







 本文探讨了强化学习中DQN算法的高估问题,包括最大化导致的动作价值高估和Bootstrapping引发的正反馈循环。介绍了Target Network作为解决方案,通过分离目标网络来减少高估,以及Double DQN如何避免最大化过程中的高估。这两种方法都是为了提高DQN的学习效果和稳定性。
本文探讨了强化学习中DQN算法的高估问题,包括最大化导致的动作价值高估和Bootstrapping引发的正反馈循环。介绍了Target Network作为解决方案,通过分离目标网络来减少高估,以及Double DQN如何避免最大化过程中的高估。这两种方法都是为了提高DQN的学习效果和稳定性。
强化学习—— Target Network & Double DQN(解决高估问题,overestimate)
1TD算法
- TD Target: y t = r t + m a x a Q ( s t + 1 , a ; W ) y_t = r_t +\mathop{max}\limits_{a}Q(s_{t+1},a;W) yt=rt+amaxQ(st+1,a;W)
- SGD:
W
←
W
−
α
⋅
(
Q
(
s
t
,
a
t
;
W
)
−
y
t
)
⋅
∂
Q
(
s
t
,
a
t
;
W
)
∂
W
W\gets W-\alpha \cdot (Q(s_t,a_t;W)-y_t)\cdot \frac{\partial Q(s_t,a_t;W)}{\partial W}
W←W−α⋅(Q(st,at;W)−yt)⋅∂W∂Q(st,at;W)
TD Target中的部分基于Q,并用于更新Q自身。
2. 高估问题
使用TD 算法进行学习使得DQN出现高估问题(overestiamte),两个主要原因为:
- TD Target比真实的动作价值更大(Maximization)。
- Bootstrapping
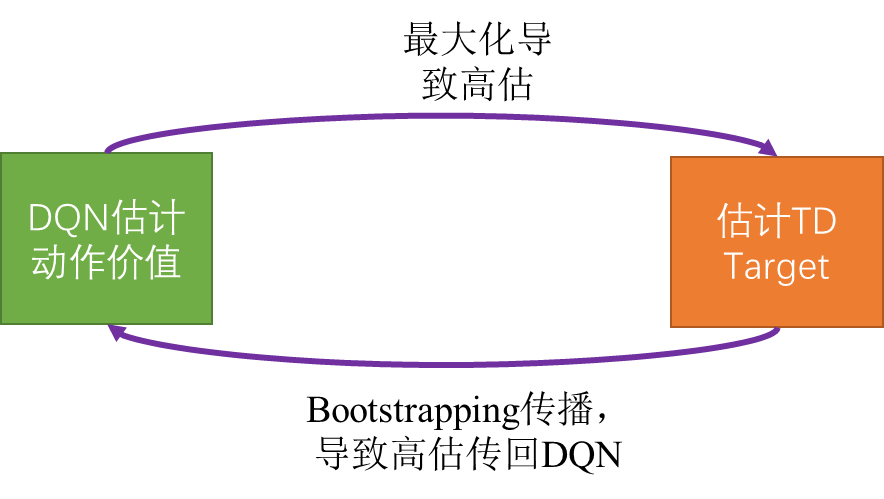
2.1 Maximization
2.1.1 数学解释
- 观测到实数: x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn
- 对实数x增加均值为0的噪音,得到: Q 1 , Q 2 , . . . , Q n Q_1,Q_2,...,Q_n Q1,Q2,...,Qn
- 均值为0的噪音并不影响增加前后的均值: E [ m e a n i ( Q i ) ] = E [ m e a n i ( x i ) ] E[mean_i(Q_i)]=E[mean_i(x_i)] E[meani(Qi)]=E[meani(xi)]
- 添加均值为0的噪音会增加添加后的最大值: E [ m a x i ( Q i ) ] ≥ E [ m a x i ( x i ) ] E[max_i(Q_i)]≥E[max_i(x_i)] E[maxi(Qi)]≥E[maxi(xi)]
- 添加均值为0的噪音会减小添加后的最小值: E [ m i n i ( Q i ) ] ≤ E [ m i n i ( x i ) ] E[min_i(Q_i)]≤E[min_i(x_i)] E[mini(Qi)]≤E[mini(xi)]
2.1.2 动作价值函数的高估
- 真实的动作价值为 x ( a 1 ) , x ( a 2 ) , . . . , x ( a n ) x(a_1),x(a_2),...,x(a_n) x(a1),x(a2),...,x(an)
- 通过DQN得到有噪音的动作价值估计: Q ( s 1 , a 1 ; W ) , Q ( s 2 , a 2 ; W ) , . . . , Q ( s n , a n ; W ) Q(s_1,a_1;W),Q(s_2,a_2;W),...,Q(s_n,a_n;W) Q(s1,a1;W),Q(s2,a2;W),...,Q(sn,an;W)
- 假设为无偏估计: m e a n a x ( a ) = m e a n a Q ( s , a ; W ) \mathop{mean}\limits_{a}x(a)=\mathop{mean}\limits_{a}Q(s,a;W) ameanx(a)=ameanQ(s,a;W)
- 则会产生如下高估: q = m a x a Q ( s , a ; W ) ≥ m a x a x ( a ) q=\mathop{max}\limits_{a}Q(s,a;W)≥\mathop{max}\limits_{a}x(a) q=amaxQ(s,a;W)≥amaxx(a)
- t+1时刻真实动作价值函数的高估为: q = m a x a Q ( s t + 1 , a ; W ) q=\mathop{max}\limits_{a}Q(s_{t+1},a;W) q=amaxQ(st+1,a;W)
- 则TD Target为高估: y t = γ ⋅ q t + 1 y_t=\gamma \cdot q_{t+1} yt=γ⋅qt+1
- 更新后的Q朝向TD Target,仍为高估。
2.2 Bootstrapping
自举:using an estimated value in the update step for the same kind of estimated value
- 假设DQN已经高估了动作价值
- 则t+1时刻的动作价值已经为高估: Q ( s t + 1 , a ; W ) Q(s_{t+1},a;W) Q(st+1,a;W)
- 则t+1时刻的最优动作价值为进一步的高估: q t + 1 = m a x a Q ( s t + 1 , a , W ) q_{t+1}=\mathop{max}\limits_{a}Q(s_{t+1},a,W) qt+1=amaxQ(st+1,a,W)
