







1.介绍
什么是pandas?
Pandas(Python Data Analysis Library )是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
为什么要使用pandas
Pandas含有使数据分析工作变得更快更简单的高级数据结构和操作工具。pandas是基于Numpy构建的,让以Numpy为中心的应用变得更简单。
Python、Numpy和Pandas对比

介绍了上面一系列的晦涩的概念之后,我们还是要进行实际操作让我们更加深入理解pandas
- Pandas的核心为两大数据结构,数据分析相关所有事物都是围绕着这两种结构进行的:
Series
DataFrame Series这样的数据结构用于存储一个序列的一维数据,而DataFrame作为更复杂的数据结构,则用于存储多维数据。
2.Series
Series是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series.
2.1.Series的基本操作
# 直接传入数组创建seris
# index默认是0,1,2,3,...
import pandas as pd
seris = pd.Series([i for i in range(10)])
print(seris)
# 输出
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# dtype: int64
# 访问所有下标,返回一个RangeIndex类型
# 强制转换成list类型后输出
indexs = seris.index
print(list(indexs))
# 输出
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 访问所有的值,并返回一个numpy.ndarray类型
values = seris.values
print(values)
print(type(values))
# [0 1 2 3 4 5 6 7 8 9]
# <class 'numpy.ndarray'>
# 传入字典创建Series数组
# 字典的键就是对应值的index
dict1 = {'name':'zhangsan','sex':'nan','age':39}
seris = pd.Series(dict1)
print(seris)
# 输出
# name zhangsan
# sex nan
# age 39
# dtype: object
# 也可以指定index,传入一个数组
# 但是index=array,array数组元素的个数要与前面的一致
series = pd.Series([1,2,3,4,5,6],index=list('ABCDEF'))
print(series)
# 输出
# A 1
# B 2
# C 3
# D 4
# E 5
# F 6
# dtype: int64
# Series:
# A 1
# B 2
# C 3
# D 4
# E 5
# F 6
# dtype: int64
# series的两种访问方式
print(series['A'])
print('-'*20)
print(series[0])
print('-'*20)
# series的筛选
print(series[series >= 3])
# 输出
# 1
# --------------------
# 1
# --------------------
# C 3
# D 4
# E 5
# F 6
# dtype: int64
# Series转化为字典
# Series:
# A 1
# B 2
# C 3
# D 4
# E 5
# F 6
# dtype: int64
dict1 = series.to_dict()
print(dict1)
# 输出
# {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6}
# 也可以在传入字典的同时设置新的index,不使用原来的key1作为index
dict1 = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6}
series1 = pd.Series(dict1,index = list('ABCDEFG'))
series2 = pd.Series(dict1,index = range(7))
print('series1:\n',series1)
print()
print('series2:\n',series2)
# 输出
# series1:
# A 1.0
# B 2.0
# C 3.0
# D 4.0
# E 5.0
# F 6.0
# G NaN
# dtype: float64
# series2:
# 0 NaN
# 1 NaN
# 2 NaN
# 3 NaN
# 4 NaN
# 5 NaN
# 6 NaN
# dtype: float64
# series1:
# A 1.0
# B 2.0
# C 3.0
# D 4.0
# E 5.0
# F 6.0
# G NaN
# dtype: float64
# 若是NaN,则返回True,反之则返回False
print(pd.isnull(series1))
print('*'*20)
# 若不是NaN,则返回True,反之返回False
print(pd.notnull(series1))
# 输出
# A False
# B False
# C False
# D False
# E False
# F False
# G True
# dtype: bool
# ********************
# A True
# B True
# C True
# D True
# E True
# F True
# G False
# dtype: bool
# Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切
series1.name = 'DEOM1'
