







- pandas是为了解决数据分析任务而创建的,纳入了大量的库和标准数据模型,提供了高效地操作大型数据集所需的工具。
- pandas 是第三方库。
【 1. pandas中的数据结构 】
1. Series 一维数组
- 类似于Python中的基本数据结构 list,区别是Series只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。就像数据库中的列数据。
- series 包含一个数组的数据(任何NumPy的数据类型)和一个与数组关联的数据标签,被叫做索引 。最简单的Series是由一个数组的数据构成:
① 默认创建
import pandas as pd
obj=pd.Series([4,7,-5,3])
print(obj)
运行结果:

Series的交互式显示的字符串表示形式是索引在左边,值在右边。因为我们没有给数据指定索引,一个包含整数0到N-1这里N是数据的长度)的默认索引被创建。
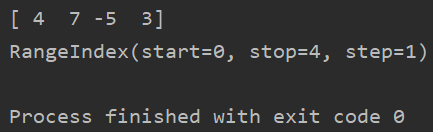
② values、index属性
import pandas as pd
obj=pd.Series([4,7,-5,3])
print(obj.values)
print(obj.index)
运行结果:
③ 自定义索引的Series
import pandas as pd
obj=pd.Series([4,7,-5,3],index=['d','b','a','c'])
print(obj)
运行结果:

④ 字典向series的传递
可以通过传递字典来从这些数据创建一个Series,只传递一个字典的时候,结果Series中的索引将是排序后的字典的键。
import pandas as pd
sdata={'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}
obj=pd.Series(sdata)
print(obj)
运行结果:

⑤ 排序
对索引排序
import pandas as pd
obj = pd.Series(range(4), index=['d','a','b','c'])
print( obj.sort_index() )
运行结果:

对值排序
import pandas as pd
obj=pd.Series([4,7,-5,3])
print( obj.sort_values() )
运行结果:

⑥ 删除行
import pandas as pd
s =pd. Series([4.5,7.2,-5.3,3.6], index=['d','b','a','c'])
print( s )
print()
print( s.drop('c') ) #drop()返回的是一个新对象,原对象不会被改变。
运行结果:

⑦ 层次化索引
层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使我们能在一个轴上拥有多个(两个以上)索引级别。
import pandas as pd
s = pd.Series([4,7,-5,3,5,7,9,2,0,3], index = [['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd' ],[1,2,3,1,2,3,1,2,2,3]])
print(s )
运行结果:

切片索引
import pandas as pd
s = pd.Series([4,7,-5,3,5,7,9,2,0,3], index = [['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd' ],[1,2,3,1,2,3,1,2,2,3]])
print(s )
print()
print(s['b':'d'] )
运行结果:

内层选取
import pandas as pd
s = pd.Series([4,7,-5,3,5,7,9,2,0,3], index = [['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd' ],[1,2,3,1,2,3,1,2,2,3]])
print(s )
print()
print(s[:,2] )
运行结果:

数据重塑
import pandas as pd
s = pd.Series([4,7,-5,3,5,7,9,2,0,3], index = [['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd' ],[1,2,3,1,2,3,1,2,2,3]])
print(s )
print()
print(s.unstack() )
运行结果:

2. DataFrame 二维的表格型数据
很多功能与R中的data.frame类似,可以将DataFrame理解为Series的容器。
DataFrame是一个表格型的数据结构,是以一个或多个二维块存放的数据表格(层次化索引),DataFrame既有行索引还有列索引,它有一组有序的列,每列既可以是不同类型(数值、字符串、布尔型)的数据,或者可以看做由Series组成的字典。
① DataFrame 的创建
import pandas as pd
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = DataFrame(dictionary)
运行结果:

② 修改行名
import pandas as pd
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = pd.DataFrame(dictionary,index=['one','two','three','four','five'])
print(frame)
运行结果:

③ 添加修改
import pandas as pd
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = pd.DataFrame(dictionary)
frame['year']=[0,0,0,0,0]
print(frame)
运行结果:

④ 添加Series类型
import pandas as pd
dictionary = {'state':['0hio','0hio','0hio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = pd.DataFrame(dictionary)
value = pd.Series([1,3,1,4,6,8],index = [0,1,2,3,4,5])
frame['add1'] = value
print(frame)
运行结果:

⑤ 排序
对索引排序
import pandas as pd
frame = pd. DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1]},index=[3,1,4,2])
print( frame )
print()
print( frame.sort_index() ) #默认对行的索引排序
#frame.sort_index(axis=1, ascending=True)
#axis可为0或1,为0时对每行的索引排序;为1时对列的索引排序。
#ascending可为True或False,为True时升序,为False时降序。
运行结果:

对值排序
import pandas as pd
frame = pd. DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1]},index=[3,1,4,2])
print( frame )
print()
print( frame.sort_values(by='b') ) #DataFrame必须传一个by参数表示要排序的列
运行结果:

⑥ 删除
删除行
import pandas as pd
frame = pd. DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1]},index=[3,1,4,2])
print( frame )
print()
print( frame.drop(1) )
运行结果:

删除列
import pandas as pd
frame = pd. DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1],"c":[9,8,7,0]},index=[3,1,4,2])
print( frame )
print()
print( frame.drop(["a"],axis=1) )
运行结果:

⑦ 算术运算(+,-,*,/)
DataFrame中的算术运算是df中对应索引的元素的算术运算,如果没有共同的索引,则用NaN代替。
import pandas as pd
frame1 = pd. DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1],"c":[1,2,3,4] },index=[3,1,4,2])
frame2 = pd. DataFrame({'b':[1, 2, 3, 4], 'a':[1, 2, 3, 4] },index=[3,1,4,2])
print( frame1+frame2 ) #对相同列索引进行算术运算,若有单独索引列,则结果列元素均为NaN
print()
print(frame1.add(frame2,fill_value=1) ) #也可对填充默认值
运行结果:

⑧ 去重
判断是否重复
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行。
import pandas as pd
frame =pd. DataFrame({'k1': ['one'] * 3 + ['two'] * 4, 'k2': [1, 1, 2, 3, 3, 4, 4]})
print( frame )
print()
print(frame.duplicated() )
运行结果:

去除重复行
import pandas as pd
frame =pd. DataFrame({'k1': ['one'] * 3 + ['two'] * 4, 'k2': [1, 1, 2, 3, 3, 4, 4]})
print( frame )
print()
print(frame.drop_duplicates() )
运行结果:

3. Panel 三维的数组
可以理解为DataFrame的容器。
【 2. 读取CSV格式数据 】
在使用机器学习工具包对数据进行修改、探索和分析之前,我们必须先讲外部数据导入。使用Pandas导入数据比Numpy要容易。
# CSV格式内容:
Water Year,Rain (mm) Oct-Sep,Outflow (m3/s) Oct-Sep,Rain (mm) Dec-Feb,Outflow (m3/s) Dec-Feb,Rain (mm) Jun-Aug,Outflow (m3/s) Jun-Aug
1980/81,1182,5408,292,7248,174,2212
1981/82,1098,5112,257,7316,242,1936
1982/83,1156,5701,330,8567,124,1802
1983/84,993,4265,391,8905,141,1078
1984/85,1182,5364,217,5813,343,4313
1985/86,1027,4991,304,7951,229,2595
1986/87,1151,5196,295,7593,267,2826
1987/88,1210,5572,343,8456,294,3154
1988/89,976,4330,309,6465,200,1440
1989/90,1130,4973,470,10520,209,1740
1990/91,1022,4418,305,7120,216,1923
1991/92,1151,4506,246,5493,280,2118
1992/93,1130,5246,308,8751,219,2551
1993/94,1162,5583,422,10109,193,1638
1994/95,1110,5370,484,11486,103,1231
1995/96,856,3479,245,5515,172,1439
1996/97,1047,4019,258,5770,256,2102
1997/98,1169,4953,341,7747,285,3206
1998/99,1268,5824,360,8771,225,2240
1999/00,1204,5665,417,10021,197,2166
2000/01,1239,6092,328,9347,236,2142
2001/02,1185,5402,380,8891,259,3187
2002/03,1021,4366,272,7093,176,1478
2003/04,1165,4275,348,7493,315,2959
2004/05,1095,4547,309,7183,217,1799
2005/06,1046,4059,206,4578,188,1474
2006/07,1387,6391,437,10926,357,5168
2007/08,1225,5497,386,9485,320,3505
2008/09,1139,4941,268,6690,323,3189
2009/10,1103,4738,255,6435,244,1958
2010/11,1053,4521,265,6593,267,2885
2011/12,1285,5500,339,7630,379,5261
2012/13,1090,5329,350,9615,187,1797
1. CSV的读取 pd.read_csv()
从csv文件里导入数据,并储存在DataFrame中,只需要调用read_csv然后将文件的路径传进去即可。
# Reading a csv into Pandas.
# 如果数据集中有中文的话,最好在里面加上 encoding = 'gbk' ,以避免乱码问题。后面的导出数据的时候也一样。
import pandas as pd
df = pd.read_csv('uk_rain_2014.csv', header=0)
#header 关键字告诉Pandas哪些是数据的列名。如果没有列名的话就将它设定为 None。
2. 查看前n行 pd.head(n)
import pandas as pd
df = pd.read_csv('uk_rain_2014.csv', header=0)
print(df.head(5) )
运行结果:

3. 查看后n行 pd.tail(n)
import pandas as pd
df = pd.read_csv('uk_rain_2014.csv', header=0)
df.tail(5)
运行结果:

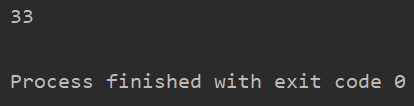
4. 查看总行数 len()
import pandas as pd
df = pd.read_csv('uk_rain_2014.csv', header=0)
print(len(df))
运行结果:
5. 修改列名 df.columns
import pandas as pd
df = pd.read_csv('0.csv', header=0)
df.columns = ['water_year','rain_octsep','outflow_octsep','rain_decfeb', 'outflow_decfeb', 'rain_junaug', 'outflow_junaug']
print(df.head(5) )
运行结果:

















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











