






普通的DQN算法通常会导致对Q值的过高估计,原因是Q值的估计以及动作的选取采用了同一套神经网络,而神经网络在估算Q值时本身会产生正向或负向的误差,而拟合的误差在参数更新时并未得到修正,比如说状态s下所有动作的Q值均为0,而神经网络拟合时出现了某些动作价值估计有正误差的情况,即存在某个动作a使得Q(s,a)>0,此时我们的更新目标就出现了过高估计,r+γmaxQ>r+0,那么此时Q(s,a)就被过高估计了,而我们之后也会拿这个Q值去更新上一步的Q值,这样子误差就逐步累积了。
解决方法是使用两套独立训练的神经网络,利用其中一套神经网络的输出来选取价值最大的动作,用另一套神经网络来计算该动作的价值,而DQN算法中本身就有两套神经网络-训练网络和目标网络,只不最优状态动作对的Q值计算只用到了其中的目标网络,那么我们恰好可以将训练网络作为选取动作的神经网络,将目标网络作为计算Q值的网络,由于目标网络是隔一段时间后更新,所以选取其作为计算Q值的网络是合理的,其中训练网络的参数记为![]() ,目标网络的参数记为
,目标网络的参数记为![]() ,那么Double DQN的优化目标可写为:
,那么Double DQN的优化目标可写为:
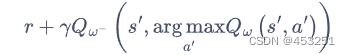
我们采用倒立摆的环境进行实践
首先导入需要的库
import random
import gym
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils #动手学深度学习的库,里面包含了对经验回放池,在线策略,离线策略以及优势函数计算的定义
from tqdm import tqdm 定义经验回放池
class ReplayBuffer:
"""经验回放池"""
def __init__(self,capacity):
#创建一个双向队列
self.buffer=collections.deque(maxlen=capacity) #队列,先进先出
def add(self,state,action,reward,next_state,done): #将数据加入buffer
self.buffer.append((state,action,reward,next_state,done))
def sample(self,batch_size): #从buffer中采样数据,数量为batch_size
#采样之后,transitions是一个列表,每一个元素是一个聚合体
transitions=random.sample(self.buffer,batch_size)
#zip是将列表分离,然后将所有聚合体的第一个元素给state,第二个给action,以此类推
state,action,reward,next_state,done=zip(*transitions)
#所以分配之后,state,action等等都是一个列表
return np.array(state),action,reward,np.array(next_state),done
def size(self): #目前buffer中数据的数量
return len(self.buffer)定义Q网络
class Qnet(torch.nn.Module):
"""只有一层隐藏层的Q网络"""
def __init__(self,state_dim,hidden_dim,action_dim):
super(Qnet,self).__init__()
self.fc1=torch.nn.Linear(state_dim,hidden_dim)
self.fc2=torch.nn.Linear(hidden_dim,action_dim)
def forward(self,x):
x=F.relu(self.fc1(x))
return self.fc2(x)在DQN算法的基础上改进,使用Double DQN
class DQN:
"""DQN算法,包括Double DQN"""
def __init__(self,state_dim,hidden_dim,action_dim,learning_rate,gamma,epsilon,target_update,device,dqn_type='VanillaDQN'):
self.action_dim=action_dim
self.q_net=Qnet(state_dim,hidden_dim,self.action_dim).to(device)
self.target_q_net=Qnet(state_dim,hidden_dim,self.action_dim).to(device)
self.optimizer=torch.optim.Adam(self.q_net.parameters(),lr=learning_rate)
self.gamma=gamma
self.epsilon=epsilon
self.target_update=target_update
self.count=0
self.dqn_type=dqn_type
self.device=device
def take_action(self,state):
if np.random.random()<self.epsilon:
action=np.random.randint(self.action_dim)
else:
state=torch.tensor([state],dtype=torch.float).to(device)
action=self.q_net(state).argmax().item()
return action
def max_q_value(self,state):