series1.index.name = 'demo_index'
print(series1.name)
print(series1.index.name)
print('*'*20)
print(series1)
print('*'*20)
print(series1.index)
# 输出
# DEOM1
# demo_index
# ********************
# demo_index
# A 1.0
# B 2.0
# C 3.0
# D 4.0
# E 5.0
# F 6.0
# G NaN
# Name: DEOM1, dtype: float64
# ********************
# Index(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype='object', name='demo_index')
# Series的索引可以通过赋值的方式就地修改
series = pd.Series([1,2,3,4,5,6],index=list('abcdef'))
print('series:\n',series)
# 修改series的index的值
series.index = range(6)
print('*'*20)
print('series:\n',series)
# 输出
# series:
# a 1
# b 2
# c 3
# d 4
# e 5
# f 6
# dtype: int64
# ********************
# series:
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# 5 6
# dtype: int64
2.2.选取操作
series1 = pd.Series([10,20,30],index=list('abc'))
# 下标查询单个元素
print('下标查询单个元素')
print(series1[1])
print(series1['b'])
# 下标查询多个元素,注意:传入的是一个列表
print('\n下标查询多个元素')
print(series1[[0,2]])
print(series1[['a','c']])
# 切片查询
print('\n切片查询')
print(series1[1:2])
# 注意:输入数字的时候是左闭右开,输入下标就是一个闭区间
print(series1['a':'c'])
# 布尔值索引查询
print(series1[series1 >= 20])
# 输出
# 下标查询单个元素
# 20
# 20
# 下标查询多个元素
# a 10
# c 30
# dtype: int64
# a 10
# c 30
# dtype: int64
# 切片查询
# b 20
# dtype: int64
# a 10
# b 20
# c 30
# 布尔值索引查询
# dtype: int64
# b 20
# c 30
# dtype: int64
2.3. 删除操作
# drop删除数据之后,返回删除后的副本
series1 = pd.Series([10,20,30,40,50,60],index=list('abcdef'))
print(series1)
print('\n删除后的数组')
print(series1.drop('c'))
# 输出
# a 10
# b 20
# c 30
# d 40
# e 50
# f 60
# dtype: int64
# 删除后的数组
# a 10
# b 20
# d 40
# e 50
# f 60
# dtype: int64
# Series.pop在删除源数据的元素
# series1
# a 10
# b 20
# c 30
# d 40
# e 50
# f 60
# dtype: int64
print(series1.pop('d'))
print(series1)
# 输出
# 40
# a 10
# b 20
# c 30
# e 50
# f 60
# dtype: int64
2.4.插入操作
# append()插入操作
series1 = pd.Series([10,20,30],index=list('abc'))
series2 = pd.Series([100,300],index=list('eg'))
# 直接插入
series1['f'] = 200
# append()插入
series3 = series1.append(series2)
print(series3)
# 输出
# a 10
# b 20
# c 30
# f 200
# e 100
# g 300
# dtype: int64
2.5.Series运算
import numpy as np
series1 = pd.Series([10,20,30],index=list('abc'))
series2 = pd.Series([1,2,3],index=list('abe'))
print(series1 * 2)
# 自动对齐计算
print(series1*series2)
# 使用numpy函数
print(np.sum(series1))
print(np.add(series1,series2))
# 由于只能比较标记相同的系列对象,所以我们只比较纤两个
print(np.greater(series1[:2],series2[:2]))
# 输出
# a 20
# b 40
# c 60
# dtype: int64
# a 10.0
# b 40.0
# c NaN
# e NaN
# dtype: float64
# 60
# a 11.0
# b 22.0
# c NaN
# e NaN
# dtype: float64
# a True
# b True
# dtype: bool
3.DataFrame
DataFrame这种列表式的数据结构和Excel工作表非常类似,其设计初衷是将Series的使用场景由一维扩展到多维. DataFrame由按一定顺序的多列数据组成,各列的数据类型可以有所不同(数值、字符串、布尔值).
