







Bootstrapping 自举
在强化学习中,自举表示用一个估算去更新同类的估算

在更新梯度的时候我们用到了
y
t
y_t
yt,但
y
t
y_t
yt又部分基于DQN
即为了更新DQN在t时刻的估计,我们用到DQN在t+1时刻的估计,出现了自举

出现的问题:
用TD算法更新DQN会导致DQN高估动作的真实价值
高估的原因:

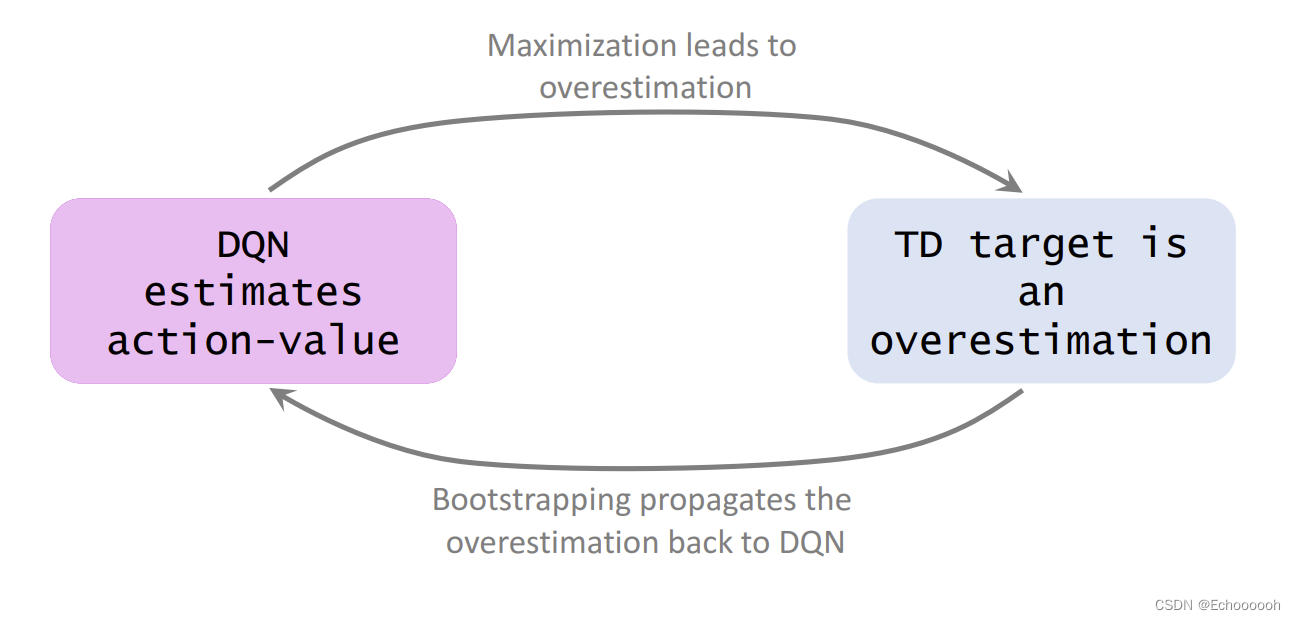
1.计算TD Target的时候用到了最大化 会导致高估
2.bootstrapping 用自己估计自己 如果这一轮已经高估,下一轮更会高估
为什么最大化会导致高估

估计通常是有偏差的,偏差的均值为零,但是会让最大值更大,最小值更小

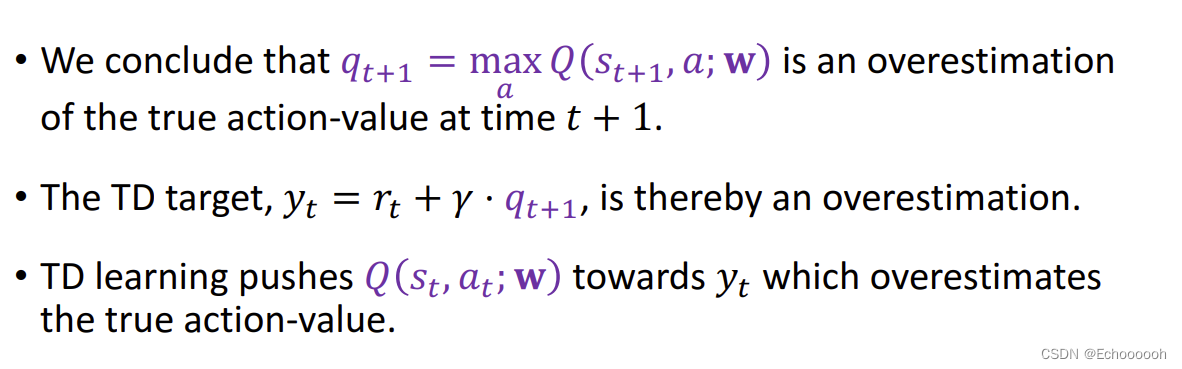
对
q
t
+
1
q_{t+1}
qt+1的高估会传递下去,导致DQN的高估
自举

高估会出现正反馈 不断扩大
高估为什么有害
高估本身不是问题,做决策的时候看的是相对大小
麻烦的是非均匀的高估
实际上DQN的高估是非均匀的

解决方案1:Target Network
用另一个结构一样但是参数不一样的网络
DQN用来控制Agent,并且收集经验(transitions)
用Target Network计算TD Target

算法流程

Target Network的参数记作
w
−
w^-
w−,隔一段时间更新一次
更新策略有两种:
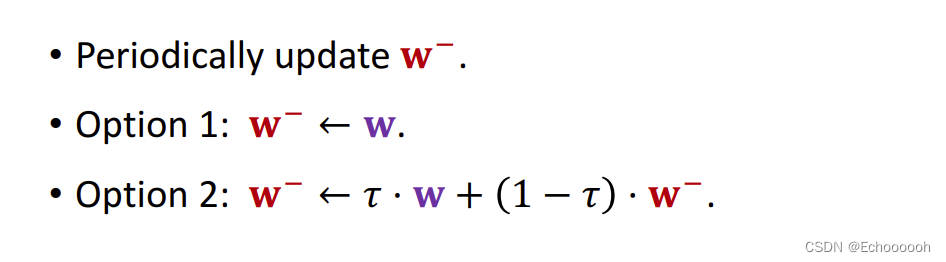
Target Network中仍然存在最大化操作,并且 Target Network无法独立于DQN,导致仍然存在一定程度的高估,只是不那么严重。

解决方案2:double DQN
比较三者的最大化操作
1.原始版

2.Target Network

3.Double DQN

两步用不同的网络 ,小改动但大幅提升性能
为什么会更好
















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