state=torch.tensor([state],dtype=torch.float).to(device)
return self.q_net(state).max().item()
def update(self,transition_dict):
states=torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)
actions=torch.tensor(transition_dict['actions']).view(-1,1).to(self.device)
rewards=torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1,1).to(self.device)
next_states=torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)
dones=torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1,1).to(self.device)
q_values=self.q_net(states).gather(1,actions)
if self.dqn_type=='DoubleDQN': #DQN与Double DQN的区别
#用训练网络找出max的动作
#.max(1)是找到最大动作及其索引
#其中第一列是Q值,第二列就是对应的动作
max_action=self.q_net(next_states).max(1)[1].view(-1,1)
#再用目标网络计算max动作对应的Q值,从而减小误差
max_next_q_values=self.target_q_net(next_states).gather(1,max_action)
else:
max_next_q_values=self.target_q_net(next_states).max(1)[0].view(-1,1)
q_targets=rewards+self.gamma*max_next_q_values*(1-dones)
dqn_loss=torch.mean(F.mse_loss(q_values,q_targets)) #采用均方误差损失函数计算损失
self.optimizer.zero_grad()
dqn_loss.backward()
self.optimizer.step()
if self.count%self.target_update==0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.count+=1设置超参数,并实现将倒立摆中的连续动作转化为离散动作的函数
lr=1e-2
num_episodes=200
hidden_dim=128
gamma=0.98
epsilon=0.01
target_update=50
buffer_size=5000
minimal_size=1000
batch_size=64
device=torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
env_name='Pendulum-v1'
env=gym.make(env_name)
state_dim=env.observation_space.shape[0]
action_dim=11 #将连续动作分成11个离散动作
def dis_to_con(discrete_action,env,action_dim): #离散动作转回连续的函数
#discrete_action是表示离散空间某个动作的离散值
action_lowbound=env.action_space.low[0] #连续动作的最小值
action_upbound=env.action_space.high[0] #连续动作的最大值
#(discrete_action/(action_dim-1)) 表示将离散动作的取值范围映射到 [0,1] 之间,其中 (action_dim-1) 是离散动作空间的最大索引。
#(discrete_action/(action_dim-1))*(action_upbound-action_lowbound) 表示将映射到 [0,1] 之间的离散动作值,与连续动作的取值范围之差相乘,得到在连续动作空间中的相对取值范围
#action_lowbound + (discrete_action/(action_dim-1))*(action_upbound-action_lowbound) 表示将相对取值范围加上 action_lowbound,得到最终的连续动作值
return action_lowbound+(discrete_action/(action_dim-1))*(action_upbound-action_lowbound)定义离线强化学习策略,这里我们将结果可视化,观测这些Q值存在的过高估计的情况
def train_DQN(agent,env,num_episodes,replay_buffer,minimal_size,batch_size):
return_list=[]
max_q_value_list=[]
max_q_value=0
for i in range(10):
with tqdm(total=int(num_episodes/10),desc='Iteration %d'% i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return=0
state=env.reset()
done=False
while not done:
action=agent.take_action(state)