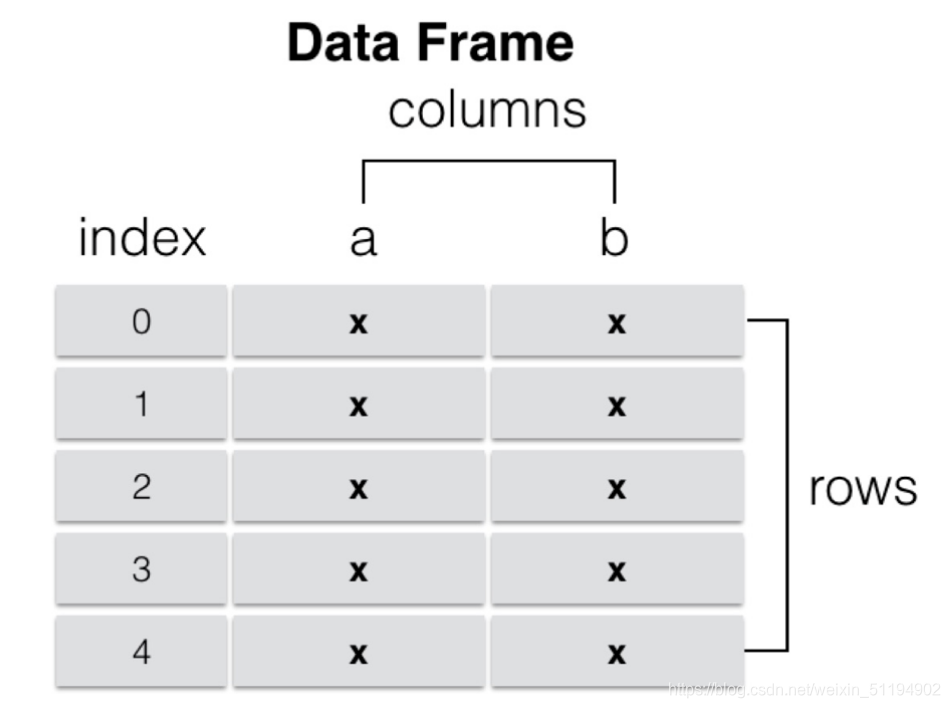
DataFrame还可以理解为一个由Series组成的字典,其中每一列的列名为字典的键,每一个Series作为字典的值,图示
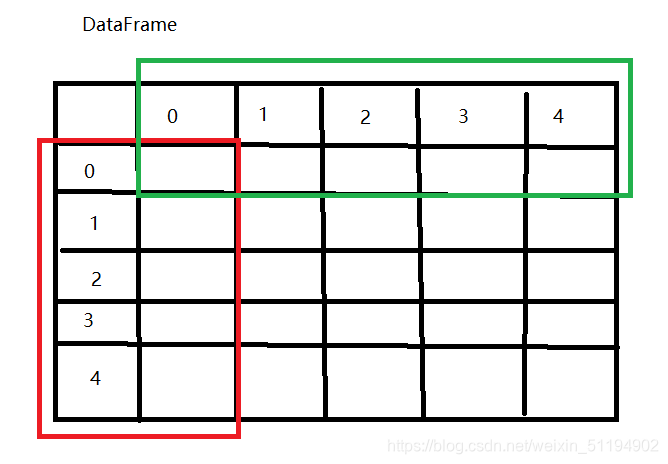
可以发现,DataFrame不管是从横向还是纵向,都可以看作是一个Series,Series其实就是一个带有下标的数组,和字典是很类似的。
3.1.dataframe的创建
# 通过numpy二维数组创建DataFrame
arr = np.arange(12).reshape(3,4)
data_frame = pd.DataFrame(arr)
print(data_frame)
# 输出
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
# 通过列表创建DataFrame
data_frame1 = pd.DataFrame([1, 2, 3, 4, 5])
data_frame2 = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(data_frame1)
print(data_frame2)
# 输出
# 0
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# 0 1 2
# 0 1 2 3
# 1 4 5 6
# 2 7 8 9
# # 通过字典创建DataFrame(1)
# 通过字典创建DataFrame(1)
persons = {
'name': ['小睿', '小丽', '小明', '小红'],
'age': [19, 18, 18, 17],
'sex': ['男', '男', '女', '男'],
}
# 字典的key作为列索引
data_frame = pd.DataFrame(persons)
print(data_frame)
# 输出
# name age sex
# 0 小睿 19 男
# 1 小丽 18 男
# 2 小明 18 女
# 3 小红 17 男
# 通过字典创建DataFrame(2)
contries = {
'中国': {'2013': 10, '2014': 20, '2015': 30},
'阿富汗': {'2013': 12, '2014': 25, '2015': 33},
'新加坡': {'2013': 11, '2014': 22, '2015': 38},
'柬埔寨': {'2013': 18, '2014': 16, '2015': 27},
}
# 外层key做列索引,内层key做行索引
data_frame = pd.DataFrame(contries)
print(data_frame)
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
3.2.DataFrame索引
# DataFrame索引操作
contries = {
'俄罗斯': {'2013': 10, '2014': 20, '2015': 30},
'阿富汗': {'2013': 12, '2014': 25, '2015': 33},
'新加坡': {'2013': 11, '2014': 22, '2015': 38},
'柬埔寨': {'2013': 18, '2014': 16, '2015': 27},
}
# 外层key做列索引,内层key做行索引
data_frame = pd.DataFrame(contries)
print(data_frame)
# 输出行索引
print(data_frame.index)
# 输出列索引
print(data_frame.columns)
print('-'*20)
# 修改行索引
data_frame.index = list('abc')
# 修改列索引
data_frame.columns = list('1234')
print(data_frame)
# 输出
# 俄罗斯 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# Index(['2013', '2014', '2015'], dtype='object')
# Index(['俄罗斯', '阿富汗', '新加坡', '柬埔寨'], dtype='object')
# --------------------
# 1 2 3 4
# a 10 12 11 18
# b 20 25 22 16
# c 30 33 38 27
# 访问列,直接输入字符串就是访问列
contries = {
'中国': {'2013': 10, '2014': 20, '2015': 30},
'阿富汗': {'2013': 12, '2014': 25, '2015': 33},
'新加坡': {'2013': 11, '2014': 22, '2015': 38},
'柬埔寨': {'2013': 18, '2014': 16, '2015': 27},
}
data_frame = pd.DataFrame(contries)
print(data_frame)
# 获取列数据
print('*'*20)
print(data_frame['中国'])
# 获取多组列数据
print(data_frame[['中国','阿富汗','新加坡']])
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# ********************
# 2013 10
# 2014 20
# 2015 30
# Name: 中国, dtype: int64
# 中国 阿富汗 新加坡
# 2013 10 12 11
# 2014 20 25 22
# 2015 30 33 38
# 访问行的两种方式,iloc,loc
# 对于DataFrame的行的标签索引,我引入了特殊的
# 标签运算符loc和iloc。它们可以让你用类似NumPy的
# 标记,使用轴标签(loc)或整数索引(iloc),
# 从DataFrame选择行和列的子集。
contries = {
