







为了了解SVM,我们需要从逻辑回归出发。
这是逻辑回归的函数式以及函数图像
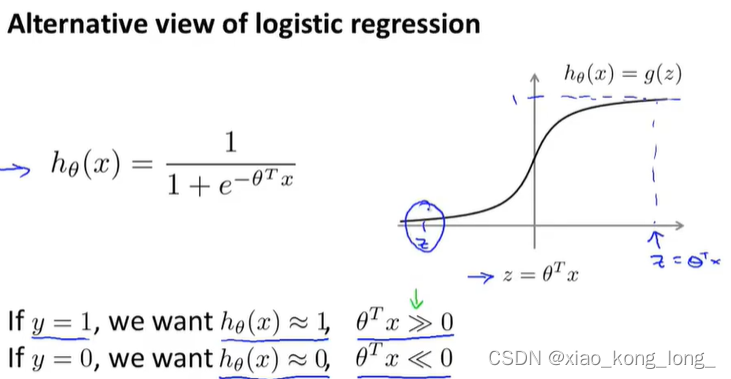
现在来看看逻辑回归的损失函数

这个函数看起来很复杂,其实不然,因为y的取值只能是0和1,所以这是一个分类讨论的情况
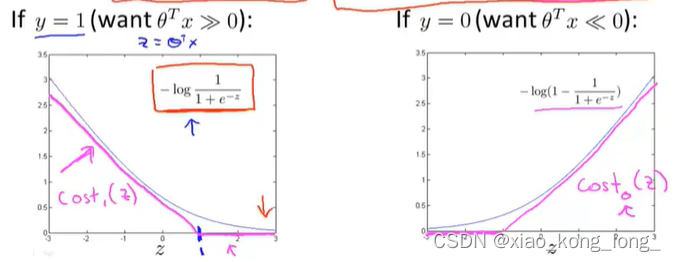
这是分类讨论的结果,当y=1的时候,是左图的函数,要想它为0,则必须要远大于0,此时,我们可以用一个折线来近似模拟曲线,我们称此折线为
。y=0的情况也类似。
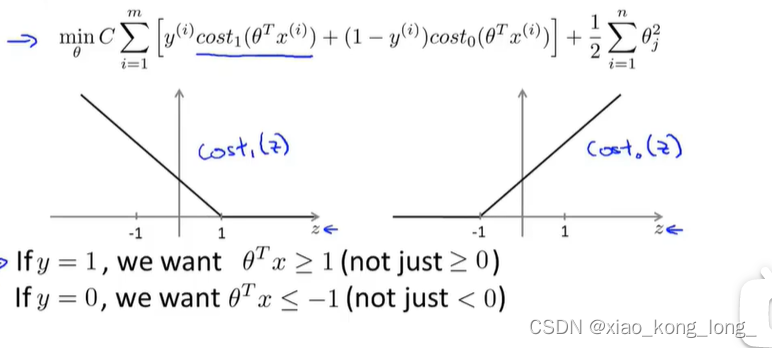
于是,我们通过替换之前两种情况的函数,可以得到SVM的损失函数

损失函数除了替换部分外,还进行了一些形式上的变换,但影响不大。
通过最小化新的损失函数,我们可以得到最终的。
对于此后的x,我们通过以下式子来完成分类任务:

SVM是大间隔分类器的解释
当我们把C设得非常大时,SVM会寻找使得间距最大的直线作为分类器,因此,可以说SVM是一类“健壮”的算法。但是对于异常点,SVM会很敏感。
下面给出为什么SVM会寻求大间隔的数学解释
首先,我们看一下SVM的损失函数
可以看到,不像logistic regression,判断一个样本的类别只需比较与0的大小关系就好了,SVM的判断更为严苛。
看一下向量内积的的计算

在这幅图中可以看出,向量的内积可以通过用一向量投影的长度与另一向量的长度的乘积来求。
如果把C设的很大,我们的优化目标变为如下结果:

解释:由于C设得很大,所以我们要尽可能地让前面这一项(除去C)等于0,导致如果样本的值为1时,我们必须保证
的值必须要大于等于1,所以我们可以把将其设置为必要的条件,在满足必要条件的前提下尽可能让第二项更小,就得到了上图的式子。
为了便于讨论,做了一些简单化:,再将theta与x的内积转换成投影长度和向量长度的乘积,可以得到如下的优化目标:

