):
print('%s%s %s %d' % (' ' *( 5 -len(k)), k, '* ' *int( v /3), v))
return c
rusult_text = get_words(text)
print(rusult_text)
rusult_text = dict(rusult_text)
rusult_text
values_3 = list(rusult_text.values())
text = list(rusult_text.keys())
text_tup = [tuple(i) for i in zip(text,values_3)]
#词云图
#定义函数形式显示
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.globals import SymbolType
def map(text_tup) -> WordCloud:
c = (
WordCloud()
.add("", text_tup,word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="适用人群"))
)
return c
map(text_tup).render('词云图.html')
map(text_tup).render_notebook()针对任务二第五小问,本文根据任务一得到的 182 款特医食品的“适用人群”数据提取词段绘制词云图,结果如下所示:

由图可得,现有的已获批的特医食品适用人群的主要特征特征为:1-10 岁、10 岁以上、消化吸收障碍、代谢紊乱、需要补充营养,电解质、进食受限、特定疾病、医学。即 0-12 月、1-10 岁及 10 岁以上具有消化吸收障碍、代谢紊乱、进食受限或有特定疾病需要补充某些营养成分的人群。
五、任务三:特医食品推荐
5.1、问题分析
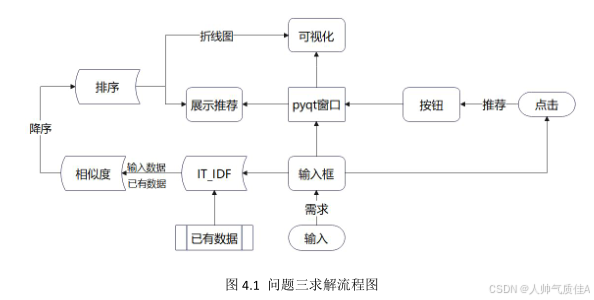
由于任务一和任务二获得了 182 款特医食品的营养物含量信息以及使用说明等信息。要构建药品推荐系统,就要提取关键信息进行推荐算法的构建。本文借助文本相似度和 pyqt 图形用户化界面构建了一个简单的推荐系统。求解流程图如下:
5.2、问题求解
代码如下:
import pandas as pd
data1 = pd.read_excel("D:/科研/研二上学期比赛/泰迪杯B题/result/result1.xlsx")
data2 = pd.read_excel("D:/科研/研二上学期比赛/泰迪杯B题/result/result2.xlsx")
print(data1.columns)
print(data2.columns)
data_all = pd.merge(data1,data2,on='注册证号')
# print(data_all.shape)
data_all=data_all[['产品名称','产品类别','组织状态','适用人群','适用人群类别','产品来源']]
data_all['适用人群类别'] =data_all['适用人群类别'].map({'特医婴配食品':'婴儿','1岁以上特医食品':'非婴儿'})
df =data_all
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 假设data是已经加载的DataFrame
data = df
# 准备数据:合并所有字段(除产品名称外)为一个文本字段
data['combined_text'] = data.drop(columns =['产品名称'],axis=1).apply(lambda row: ' '.join(row.astype(str)), axis=1)
# 创建TF-IDF向量
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(data['combined_text'])
# 定义一个函数来计算文本相似度并推荐产品
def recommend_products(input_text, tfidf_vectorizer, tfidf_matrix, data, top_n=3):
input_tfidf = tfidf_vectorizer.transform([input_text])
from scipy.stats import pearsonr
similarity = cosine_similarity(input_tfidf, tfidf_matrix)
similarity_scores = similarity.flatten()
top_indices = np.argsort(-similarity_scores)[:top_n]
recommended_products = data.iloc[top_indices]
recommended_products['similarity_score'] = similarity_scores[top_indices]
return recommended_products
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QVBoxLayout, QHBoxLayout, QLabel, QLineEdit, QPushButton, QTableView, QHeaderView
from PyQt5.QtCore import Qt, QAbstractTableModel, QVariant
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['FangSong'] # 设置显示中文 字体为宋体
plt.rcParams['font.size']=15 # 设置字体大小
from io import BytesIO
from PyQt5.QtGui import QPixmap
class RecommendationTableModel(QAbstractTableModel):
def __init__(self, data):
super().__init__()
self._data = data
def rowCount(self, parent=None):
return len(self._data)
def columnCount(self, parent=None):
return len(self._data[0])
def data(self, index, role):
if role == Qt.DisplayRole:
row = index.row()
col = index.column()
return str(self._data[row][col])
return QVariant()
def headerData(self, section, orientation, role):
if role == Qt.DisplayRole:
if orientation == Qt.Horizontal:
headers = ["产品名称", "推荐度得分",'适用人群','产品类别','适用人群类别']
return headers[section]
return QVariant()
class App(QWidget):
def __init__(self):
super().__init__()
self.title = '特医食品推荐系统'
self.initUI()
def initUI(self):
self.setWindowTitle(self.title)
self.setGeometry(100, 100, 1000, 700) # 设置窗口初始位置和大小
# 设置样式表
self.setStyleSheet("""
QWidget {
background-color: #f0f0f0; /* 灰色背景 */
}
QLineEdit {
border: 2px solid #8f8f91;
border-radius: 10px;
padding: 6px;
background-color: #fff; /* 白色输入框背景 */
}
QPushButton {
background-color: #007bff; /* 蓝色按钮背景 */
color: white;
border-radius: 10px;
padding: 10px;
}
QPushButton:hover {
background-color: #0056b3; /* 鼠标悬停时按钮颜色 */
}
QTableView {
border: none;
background-color: #ffffff; /* 表格背景颜色 */
}
""")
# 创建布局
layout = QVBoxLayout()
# 创建输入框和按钮
input_layout = QHBoxLayout()
self.customer需求的描述_input = QLineEdit(self)
self.customer需求的描述_input.setPlaceholderText("请输入客户需求描述...")
