







Transformer在自然语言处理(NLP)领域取得了重大的成果。它的主流方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调,得益于它的计算效率和可扩展性等优点,它可以训练前所未有的规模,并且随着模型和数据集的增长,仍然没有出现性能饱和的迹象。
基于以上优势,有研究人员考虑把transformer的这种优势迁移到图像中进行模型训练,研究transformer是否适用于计算机视觉领域,于是ViT应运而生。Transformer有效的解决了长距离依赖问题,并且有良好的可扩展性,适用于处理序列化的数据,NLP中的语句刚好就是序列化的数据,但是在计算机视觉中,图像属于二维数据,那么如何在二维数据中应用到transformer呢,针对这个问题,ViT的作者提出一种位置编码策略,将一张图片切分成相同大小的块,然后给每个块进行位置编码成为一个序列,然后再使用transformer进行训练。本篇内容带大家详细了解一下ViT中的位置编码。
位置编码方法
在NLP领域,用于训练的语料库中都是句子,在训练的时候,模型把每个单词都编码成相同的维度(比如说100维),然后使用每个单词编码后的维度来进行训练,但是在计算机视觉领域,图像是有一定的空间结构的,那么又该怎么将它变成一个序列呢?
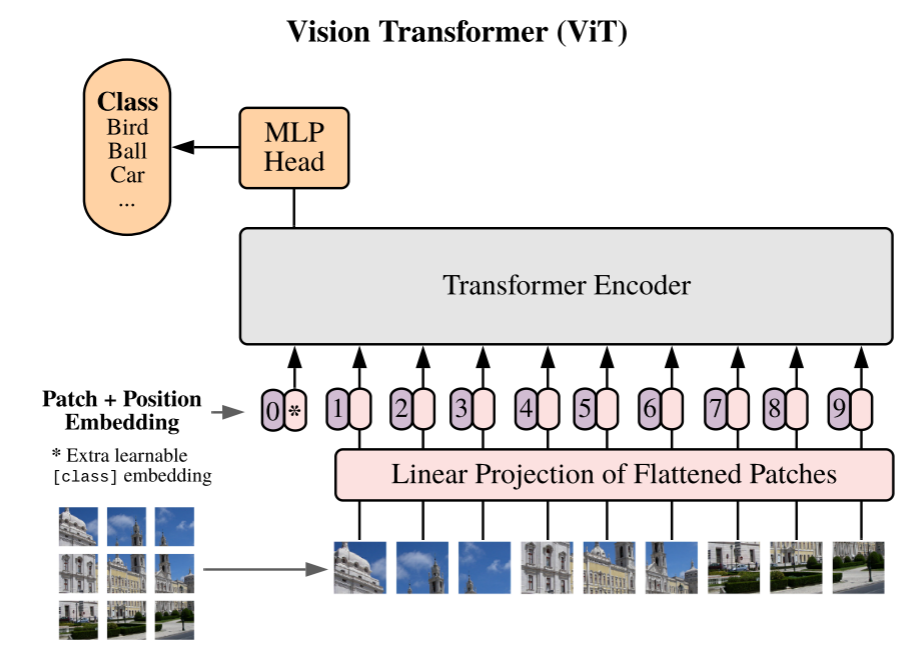
如上图所示,图为ViT的网络结构图。那么ViT都做了哪些工作呢?
图像分割:首先,如上图左下角的图像所示,ViT先将每个完整的图像切分成相同大小的patch,图中就是把一张完整的图片切分成了9等份,然后根据切分后的patch进行位置编码,例如第一行第一列的patch的位置编码为(0,0)第一行第二列的patch的位置编码为(0,1),以此类推,第三行第三列的patch的位置编码为(2,2),这样就把一个完整的图片切分完成了。
形成序列:之后,将切分完成的patch按照顺序平铺形成一个序列(图中右下的序列),然后将形成序列的patch和它们对应的位置编码通过线性投影编码送入模型进行训练。
以上就是ViT的位置编码流程,然后将编码后的数据送入模型进行训练得到预训练模型。之后再根据特定任务选择数据集进行微调。看到这里你是否有一个疑问,那就是我在训练模型的时候用到的图像分辨率会不会和我微调时用到的图像分辨率不同,答案是肯定的。以下是论文中的原话:
The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints),however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image. Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Vision Transformer.
以上片段的意思是ViT可以处理任意序列的长度(直到超出内存限制),然而,在微调的时候,预训练的位置嵌入可能不再有意义。因此,文章根据预训练的位置嵌入在原始图像中的位置,对其进行二维插值操作。分辨率的调整和patch的划分是将二维结构的归纳偏置手动输入ViT的唯一一点。
通俗的解释来说,假如模型在预训练的过程中使用的图像分辨率是224×224,如果按照16×16个像素的大小来划分patch,那么就是224/16=14,也就是每行每列都有14个patch,总共有14×14个patch块,每个patch都有一个对应的位置嵌入向量(比如第一个patch的位置向量为(0,0))。但是在微调的过程中,使用的是384×384的分辨率,如果还是按照16×16个像素来划分patch块的话,那么就是384/16=24,每行每列都有24个patch,总共有24×24=576个patch,相比于之前预训练用的196个patch,多出来了380个patch,根据模型的训练架构,所有的patch都需要有位置编码,所以要进行2D插值处理,将这380个patch根据对应关系映射到那196个patch的位置嵌入,而这些位置嵌入可能不再准确反映patch的新位置,也就变得“不再有意义”。
基于以上变化,文章提出使用二维插值方法来调整预训练位置嵌入,使之适应新的图像尺寸。具体的说,他们会根据patch在原始图像中的位置来进行插值计算,以保持位置信息的连贯性,并确保模型能够正常理解图像中patch间的关系。
二维插值方法
目的
二维插值的主要目的是调整预训练位置嵌入以匹配输入图像的不同尺寸。由于ViT将输入图像划分为固定大小的patch,如果输入图像的尺寸与训练阶段使用的图像尺寸不同,则位置嵌入需要进行相应的调整以保持位置信息的准确性。
方法
原理解释
ViT预训练时通常会使用特定尺寸的图像(假设分辨率为224×224)。例如,一个常见的设置是将图像划分为16×16像素的patch。预训练的位置嵌入是针对这些特定尺寸的补丁进行学习的。当微调时输入图像的尺寸发生变化时(假设输入图像的分辨率尺寸是384×384),patch的数量也会发生变化,导致位置嵌入没办法直接应用。
插值过程
- 定位:首先确定每个新的patch在原始图像中的位置。
- 插值:根据这些新位置,使用最近邻、双线行或双三次插值等方法从预训练的位置嵌入中提取对应的位置信息。这些方法通过估计新位置的值来创建新的嵌入。
最近邻插值
查找最近位置
- 对于每个新的patch位置,找到其在224×224图像(预训练分辨率尺寸)中与其最接近的patch位置。
- 如果新的patch在224×224分辨率图像中的坐标为(12,12),那么我们寻找举例(12,12)最近的patch位置。
复制位置嵌入
- 将找到的最接近位置的patch的位置嵌入到新
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