'中国': {'2013': 10, '2014': 20, '2015': 30},
'阿富汗': {'2013': 12, '2014': 25, '2015': 33},
'新加坡': {'2013': 11, '2014': 22, '2015': 38},
'柬埔寨': {'2013': 18, '2014': 16, '2015': 27},
}
data_frame = pd.DataFrame(contries)
print(data_frame)
print('*'*20)
print(data_frame.iloc[:,:2])
print('*'*20)
print(data_frame.loc['2014'])
print('*'*20)
print(data_frame.loc[['2014','2015']])
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# ********************
# 中国 阿富汗
# 2013 10 12
# 2014 20 25
# 2015 30 33
# ********************
# 中国 20
# 阿富汗 25
# 新加坡 22
# 柬埔寨 16
# Name: 2014, dtype: int64
# ********************
# 中国 阿富汗 新加坡 柬埔寨
# 2014 20 25 22 16
# 2015 30 33 38 27
# 查找阿富汗大于15的行的两种方式
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
print(data_frame.loc[data_frame['阿富汗'] > 15])
print(data_frame.loc[data_frame.阿富汗 > 15])
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2014 20 25 22 16
# 2015 30 33 38 27
# 中国 阿富汗 新加坡 柬埔寨
# 2014 20 25 22 16
# 2015 30 33 38 27
# 查找中国大于15的行,保留中国 阿富汗 两列
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
print(data_frame.loc[data_frame.中国 > 12, ['阿富汗', '中国']])
# 输出
# 阿富汗 中国
# 2014 25 20
# 2015 33 30
# 位置下标获取行数据
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# 切片获得区间数据,以下两种效果一样
print(data_frame1.iloc[1:])
# 输入数字就是行索引,输入字符串就是列索引
print(data_frame1[1:])
# 输出
# 0
# 1 2
# 2 3
# 3 4
# 4 5
# 0
# 1 2
# 2 3
# 3 4
# 4 5
3.3.Dataframe插入数据
# 在DataFrame中插入数据的几种方式
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
import pandas as pd
series1 = pd.Series([100, 200, 300, 400], index=['阿富汗', '柬埔寨', '新加坡', '中国'], name='2019')
data_frame.loc['2016'] = 66
data_frame.loc['2017'] = [23, 24, 25, 26]
data_frame.loc['2018'] = series1
# append调用之后会产生数据副本
data_frame2 = data_frame.append(series1)
print(data_frame2)
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# 2016 66 66 66 66
# 2017 23 24 25 26
# 2018 400 100 300 200
# 2019 400 100 300 200
# 在最后一列,新增一列数据
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# 2016 66 66 66 66
# 2017 23 24 25 26
# 2018 400 100 300 200
# 2019 400 100 300 200
series = pd.Series(list(range(7)),index=[str(x) for x in range(2013,2020)])
data_frame['法兰西'] = series
print(data_frame)
# 输出
# 中国 阿富汗 新加坡 柬埔寨 法兰西
# 2013 10 12 11 18 0
# 2014 20 25 22 16 1
# 2015 30 33 38 27 2
# 2016 66 66 66 66 3
# 2017 23 24 25 26 4
# 2018 400 100 300 200 5
3.4.Dataframe中删除数据
# 删除列
# 中国 阿富汗 新加坡 柬埔寨 法兰西
# 2013 10 12 11 18 0
# 2014 20 25 22 16 1
# 2015 30 33 38 27 2
# 2016 66 66 66 66 3
# 2017 23 24 25 26 4
# 2018 400 100 300 200 5
del data_frame['法兰西']