max_q_value=agent.max_q_value(state)*0.005+max_q_value*0.995 #平滑处理
max_q_value_list.append(max_q_value) #保存每个状态的最大Q值
action_continuous=dis_to_con(action,env,agent.action_dim)
#训练神经网络时是将离散化的动作传进去的,然后让环境做动作时应该将动作还原回连续的状态
next_state,reward,done,_=env.step([action_continuous])
replay_buffer.add(state,action,reward,next_state,done)
state=next_state
episode_return+=reward
if replay_buffer.size()>minimal_size:
b_s,b_a,b_r,b_ns,b_d=replay_buffer.sample(batch_size)
transition_dict={'states':b_s,'actions':b_a,'rewards':b_r,'next_states':b_ns,'dones':b_d}
agent.update(transition_dict)
return_list.append(episode_return)
if(i_episode+1) %10==0:
pbar.set_postfix({'episode':'%d' %(num_episodes/10*i+i_episode+1),'return':'%.3f'% np.mean(return_list[-10:])})
pbar.update(1)
return return_list,max_q_value_list接下来要对比DQN和Double DQN的训练情况
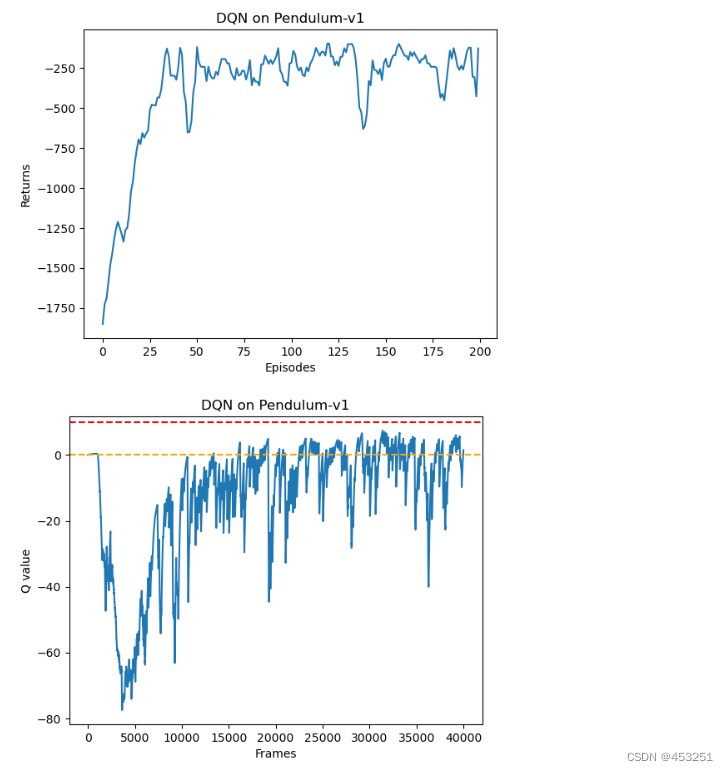
使用DQN
random.seed(0)
np.random.seed(0)
#env.seed(0)
env.reset(seed=0)
torch.manual_seed(0)
replay_buffer=rl_utils.ReplayBuffer(buffer_size)
agent=DQN(state_dim,hidden_dim,action_dim,lr,gamma,epsilon,target_update,device)
return_list,max_q_value_list=train_DQN(agent,env,num_episodes,replay_buffer,minimal_size,batch_size)
episodes_list=list(range(len(return_list)))
mv_return=rl_utils.moving_average(return_list,5)
plt.plot(episodes_list,mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
frames_list=list(range(len(max_q_value_list)))
plt.plot(frames_list,max_q_value_list)
plt.axhline(0,c='orange',ls='--')
plt.axhline(10,c='red',ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('DQN on {}'.format(env_name))
plt.show()
使用Double DQN
random.seed(0)
np.random.seed(0)
#env.seed(0)
env.reset(seed=0)
torch.manual_seed(0)
replay_buffer=rl_utils.ReplayBuffer(buffer_size)
agent=DQN(state_dim,hidden_dim,action_dim,lr,gamma,epsilon,target_update,device,'DoubleDQN')
return_list,max_q_value_list=train_DQN(agent,env,num_episodes,replay_buffer,minimal_size,batch_size)
episodes_list=list(range(len(return_list)))
mv_return=rl_utils.moving_average(return_list,5)
plt.plot(episodes_list,mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
frames_list=list(range(len(max_q_value_list)))
plt.plot(frames_list,max_q_value_list)
plt.axhline(0,c='orange',ls='--')
plt.axhline(10,c='red',ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
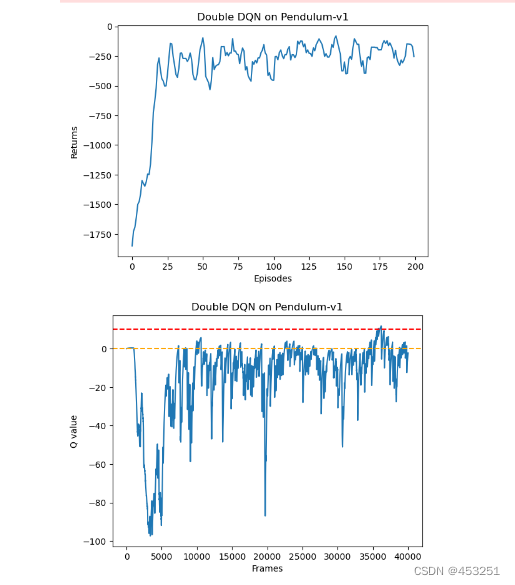
与普通DQN算法相比,Double DQN比较少出现Q值大于0的情况,说明Q值过高估计的问题得到了很大的缓解















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









