







 本文详细解析了AlphaGo如何结合深度神经网络、策略网络、价值网络和蒙特卡洛树搜索算法在围棋比赛中取得突破,展示了人工智能在复杂游戏中的强大能力。
本文详细解析了AlphaGo如何结合深度神经网络、策略网络、价值网络和蒙特卡洛树搜索算法在围棋比赛中取得突破,展示了人工智能在复杂游戏中的强大能力。
1.前言
什么是AlphaGo?从名字上来看,alpha是α的读音,有一点编号的意味在里面。Go在英语当中就是围棋的意思,说明这玩意和围棋有关。这确实和围棋有关。AlphaGo是由谷歌旗下DeepMind公司戴密斯·哈萨比斯(Demis Hassabis)领衔团队开发的第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人。2016年3月,AlphaGo以4:1的比分打败了围棋世界冠军、职业九段棋手李世石。2017年5月在中国乌镇围棋峰会上又以3:0的比分打败世界排名第一的世界围棋冠军柯洁。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平。
我们知道围棋游戏因其巨大的搜索空间和评估棋局位置和动作的难度,长期以来被认为是人工智能经典游戏中最具挑战性的游戏。围棋的搜索空间巨大,复杂度为361!,大概是10^250 次方,比人类可观测宇宙的原子数量还多。AlphaGo居然做到了。为什么AlphaGo会如此之强?我们一起来看看。
AlphaGo出自于2016 年 1 月 28 日,Deepmind 公司在 Nature 杂志发表的”Mastering the game of Go with deep neural networks and tree search”这篇论文。 AlphaGo用大量的数据训练了几个网络,一个策略卷积网络Pσ,输出的是361个的一个概率分布。为了在MCTS过程的simulation中走子的速度更快,训练了一个Pπ策略网络,虽然加快了选择速度,但是准确度确有所下降。然后用Pσ 作为初始化,用强化学习训练的训练方法,通过梯度下降来更新参数,训练出了Pρ策略网络。再通过Pρ 进行自我博弈,生成大量的样本数据来训练价值网络Vθ。网络训练好后,在对战过程中,AlphaGo再根据这些策略网络和MCTS来进行动作的选取。
AlphaGo与人下棋之前要先经过不断的训练,它便不是一下就变很厉害的。我们先来看看整体的训练步骤是怎么样的,然后再分开来开具体的策略网络。