print(data_frame)
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2013 10 12 11 18
# 2014 20 25 22 16
# 2015 30 33 38 27
# 2016 66 66 66 66
# 2017 23 24 25 26
# 2018 400 100 300 200
# 删除行
# pop() 在数据源中删除数据
# drop() 不影响数据源,返回删除后的副本
# 中国 阿富汗 新加坡 柬埔寨 法兰西
# 2013 10 12 11 18 0
# 2014 20 25 22 16 1
# 2015 30 33 38 27 2
# 2016 66 66 66 66 3
# 2017 23 24 25 26 4
# 2018 400 100 300 200 5
new_data_frame = data_frame.drop(['2013','2018'],axis=0)
print(new_data_frame)
data_frame.pop('中国')
print(data_frame)
# 输出
# 中国 阿富汗 新加坡 柬埔寨
# 2014 20 25 22 16
# 2015 30 33 38 27
# 2016 66 66 66 66
# 2017 23 24 25 26
# 阿富汗 新加坡 柬埔寨
# 2013 12 11 18
# 2014 25 22 16
# 2015 33 38 27
# 2016 66 66 66
# 2017 24 25 26
# 2018 100 300 200
3.5.DataFrame算数运算和数据对齐
Series之间运算,遵循索引对齐
DataFrame运算会对齐行和列索引
# DataFrame的算术运算
# DataFrame运算会对齐行和列索引
import numpy as np
data_frame1 = pd.DataFrame(np.arange(12).reshape(3,4),index=['fir','sec','thr'],columns=['a','b','c','d'])
print('data_frame1:\n',data_frame1)
data_frame2 = pd.DataFrame(np.arange(10,22).reshape(4,3),index=['fir','sec','thr','for'],columns=['a','b','c'])
print('\ndata_frame2:\n',data_frame2)
print()
print(data_frame1 + data_frame2)
# 输出
# data_frame1:
# a b c d
# fir 0 1 2 3
# sec 4 5 6 7
# thr 8 9 10 11
# data_frame2:
# a b c
# fir 10 11 12
# sec 13 14 15
# thr 16 17 18
# for 19 20 21
# a b c d
# fir 10.0 12.0 14.0 NaN
# for NaN NaN NaN NaN
# sec 17.0 19.0 21.0 NaN
# thr 24.0 26.0 28.0 NaN
# 在算数方法中填充值,当某个标签在另一个对象中找不到时填充一个值。
# 之后再进行相加
print(data_frame1.add(data_frame2, fill_value=0))
# a b c d
# fir 10.0 12.0 14.0 3.0
# for 19.0 20.0 21.0 NaN
# sec 17.0 19.0 21.0 7.0
# thr 24.0 26.0 28.0 11.0
DataFrame和Series之间的运算
- 我们刚刚说到,不管从横向还是纵向DataFrame都可以看作是多个Series的组合,所以二者之间也可以进行计算,类似于广播原则
# DataFrame每一行都加上series
data_frame2 = pd.DataFrame(np.arange(9).reshape((3, 3)),
index=['a', 'b', 'c'],
columns=['num1', 'num2', 'num3'])
series2 = pd.Series([10, 20, 30, 40],
index=['num1', 'num2', 'num3', 'num4'])
# DataFrame每一行都加上series
print(data_frame2 + series2)
# 输出
# num1 num2 num3 num4
# a 10 21 32 NaN
# b 13 24 35 NaN
# c 16 27 38 NaN
# DataFrame每一列加上series
series3 = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
print(data_frame2.add(series3, axis=0))
# num1 num2 num3
# a 10.0 11.0 12.0
# b 23.0 24.0 25.0
# c 36.0 37.0 38.0
# d NaN NaN NaN
4. pandas中函数应用apply
pandas库以Numpy为基础,并对它的很多功能进行了扩展,用来操作新的数据结构Series和DataFrame.通用函数(ufunc, universal function)就是扩展得到的功能,这类函数能够对数据结构中的元素进行操作,特别有用.除了通用函数,用户还可以自定义函数。
4.1.Pandas排序
根据条件对数据集进行排序也是一种重要的内置运算. 要对行或列索引进行排序,可使用sort_index方法,要根据元素值来排序,可使用sort_values.
