







文章目录
Transformer是一种用于自然语言处理(NLP)和其他序列到序列(Seq2Seq)任务的深度学习模型框架,在2017年由Vaswani等人首次提出。在此之前,RNN结构能够捕获时序信息,但是不能用于并行计算,CNN结构能够并行,但是不能够捕获时序信息。Transformer利用attention代替RNN结构,能够有效地捕捉序列间的长距离依赖关系,还可以实现并行运算,加速模型的计算。
注意力机制
注意力机制是一种处理序列数据时,让模型能够聚焦于输入序列中最重要的部分的技术,这种机制模仿了人类在处理信息时能够集中注意力与某些关键细节的行为。举例来说,假如你现在正在听一场演讲,在听的过程中,你会自然而然地关注某些关键点,比如演讲者提到的一个重要数据或者一个引人深思的观点或者一个印象深刻的故事。这种选择性地聆听并聚焦于某些信息的能力,可以帮助你更好的理解演讲的内容,这就叫做注意力机制。
注意力机制就像是在机器学习模型中的这种能力——它能够让模型在处理输入数据时,关注到其中最重要的部分。在自然语言处理领域,注意力机制被广泛地应用于机器翻译、文本摘要、问答系统等多种任务中。
自注意力机制
自注意力机制之所以被称为“自注意力“, 是因为它允许每个位置的词或符号关注自身的上下文信息,同时也可以关注序列中其他位置的信息。这里的”自“是指每个位置都可以关注自身以及序列中的其他位置,而不仅仅是关注其他位置。从而每个位置上的词都能够更好的理解上下文。
在传统的方法中(例如RNN和LSTM),模型通常只能串行地处理序列中的词,并且难以有效地捕捉长距离依赖关系。相比之下,自注意机制允许模型并行处理序列中所有词,并且通过计算注意力权重来确定哪些词之间存在关联,从而更好地理解输入序列的上下文。
自我关注:在注意力机制中,每个位置上的词都会计算一个与自身关联的注意力权重。这意味着词不仅关注序列中的其他词,而且还关注自身的信息。这种自我关注的能力是自注意力机制的一个关键特性。
相互关注:除了自我关注之外,每个位置上的词还可以关注序列中的其他词。这种相互关注的能力使得模型能够捕捉到输入序列中词与词之间的关系,即使是远距离的依赖关系也能被很好的处理。
上下文相关性:自注意力机制通过计算注意力权重来确定每个词在其上下文中所扮演的角色。这使得模型能够理解词在不同上下文中可能具有的不同含义。
上图为自注意力结构图
自注意力机制基本原理
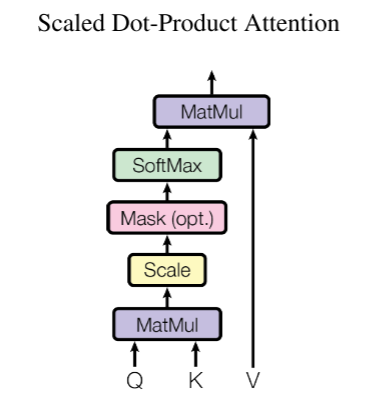
自注意力机制的核心在于计算不同位置上的词之间的重要性和相关性。这个过程设计到了解查询(Query)、键(Key)和值(Value)的三个基本概念。
查询(Query):代表当前词想要关注的信息(我应该关注什么信息)。
键(Key):代表其他词可以关注的信息(我这里有什么可以被关注)。
值(Value):代表了关注后当前词和其他词的信息(关注之后能得到的信息)。
数学公式
假设输入序列 x i x_i xi表示第 i i i个位置的词向量, W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV分别是用于查询、键和值向量的权重矩阵,则自注意计算可表示为:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d K ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_K}})V Attention(Q,K,V)=Softmax(dKQKT)V
其中:
-
Q = x i W Q Q=x_iW_Q Q=xiWQ是序列中第 i i i个位置的词向量×权重矩阵 W Q W_Q WQ,表示查询向量,用于询问“我应该关注什么?”
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











