









🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
随机森林:深度解析与应用实践
引言
在机器学习的广阔天地中,集成学习方法因其卓越的预测能力和泛化性能而备受青睐。其中,随机森林(Random Forest)作为集成学习的一个重要分支,凭借其简单、高效且易于实现的特性,在分类和回归任务中展现了非凡的表现。本文将深入探讨随机森林的基本原理、核心构建模块、关键参数调优以及在实际应用中的策略与案例分析,旨在为读者提供一个全面而深入的理解。
1. 随机森林基础
1.1 什么是随机森林?
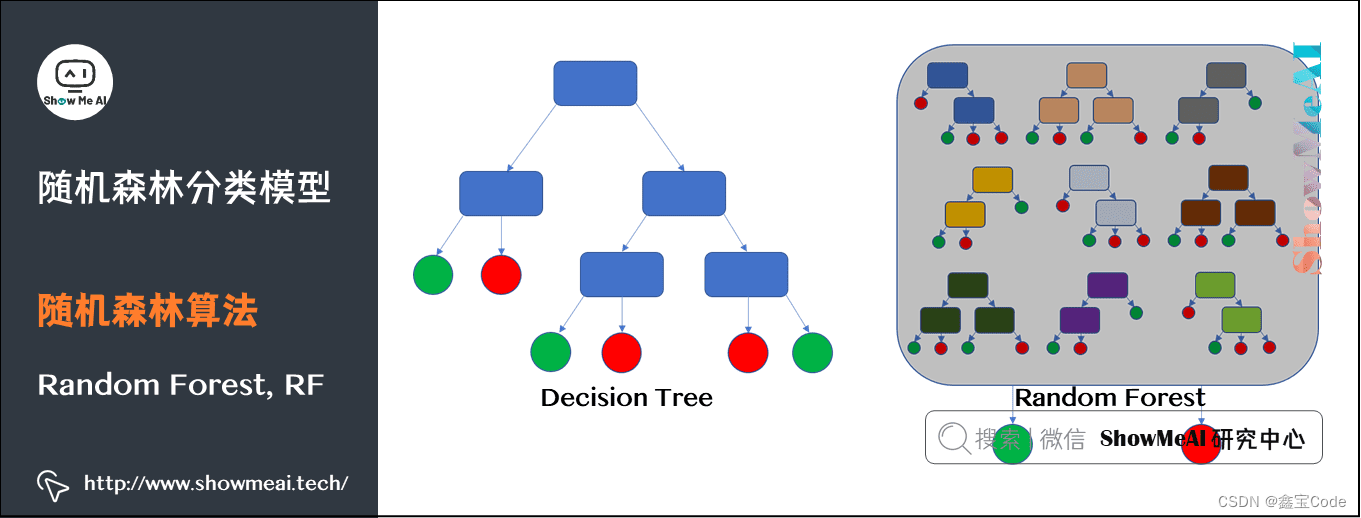
随机森林是一种基于决策树的集成学习方法,通过构建多个决策树并综合它们的预测结果来提高预测准确性和模型的稳定性。每个决策树都是在训练数据的一个随机子集(bootstrap sample)上,以及特征的一个随机子集上构建的,这种方法减少了模型间的相关性,从而增强了整体模型的泛化能力。
1.2 随机森林的核心思想
- Bootstrap Aggregating (Bagging):利用自助采样法从原始数据集中有放回地抽取样本,生成多个不同的训练集,每个训练集用于训练一个决策树。
- 特征随机选择:在决策树的每个节点分裂时,不是从所有特征中选择最佳分割特征,而是从一个随机特征子集中选择
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