def sort_index(self, axis=0, ascending=True, inplace=False):
pass
def sort_values(self, by, axis=0, ascending=True, inplace=False):
pass
- axis: 按行还是按列排序.
- ascending: 升序还是降序,默认True是升序排列,False降序排序.
- nplace: 默认False, 返回排序副本. True表示直接修改序列本身
4.1.1.对Series排序
代码演示:
# Series排序
series = pd.Series(np.random.randint(2,10,4),index=['d','a','c','b'])
print(series)
# 按下标排序
print(series.sort_index())
# 按值排序
print(series.sort_values())
# 输出
# d 7
# a 7
# c 5
# b 2
# dtype: int32
# a 7
# b 2
# c 5
# d 7
# dtype: int32
# b 2
# c 5
# d 7
# a 7
# dtype: int32
# 降序排序
# d 7
# a 7
# c 5
# b 2
# dtype: int32
print(series.sort_index(ascending=False))
# 输出
# d 7
# c 5
# b 2
# a 7
# dtype: int32
4.1.2.对DataFrame排序
# DataFrame根据下标排序 sort_index()
# 0 1 2 3 4
# b 15 10 15 10 12
# c 10 9 11 3 2
# d 18 13 5 3 1
# a 3 8 6 4 10
# e 13 8 17 3 14
data_frame.sort_index(ascending=False,inplace=True)
print(data_frame)
# 输出
# 0 1 2 3 4
# b 15 10 15 10 12
# c 10 9 11 3 2
# d 18 13 5 3 1
# a 3 8 6 4 10
# e 13 8 17 3 14
# 按照值排序 sort_values()
# by后面加列名,根据那一列的顺序来排序,以下是根据第1列的数字排序
# 0 1 2 3 4
# b 15 10 15 10 12
# c 10 9 11 3 2
# d 18 13 5 3 1
# a 3 8 6 4 10
# e 13 8 17 3 14
data_frame.sort_values(by=1,inplace=True)
print(data_frame)
# 0 1 2 3 4
# e 13 8 17 3 14
# a 3 8 6 4 10
# c 10 9 11 3 2
# b 15 10 15 10 12
# d 18 13 5 3 1
4.1.3.等级索引和分级