下面来讨论两种划分情况:
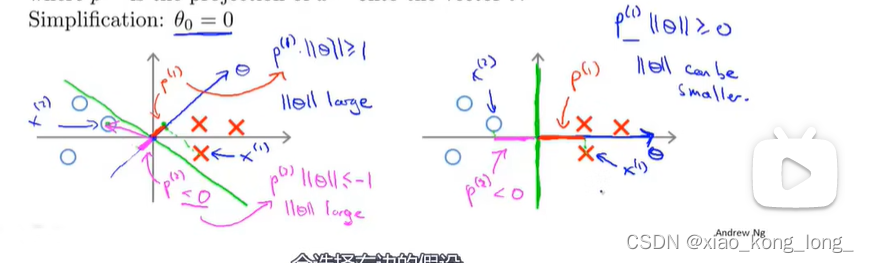
由于,所以直线必经过原点,然后
向量与直线垂直。
左图中,由于投影长度p很小,为了保证s.t.中的条件,要让的长度很大才行,而右图中的投影长度比较大,很小的
长度就可以满足,而优化目标就是使其长度尽可能小,所以,当参数C设置很大时,SVM倾向于右边这种情况。
对于的情况,以上结论同样适用。
SVM的核函数改进
SVM用于处理线性划分问题,当面对一些非线性划分问题,SVM也能通过引入核函数来进行求解
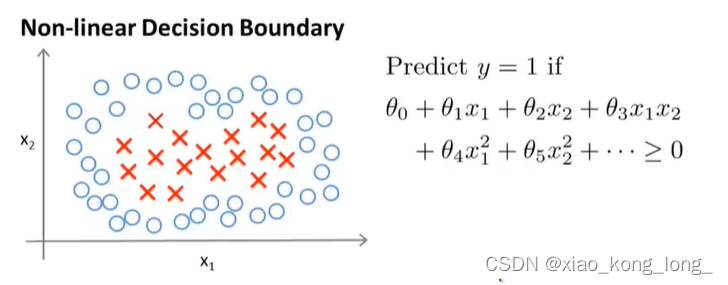
这就是一个非线性划分问题,纯粹的线性函数已经不再适用,我们可以通过使用复杂的多项式来模拟间隔边界。如右边的x1,x2,x1x2等。我们可以把这些多项式项抽离出来,设为f1,f2,f3,它们被称为特征向量(landmark)。它们都是固定的常数向量,下图显示了两个变量下的几个特征向量。

我们定义两个向量的相似度函数如下:
相似度函数有如下特性:
1、当两向量很接近时,函数值接近1;
2、当两向量很远时,函数值接近0。
我们也称similarity函数为核函数(这里是高斯核函数) kernel function(Gaussian kernel funciton)
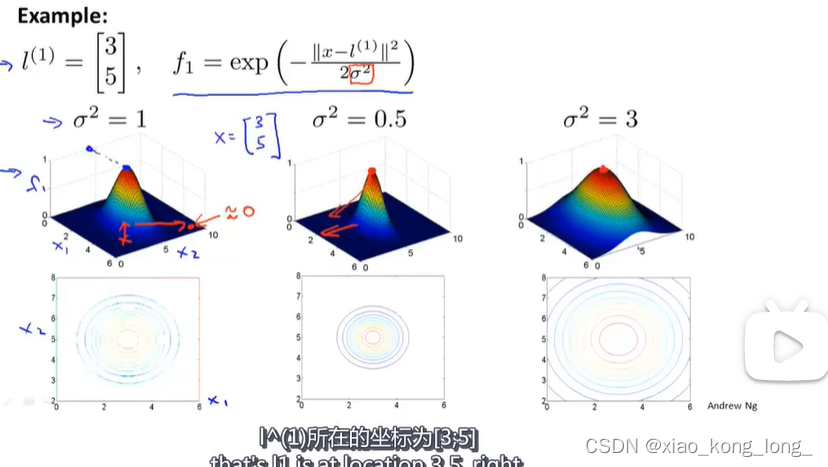
超参数对函数图像的影响,如下图所示
样本判别方法:
特征向量的选择:
选择每一个训练样本当做特征向量,这样的话,对于每一个样本来说,可以衡量他到每一个训练样本的距离。
假设训练样本有m个,那么对于x来说,就会产生m个核函数值,把他们拼接在一起,再拼个,就可以得到一个m+1 * 1的向量。 我们称
对应的向量为
。
把核技巧用于SVM中:
1、判定过程
2、训练过程
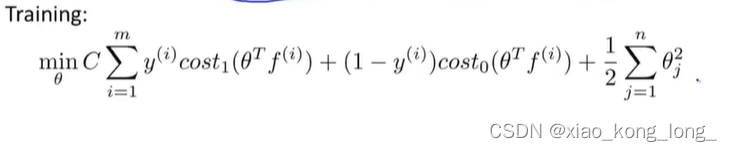
就是把原来的 换成了
,这是一个很重要的思想,用核函数拼接成的向量来表示非线性特征,从而达到非线性划分的效果。
对于正则化项的一些讨论
1、n = m
2、在实际编码过程中,可以通过 来快速求解
3、当样本数量较多时,可以通过来作为正则化项,来减少运算量
对于参数选择的一些讨论

这个图很好的描述了超参数C和对偏差和方差的影响。
参考资料
[中英字幕]吴恩达机器学习系列课程_哔哩哔哩_bilibili
PLUS
水印很影响观感,但是我目前没有找到去除水印的方法,原来CSDN上的方法感觉不奏效,等我找到了就回来改了。















 1689
1689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









