







Transformer模型中的自注意力(self-attention)机制是通过一种特定的方式让模型学习到输入序列中不同为止的词之间的相关性。那么自注意力是怎么发挥作用,又是如何进行计算的呢,接下来我们就来举例详细说明一下。
计算步骤
自注意力机制能够确定哪些词与当前词的关系最为密切,主要计算关键步骤如下:
-
查询、键和值的生成
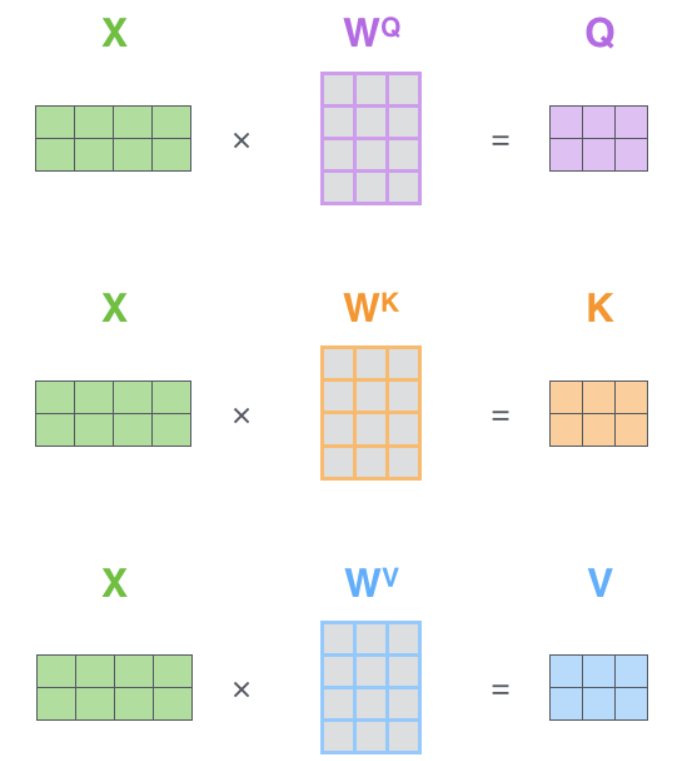
对于输入序列中的每一个词,模型都会生成三个向量:查询向量(Query)、键向量(Key)和值向量(Value)。这些向量是由输入嵌入通过不同的线性变换得到的。查询向量代表了我们要关注的信息,而键向量则表示每个词的特点,用于和其他词的查询向量进行比较。
-
计算注意力分数
注意力分数通过计算查询向量和所有其他位置的键向量之间的相似度来获得。通常使用点积(内积)相似度,即查询向量和键向量的点积,然后除以一个缩放因子(根号下键向量的维度大小),以避免除数过大导致的梯度消失问题。最终得到的分数经过softmax函数转换为概率分布,表示在给定查询向量的情况下,其他各个位置的重要性。
-
加权平均
根据得到的概率分布,将各个位置的值向量进行加权平均,得到最终的注意力输出。这一步骤中,概率越高的值向量对结果的影响越大,从而实现了对重要词的关注。
-
多头注意力
为了增强模型捕捉不同位置关系的能力,Transformer使用多头注意力机制。它将上述过程重复多次,每次使用不同的线性变换矩阵来生成查询、键和值向量。这样可以捕捉到输入序列中多种类型的依赖关系,并将他们整合到一起。
以"The cat is sitting on the mat."为例,如果要计算cat和mat的关系,自注意力机制并不直接假设cat和mat的查询向量和键向量有一定的相似度,而是通过训练过程学习这种关联性的。
初始状态
在训练初期,查询向量和键向量都是由随机初始化的权重矩阵生成的,这些权重矩阵通常没有预设的关联性。这意味着在训练开始阶段,cat和mat的查询向量和键向量之间的相似度是随机的,并一定很高。
训练过程
随着训练的进行,模型逐渐调整这些权重矩阵,以便更好地捕获输入序列中词语间的关联性。例如,句子"The cat is sitting on the mat."中,cat和mat之间存在一种空间上的关联,即“猫”坐在“垫子”上。
学习关联性
模型在训练过程中通过以下方式学习到cat和mat之间的关联性:
- 监督信号:模型接收到的数据包含关于cat和mat之间正确关系的监督信号。例如,在翻译任务中,如果cat和mat在目标语言中也有类似的关联,则正确地翻译将强化这种关联。
- 损失函数:损失函数会惩罚模型预测错误的结果。如果模型不能正确识别cat和mat之间的关系,损失将会增加,促使模型更新权重以减少这种错误。
优化过程
通过反向传播和梯度下降等优化算法,模型逐渐调整权重矩阵,使得cat的查询向量和mat的键向量之间的相似度提高,反之亦然。这种调整使得模型能够更准确地捕捉到句子中词语之间的关联性。
注意力机制的效果
当模型训练充分之后,对于句子"The cat is sitting on the mat",模型可能会学习到cat和mat之间的紧密联系。具体来说,当cat作为查询时,它的查询向量与mat的键向量之间的相似度会相对较高,这意味这在计算注意力分数时,mat的位置将被赋予较高的权重。同样地,当mat作为查询时,其查询向量与cat的键向量也会有比较高的相似度。
至于cat是如何学习到和mat的相关性的,那是因为在训练数据集(语料库)中,模型通过观察大量文本样本来学习模式并推断它们之间的联系,关键在于模型如何通过训练数据学习到词语之间的关联性,如果cat经常出现在"on the mat"这样的短语古今,模型就有可能学会cat和mat之间存在某种关系。同时结合上下文信息,在句子中,cat和mat之间的关系是通过它们在句子中的位置以及周围的词汇来表达的,模型通过上下文来推断出词语之间的关系。其次,根据注意力机制,在模型训练过程中模型会逐渐调整权重矩阵,使得cat的查询向量和mat的键向量之间的相似度提高。经过充分训练后,模型能够从训练数据中提取出cat和mat之间的模式,并将这种知识应用于新句子中,即使这些句子在训练数据中从未出现过。