data_frame1 = DataFrame(
np.arange(0, 360, 10).reshape((6, 6)),
index=[
['北京市', '北京市', '河北省', '河北省', '河南省', '河南省'],
['昌平区', '海淀区', '石家庄', '张家口', '驻马店', '平顶山'],
],
columns=[
['轻工业', '轻工业', '重工业', '重工业', '服务业', '服务业'],
['纺织业', '食品业', '冶金业', '采煤业', '教育业', '游戏业'],
]
)
data_frame1
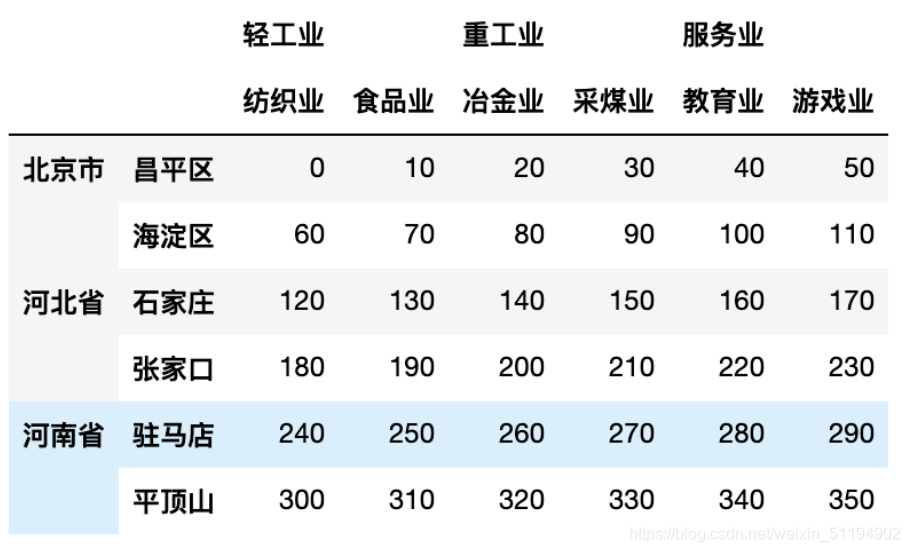
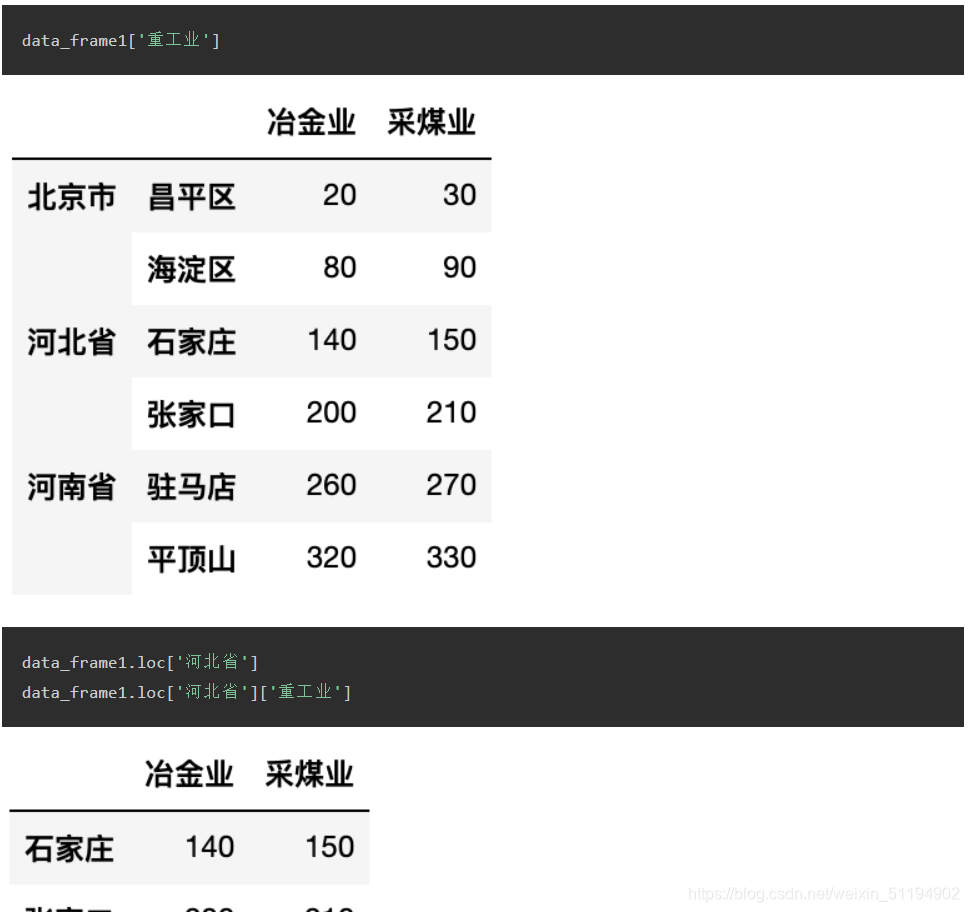
- 访问方式也是用loc和iloc
5.处理缺失数据
- 删除NaN
# dropna()直接删除NaN
# 默认丢弃包含NaN的行
data_frame = pd.DataFrame([
[10, 20, 30, 40, 50],
[11, 21, np.nan, 41, np.nan],
[12, 22, 32, 42, 52],
[np.nan, 66, np.nan, np.nan, np.nan],
[np.nan, 24, np.nan, 44, 54],
])
print(data_frame)
print('\n默认丢弃包含NaN的行')
# 默认丢弃包含NaN的行
print(data_frame.dropna())
print('\n丢弃包含NaN的列')
# 丢弃包含NaN的列
print(data_frame.dropna(axis=1))
print('\n删除所有元素是NaN的行或列')
# 如果只是想删除所有元素是NaN的行或列, 需要参数how='all'
print(data_frame.dropna(how='all', axis=1))
# 输出
# 0 1 2 3 4
# 0 10.0 20 30.0 40.0 50.0
# 1 11.0 21 NaN 41.0 NaN
# 2 12.0 22 32.0 42.0 52.0
# 3 NaN 66 NaN NaN NaN
# 4 NaN 24 NaN 44.0 54.0
# 默认丢弃包含NaN的行
# 0 1 2 3 4
# 0 10.0 20 30.0 40.0 50.0
# 2 12.0 22 32.0 42.0 52.0
# 丢弃包含NaN的列
# 1
# 0 20
# 1 21
# 2 22
# 3 66
# 4 24
# 删除所有元素是NaN的行或列
# 0 1 2 3 4
# 0 10.0 20 30.0 40.0 50.0
# 1 11.0 21 NaN 41.0 NaN
# 2 12.0 22 32.0 42.0 52.0
# 3 NaN 66 NaN NaN NaN
# 4 NaN 24 NaN 44.0 54.0
- 填充NaN
# 填充NaN的值
print(data_frame.fillna(666))