self.customer需求的描述_input.setFixedWidth(600) # 增加输入框宽度
self.recommend_button = QPushButton('推荐', self)
self.recommend_button.clicked.connect(self.recommend_products)
input_layout.addWidget(self.customer需求的描述_input)
input_layout.addWidget(self.recommend_button)
# 创建输出表格
self.recommendation_table = QTableView(self)
self.recommendation_table.setFixedHeight(300) # 增加表格高度
self.recommendation_table.horizontalHeader().setSectionResizeMode(QHeaderView.Stretch) # 自动调整列宽
# 创建图表标签
self.graph_label = QLabel('柱状图:')
self.graph_label.setAlignment(Qt.AlignCenter) # 居中对齐
# 添加到布局
layout.addLayout(input_layout)
layout.addWidget(self.recommendation_table)
layout.addWidget(self.graph_label)
self.setLayout(layout)
def recommend_products(self):
# 这里是示例代码,实际应用中需要替换为真实的推荐逻辑
# 获取输入
input_text = self.customer需求的描述_input.text()
# 构建输入文本
# input_text = f'{people_category} {applicable_people} {product_category}'
# 获取推荐结果
recommended = recommend_products(input_text, tfidf_vectorizer, tfidf_matrix, data)
# 将推荐结果和相似度得分转换为表格数据
table_data = [