值向量(Value)详解
在transformer模型中,值向量(Value)的作用非常重要,它决定了注意力机制的输出。
值向量的生成
对于给定的输入序列 X = [ x 1 , x 2 , . . . x n ] X=[x_1,x_2,...x_n] X=[x1,x2,...xn],其中 x i x_i xi表示输入序列中的第 i i i个元素(如词嵌入向量或者图像特征向量),值向量 v i v_i vi是通过线性变换(矩阵乘法)得到的:
v i = x i W V v_i=x_iW^V vi=xiWV
其中 W V W^V WV是一个可学习的权重矩阵,它的尺寸通常是输入向量的维度 d m o d e l d_{model} dmodel乘以值向量的维度 d v d_v dv,这个权重矩阵是在模型初始化阶段随机初始化的,并且在整个训练过程中会通过反向传播不断更新,以便更好地捕捉输入序列中的重要信息。
值向量的作用
值向量 v i v_i vi在自注意力机制中的主要作用是作为注意力计算的结果。当计算出注意力权重 α i j \alpha_{ij} αij后,这些权重被用来对值向量 v j v_j vj进行加权求和:
z i = ∑ j = 1 n α i j v j z_i=\sum_{j=1}^n\alpha_{ij}v_j zi=∑j=1nαijvj
其中 z i z_i zi是第 i i i个位置的注意力输出。这一步骤可以理解为对每个位置 i i i,根据其与其他位置 j j j的相似度(由注意力权重 α i j \alpha_{ij} αij表示)来整合其他位置的信息。
模型训练过程中的变化
在模型训练过程中,值向量 v i v_i vi本身不会直接发生变化,但影响其生成的权重矩阵 W V W^V WV会发生变化。随着训练的进行,权重矩阵 W V W^V WV会逐渐调整,使得生成的值向量更适合作为注意力机制的输出。这种调整是通过反向传播算法来完成的,其目的是最小化模型的损失函数。
在训练过程中,权重矩阵 W V W^V WV的更新遵循以下步骤:
- 前向传播:计算预测输出,并与实际标签比较,得到损失值。
- 反向传播:计算损失相对于模型参数(包括 W V W^V WV)的梯度。
- 参数更新:使用优化器(如Adam等)来更新参数,使损失函数逐渐减小。
多头注意力中的值向量
在多头注意力机制中,每个注意力头都会有自己的权重矩阵 W h V W_h^V WhV,用于生成对应的值向量 v i , h v_{i,h} vi,h:
v i , h = x i W h V v_{i,h}=x_iW^V_h vi,h=xiWhV
每个头的 W h V W^V_h WhV都会有所不同,这样可以捕捉输入序列中不同方面的重要信息。多个头的输出会进行拼接,然后通过另一个线性变换 W O W^O WO来生成最终的输出:
z i = C o n c a t ( z i , 1 , z i , 2 , . . . , z i , H ) W O z_i=Concat(z_{i,1},z_{i,2},...,z_{i,H})W^O zi=Concat(zi,1,zi,2,...,zi,H)WO
通过这种方式,Transformer模型能够在处理长序列数据时有效地捕捉到重要的上下文信息。
多头自注意力机制
解码器比编码器多一个网络结构子层,并且是经过修改后的,自注意力机制通过掩盖(masking)来防止当前位置关注后续位置。解码器的自注意层使用一个掩码(mask)来防止解码器在生成当前词的时候看到未来的词,在生成序列的每一步,仅使用之前已经生成的词作为上下文信息。
解码器在每个时间步只能看到它之前的位置,为了防止在序列生层过程中,解码器利用好到未来未知的信息,从而违反自回归模型的因果性质。
自注意力机制通过掩盖(masking)来确保在生成每个词时,只能依赖于已经生成的词,而不能利用到未来词的信息,通过在自注意力计算中加入一个掩码来实现,掩码会将未来未知的权重设置为一个非常小的数值,使得在应用softmax函数时,这些位置上的注意力权重几乎为零,从而不会对当前位置的输出产生影响。
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