# 每一列替换为不同的值, 目前不支持对按行填充不同值的功能.
print(data_frame1.fillna({0: 100, 1: 200, 2:300, 3: 400, 4: 500}))
6. 数据准备
6.1.数据组装
对于存储在pandas对象中的各种数据,组装的方法有以下几种:
- 合并–pandas.merge()函数根据一个或多个键连接多行.
- 拼接–pandas.concat()函数按照轴把多个对象拼接起来.
- 结合–pandas.DataFrame.combine_first()函数从另外一个数据结构获取数据,连接重合的数据,填充缺失值.
6.2.数据合并
- 准备数据
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
data_frame1 = DataFrame({
'name': ['John', 'Edward', 'Smith', 'Obama', 'Clinton' ],
'ages1': [18, 16, 15, 14, 19]
})
data_frame2 = DataFrame({
'name': ['John', 'Edward', 'Polly', 'Obama' ],
'ages2': [19, 16, 15, 14]
})
data_frame3 = DataFrame({
'other_name': ['John', 'Edward', 'Smith', 'Obama', 'Bush' ],
'other_ages': [18, 16, 15, 14, 20]
})
# 输出
# name ages1
# 0 John 18
# 1 Edward 16
# 2 Smith 15
# 3 Obama 14
# 4 Clinton 19
# ----------
# name ages2
# 0 John 19
# 1 Edward 16
# 2 Polly 15
# 3 Obama 14
# ----------
# other_name other_ages
# 0 John 18
# 1 Edward 16
# 2 Smith 15
# 3 Obama 14
# 4 Bush 20
# 默认根据相同列名作为键连接两个DataFrame,
# 并且内连接方式(inner, 取两边都有的数据, 交集)
# 那么请问, 当我将data_frame2的列名ages2改为ages1时,结果是多少?
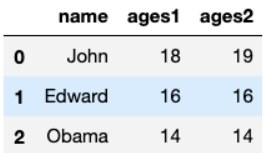
pd.merge(data_frame1, data_frame2, on='name')
- 以name键为标准连接数据,取双方的交集,不在这个交集内的name被删除
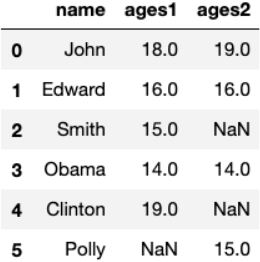
# 可修改连接方式为外连接(outer),取两边都有数组, 缺失数据使用NaN表示
pd.merge(data_frame1, data_frame2, how='outer')
- 取双方的并集
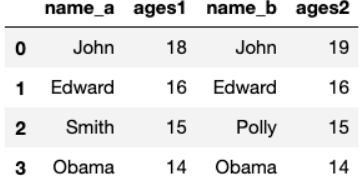
# 当两个DataFrame没有公共相同的列名的时候,那么合并就会报错.
# MergeError: No common columns to perform merge on
# 此时我们可指定DataFrame用那一列名来连接另一个DataFrame的那个列名
# 使用参数 left_on 和 right_on
pd.merge(data_frame1, data_frame3, left_on='name', right_on='other_name')
















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











