







1.前言
上一小结我们了解了动态规划算法对一个已知状态转移概率(环境动力模型)的 MDP 进行策略评估或通过策略迭代或者直接的价值迭代来寻找最优策略和最优价值函数。但在实际的现实问题中,状态的规模是巨大的,而且状态转移概率大多都是未知的,动态规划就不能解决这一类问题了。这里介绍三种学习方式,一种是蒙特卡罗强化学习(Monte-Carlo reinforcement learning),一种是时序差分强化学习(temporal-difference reinforcement learning)和n步时序差分预测(n步TD)。
2.蒙特卡罗强化学习
蒙特卡罗强化学习是指在不清楚 MDP 状态转移概率的情况下,直接从经历完整的状态序列 (episode,也叫幕)来估计状态的真实价值,并认为某状态的价值等于在多个状态序列中以该状态算得到的所有收获的平均。这里的状态序列,我在这个系列的第二部分提到过,就是幕。完整的状态序列 (complete episode)指从某一个状态开始,个体与环境交互直到终止状态,环境给出终止状态的奖励为止。完整的状态序列不要求起始状态一定是某一个特定的状态,但是要求个体最终进入环境认可的某一个终止状态。
我们可以使用蒙特卡罗强化学习来评估一个给定的策略。基于特定策略 π 的一个 Episode信息可以表示为如下的一个序列:
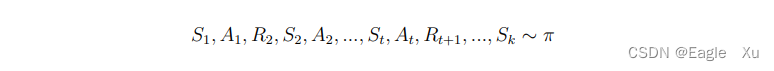
我们首先考虑如何在给定一个策略的情况下用蒙特卡洛方法学习其状态值函数。回想一下,一个状态的价值是从该状态开始的预期回报,及未来的折扣收益累积值的期望。因此,从经验中估计它的一个明显方法是简单地将经过这个状态后观察到的回报进行平均。随着更多的收益被观察到,平均应该收敛到期望值。这一思想是所有蒙特卡洛算法的基础。假设给定在策略π下途径状态s的多幕数据,我们想估计在策略π下状态s的价值函数vπ(s)。在给定的每一幕中,每次状态s的出现都称为对状态是的访问。当然,在同一幕中,状态是也可能被多次访问到。在这种情况下,我们称第一访问为s的首次访问。首次访问型MC算法用s的所有首次访问的回报的平均值估计vπ(s)。而每次访问型算法则使用所有访问回报的平均值。

3.时序差分强化学习
在强化学习的所有思想当中,TD无疑是最核心、最新颖的思想。时序差分学习结合了蒙特卡洛方法和动态规划方法的思想。与前面所说MC一致的是,TD也可以直接从与环境互动的经验中学习策略,而不需要构建关于环境动态特性的模型。与DP一致的是,TD无需等到交互的最终结果(它使用了自举的思想),而可以基于已得到的其他状态的估值来更新当前状态的价值函数。
时序差分强化学习 (temporal-difference reinforcement learning, TD 学习):指从采样得到的不完整的状态序列学习,该方法通过合理的引导(bootstrapping),先估计某状态在该状态序列完整后可能得到的收获,并在此基础上利用前文所属的累进更新平均值的方法得到该状态的价值,再通过不断的采样来持续更新这个价值。
具体地说,在 TD 学习中,算法在估计某一个状态的收获时,用的是离开该状态的即刻奖励Rt+1 与下一时刻状态 St+1 的预估状态价值乘以衰减系数 γ 组成:
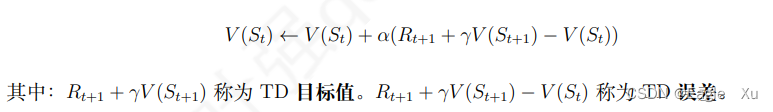
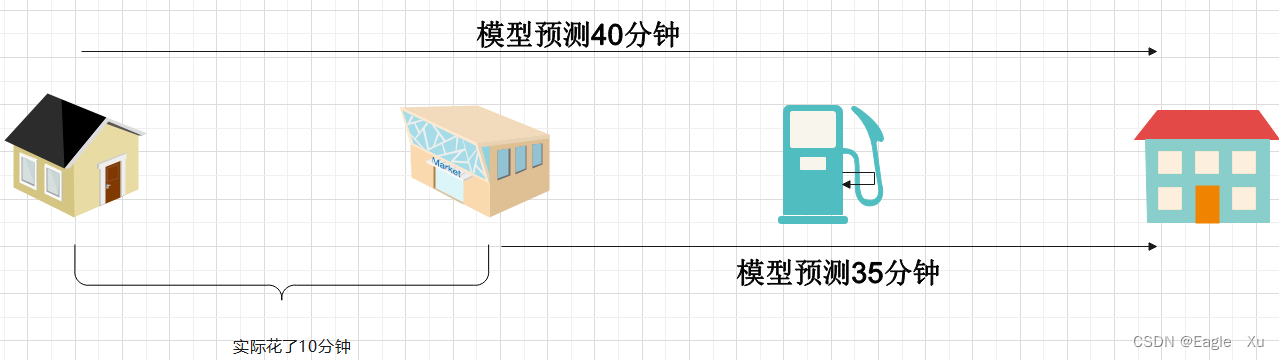
我们举一个简单的例子来理解TD算法,如图3.2所示,小明从家到学校去上学,路上要经过一个超市,然后是加油站,最后到达学校。在出发前,小明用模型预估到学校需要40分钟,但过了10分钟它到达了超市,它又用模型预估了一下要35分钟,显然,如果用这个初始模型来估计,这个便不准确,现实中的10分钟是实打实的,我们更相信事实。我们应该让模型在这一阶段的估计接近10分钟。图3.1中的,TD目标值,在这个例子中就是10+γ35,误差为10+γ35-40;我们通过这个为损失函数来调整模型参数。
下面是伪代码:

4.n步时序差分预测
单独的MC方法或者TD方法都不会总是最好的方法。n步时序差分方法是这两种方法更一般的推广。MC方法和TD方法是这个框架中两种极端的特例,中间方法的性能一般要比这两种极端方法好。
如图4.1所示,大白圈表示状态S,小黑点表示动作A。n-步预测指从状态序列的当前状态 (St) 开始往序列终止状态方向观察至状态 St+n−1,使用这 n 个状态产生的即时奖励(Rt+1, Rt+2, …, Rt+n) 以及状态 St+n 的预估价值来计算当前第状态St 的价值。图中TD(1-步)也就是TD(0).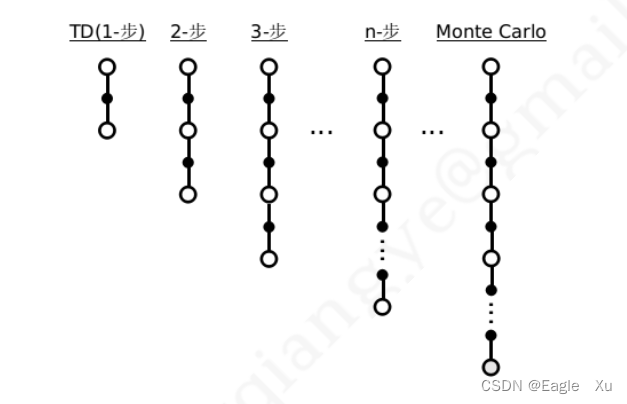


图4.4为n步时序差分算法的伪代码。

5.总结
从已知模型的、基于全宽度采样的动态规划学习转至模型未知的、基于采样的蒙特卡洛或时序差分学习进行控制是朝着高效解决中等规模实际问题的一个突破,而n步TD是两者的一个折中,是着两种方法更一般的推广。TD 学习在知道结果之前就可以学习,也可以在没有结果时学习,还可以在持续进行的环境中学习,而 MC 学习则要等到最后结果才能学习。TD 学习在更新状态价值时使用的是 TD 目标值,即基于即时奖励和下一状态的预估价值来替代当前状态在状态序列结束时可能得到的收获,它是当前状态价值的有偏估计,而 MC 学习则使用实际的收获来更新状态价值,是某一策略下状态价值的无偏估计。TD 学习存在偏倚 (bias)的原因是在于其更新价值时使用的也是后续状态预估的价值,如果能使用后续状态基于某策略的真实 TD 目标值 (true TD target) 来更新当前状态价值的话,那么此时的 TD 学习得到的价值也是实际价值的无偏估计。虽然绝大多数情况下 TD 学习得到的价值是有偏估计的,但是其方差 (Variance) 却较 MC 学习得到的方差要低,且对初始值敏感,通常比 MC 学习更加高效,这也主要得益于 TD 学习价值更新灵活,对初始状态价值的依赖较大。
6.参考资料
main-RL-QiangYe.pdf
Reinforcement Learning:An Introduction Second Edition

















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