- 当t+1时刻的最优动作价值在用于更新Q网络时,则DQN的高估被进一步加剧。
2.3 高估是否有害
- 均匀高估没有影响。因为关注相对大小,不关注绝对大小
- 非均匀高估则会产生影响。
DQN为非均匀高估:
- 使用一个transition去更新W: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- TD Target计算时: y t 高 估 了 Q ⋆ ( s t , a t ) y_t高估了Q^\star(s_t,a_t) yt高估了Q⋆(st,at)
- 梯度更新使得: Q ( s t , a t ; W ) 朝 向 y t Q(s_t,a_t;W)朝向y_t Q(st,at;W)朝向yt
- 因此: Q ( s t , a t ; W ) 高 估 了 Q ⋆ ( s t , a t ) Q(s_t,a_t;W)高估了Q^\star(s_t,a_t) Q(st,at;W)高估了Q⋆(st,at)
- 而(s,a)在replay buffer中的频率不一样,(s,a)的频率越高,则: Q ( s , a ; W ) 会 更 多 的 高 估 Q ⋆ ( s , a ) Q(s,a;W)会更多的高估Q^\star(s,a) Q(s,a;W)会更多的高估Q⋆(s,a)
3. 高估的解决方案
3.1 Target Network
使用一个target 网络去计算TD targets,可以解决bootstrapping引起的高估问题。
3.1.1 Target Network的结构
Q
(
s
,
a
,
W
−
)
Q(s,a,W^-)
Q(s,a,W−)
网络结构与DQN一致,但参数不一样:
W
≠
W
−
W\neq W^-
W=W−
3.1.2 学习方式
- 使用 DQN控制agent和收集经验: Q ( s , a ; W ) f o r ( s t , a t , r t , s t + 1 ) Q(s,a;W) for {(s_t,a_t,r_t,s_{t+1})} Q(s,a;W)for(st,at,rt,st+1)
- 使用Target Network计算TD Target: y t = r t + γ ⋅ m a x a Q ( s t + 1 , a , W − ) y_t = r_t+\gamma \cdot \mathop{max}\limits_{a}Q(s_{t+1},a,W^-) yt=rt+γ⋅amaxQ(st+1,a,W−)
- TD error 为: δ t = Q ( s t , a , W ) − y t \delta_t = Q(s_{t},a,W)-y_t δt=Q(st,a,W)−yt
- SGD 更新网络参数:
W
←
W
−
α
⋅
(
Q
(
s
t
,
a
t
;
W
)
−
y
t
)
⋅
∂
Q
(
s
t
,
a
t
;
W
)
∂
W
W\gets W-\alpha \cdot (Q(s_t,a_t;W)-y_t)\cdot \frac{\partial Q(s_t,a_t;W)}{\partial W}
W←W−α⋅(Q(st,at;W)−yt)⋅∂W∂Q(st,at;W)
Target Network的参数需要定期更新(periodically update)
- 方法一: W ← W − W\gets W^- W←W−
- 方法二:
W
←
η
⋅
W
+
(
1
−
η
)
⋅
W
−
W\gets \eta \cdot W + (1-\eta) \cdot W^-
W←η⋅W+(1−η)⋅W−
仍然无法避免高估
3.2 Double DQN
解决最大化造成的高估。
- 选择最优动作时使用DQN: a ⋆ = a r g m a x a Q ( s t + 1 , a ; W ) a^\star=\mathop{argmax}\limits_{a}Q(s_{t+1},a;W) a⋆=aargmaxQ(st+1,a;W)
- 评估动作价值时使用 Target Network: y t = r t + γ ⋅ Q ( s t + 1 , a ⋆ ; W − ) y_t = r_t + \gamma \cdot Q(s_{t+1},a^\star;W^-) yt=rt+γ⋅Q(st+1,a⋆;W−)
- Double DQN更好的原因: Q ( s t + 1 , a ⋆ ; W − ) ≤ m a x a Q ( s t + 1 , a ; W − ) Q(s_{t+1},a^\star;W^-)≤\mathop{max}\limits_{a}Q(s_{t+1},a;W^-) Q(st+1,a⋆;W−)≤amaxQ(st+1,a;W−)
4. 总结
- 最大化导致真实的动作价值被高估
- bootstrapping造成正反馈循环,导致高估
- Target Network能部分避免bootstrapping: W − 依 赖 于 W W^-依赖于W W−依赖于W
- Double DQN避免最大化造成的高估
| 网络学习方式 | 动作选择 | 价值评估 |
|---|---|---|
| 原始方式 | DQN | DQN |
| Target Network | Target Network | Target Network |
| Double DQN | DQN | Target Network |
本文内容为参考B站学习视频书写的笔记!
by CyrusMay 2022 04 10
我们在小孩和大人的转角
盖一座城堡
——————五月天(好好)——————

















 2353
2353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