(row['产品名称'], round(row['similarity_score'],4), row['适用人群'],row['产品类别'],row['适用人群类别']) for row in recommended.to_dict(orient='records')
]
# 设置表格模型
self.model = RecommendationTableModel(table_data)
self.recommendation_table.setModel(self.model)
print(recommended.to_dict(orient='records'))
# 绘制并显示柱状图
plt.figure(figsize=(8, 4))
# 绘制折线图
plt.figure(figsize=(10, 6))
plt.plot([row['产品名称'] for row in recommended.to_dict(orient='records')],[row['similarity_score'] for row in recommended.to_dict(orient='records')], marker='*', linestyle='-', color='blue', label='推荐度得分')
# 美化图表
plt.title('特医食品推荐相似度得分', fontsize=16, fontweight='bold')
plt.xlabel('产品名称', fontsize=14)
plt.ylabel('相似度得分', fontsize=14)
plt.xticks(rotation=45)
plt.grid(True)
plt.legend()
plt.tight_layout()
# 将matplotlib图像转换为QPixmap
buf = BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
pixmap = QPixmap()
pixmap.loadFromData(buf.getvalue())
buf.close()
self.graph_label.setPixmap(pixmap)
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = App()
ex.show()
sys.exit(app.exec_())第一步,本文先合并所有产品信息,然后将这些信息利用字符串相加的方式合并为一个新的字符串(除了推荐所用的产品名称)作为已有产品的全部信息的代表。由于适用人群类别字段取值为特医婴配食品和 1 岁以上特医食品较为专业,本文结合实际情况将适用人群类别字符串设置为婴儿、非婴儿。
第二步,利用 PYQT5 构建一个布局为三行一列的窗口。第一行是一个输入框和一个搜索框,用于用户输入需求信息及点击推荐按钮执行推荐算法,第二行是推荐结果展示,第三行是推荐得分的折线图可视化展示。
当用户输入需求并点击推荐按钮后,推荐算法会将用户输入的需求和产品的全部信息所代表的字符串转为 TF-IDF 向量,然后根据各自的向量计算输入需求和所有产品信息描述之间的文本余弦相似度,最后将结果按降序排列,输出相似度得分最高的产品作为系统推荐产品。
本文设计的推荐系统的初始化界面如下:
在推荐系统中输入用户一的需求:婴儿、蛋白质过敏。得到的推荐结果截图如下:
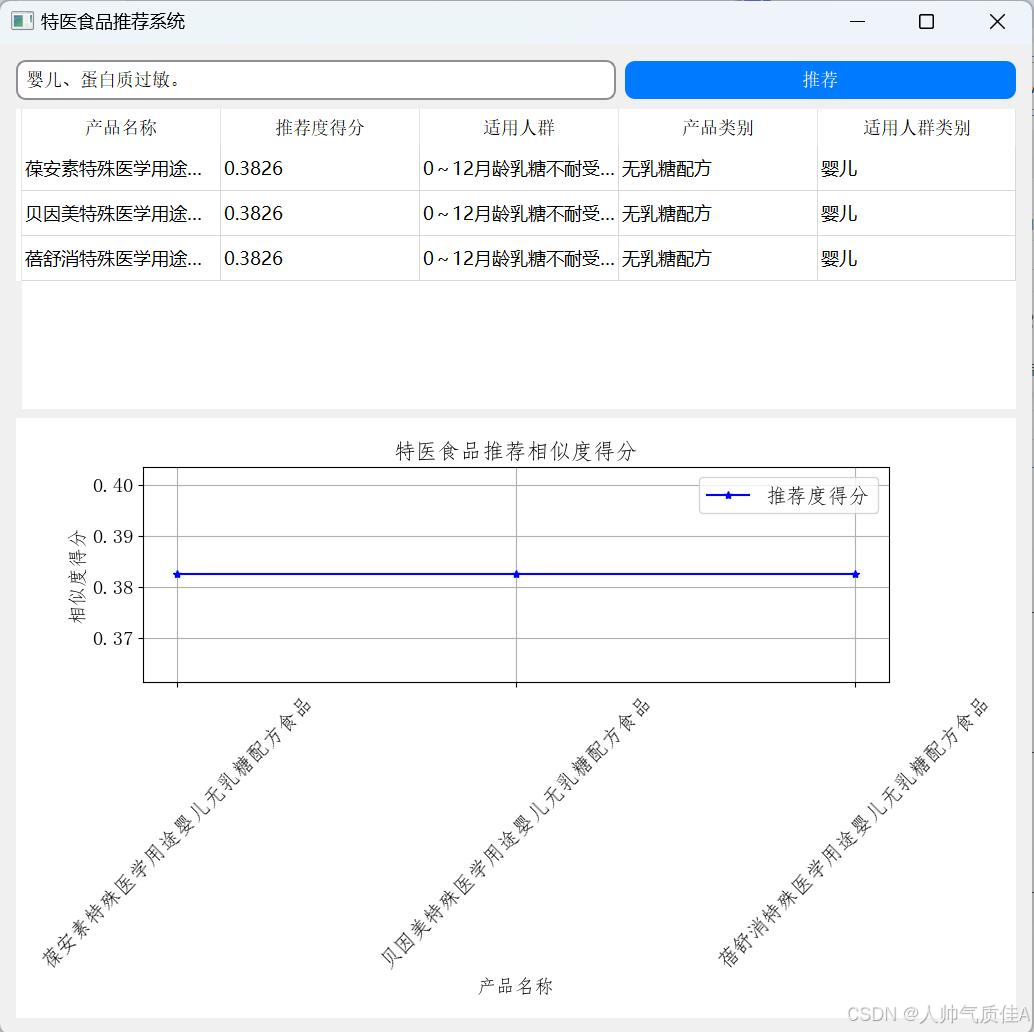
由图可得,系统推荐的第一款产品就属于蛋白质过敏的婴儿适用的特医食品,推荐结果较为准确。
然后输入用户二的需求:10 岁儿童、需要补充蛋白质、乳糖不耐受。得到的推荐结果截图如下:
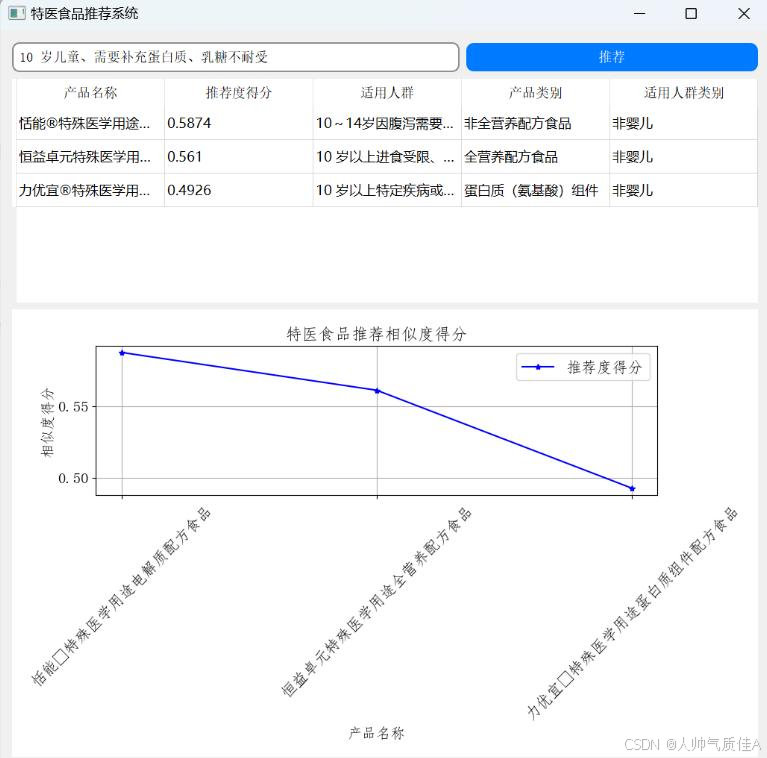
从图中推荐度得分可以看到对用户二的推荐结果也较为准确。若在用户二需求基础加上其他信息,如进口,年份,状态,即输入 10 岁儿童、需要补充蛋白质、乳糖不耐受、粉状、2017 年、国产产品,则推荐结果如下:
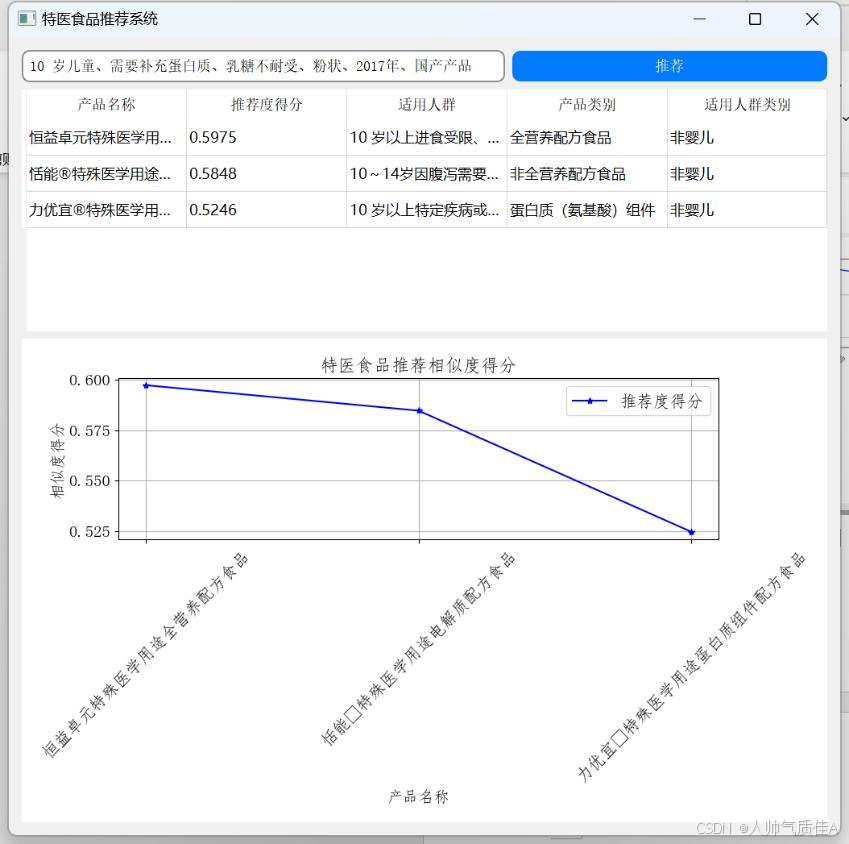
从图中可以看到用户需求输入得越详细,推荐出得产品推荐相似度得分越高,即产品匹配值更高,推荐系统的有效性更强。
六、总结
本次比赛B题计算量不大,主要考察的是python批量读取PDF的表格数据,并处理各种异常情况,然后是数据可视化和根据数据进行推荐。根据数据进行推荐的部分,也考虑过协同过滤推荐算法和内容推荐,但是针对这份数据,个人感觉不行,所以采用了文本相似度方式进行推荐。我认为如何对PDF的表格数据精准识别提取和推荐算法设计是两大难点,其余的部分都看数据分析和可视化的基本功。代码已经完全贴上去了,如果有义父需要完整的代码+数据+报告,麻烦给小弟点个赞,私信获取。

















 2582
2582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