2.策略卷积网络Pσ
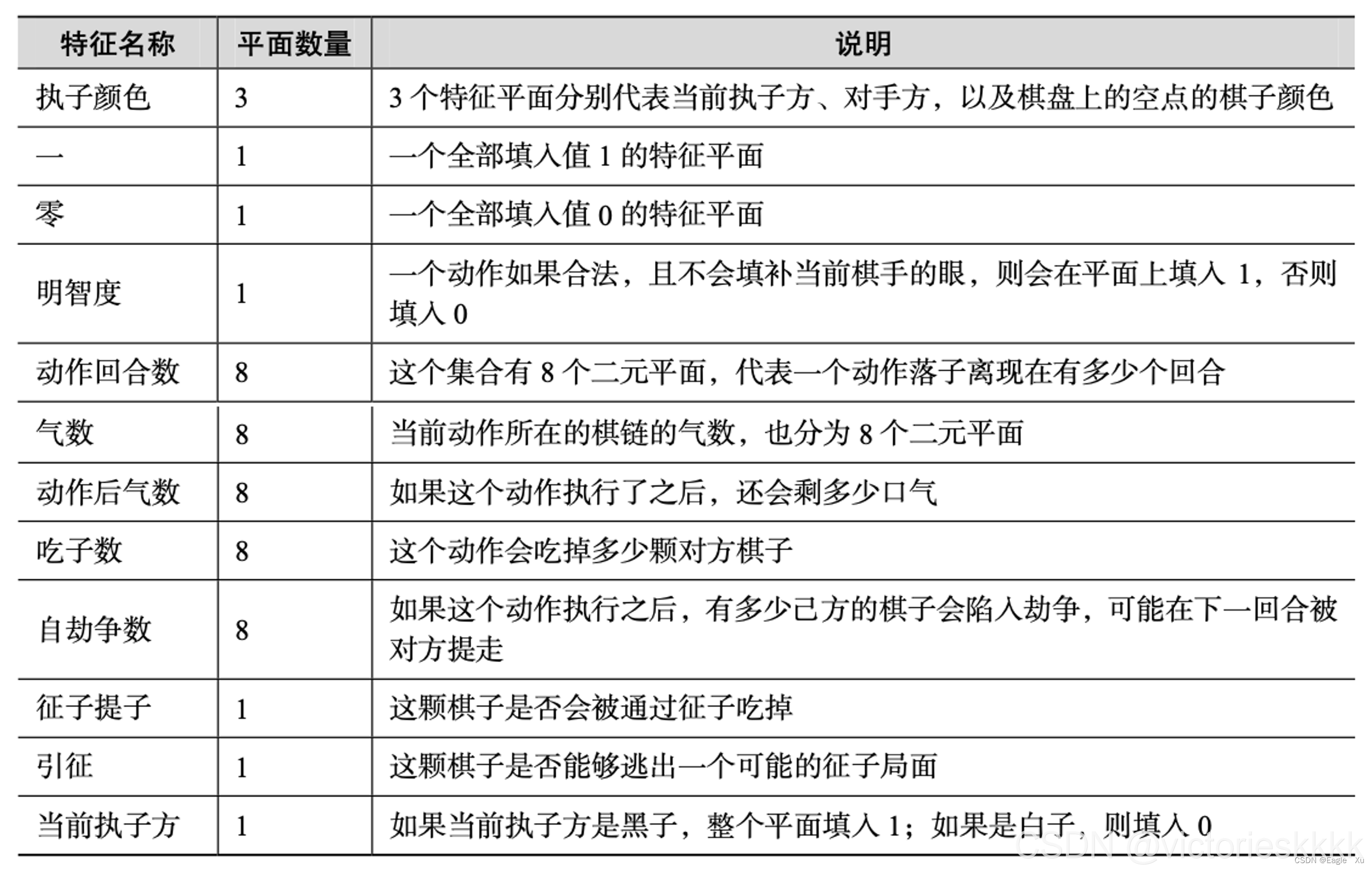
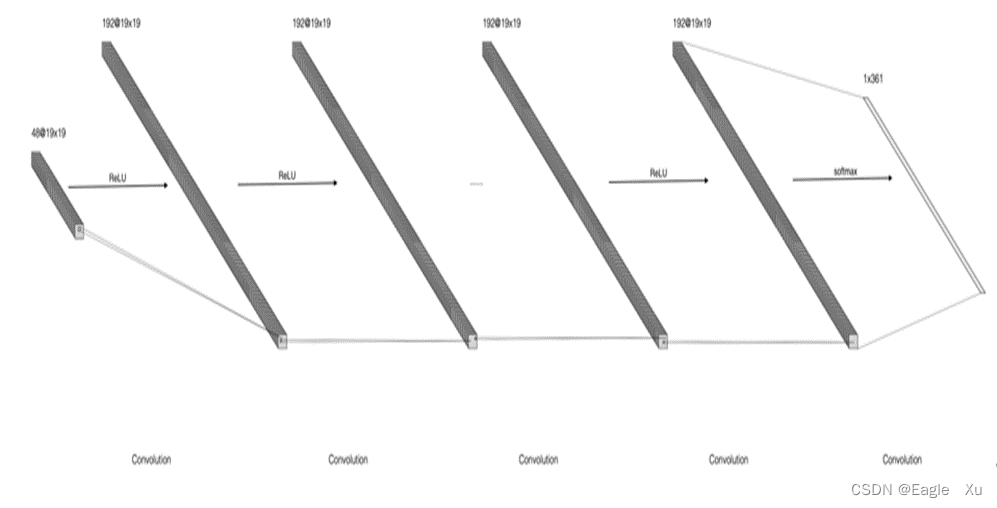
首先我们得知道Pσ神经网络是用来干什么用的?我们才能更好的去理解这个网络。Pσ策略神经网络是用来观察棋局然后决策落子的。围棋的棋盘由19×19的网格组成,AlphaGo所采用的棋盘编码器为 19×19×49 的特征张量,其中前48个平面用于策略网络的训练,最后一个平面用于价值网络的训练。前48个平面包含11种概念,其更多地利用了围棋专有的定式,例如它在特征集合中引入了征子和引征的概念。最后一个平面用来表示当前执子方。





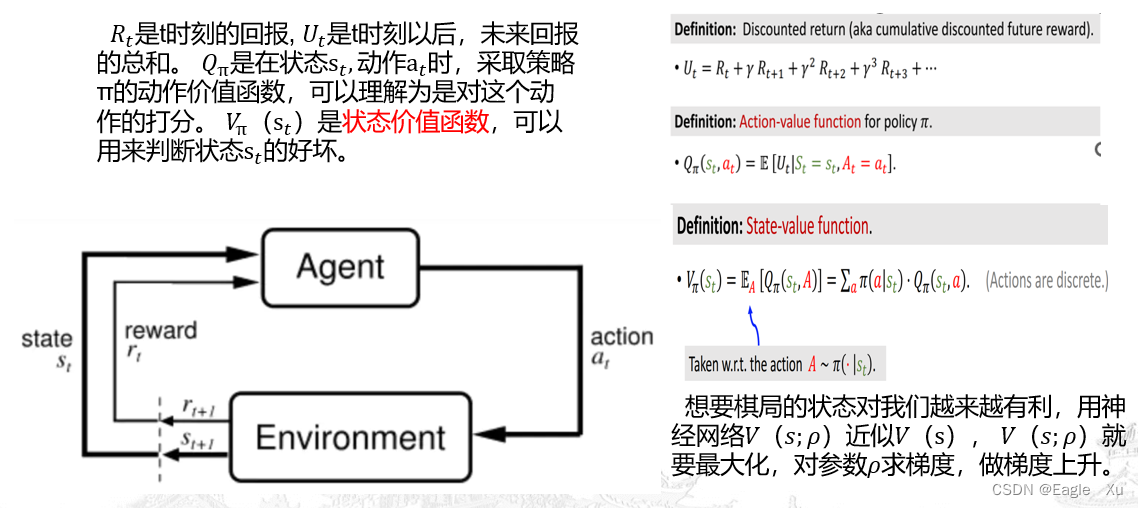
上图这个公式来自论文当中,是Pρ的策略梯度更新公式。如果你没学过强化学习的基础知识,这里就很难看懂了。下面介绍一点点强化学习的基础知识。如下图所示,agent与环境不断的交互来学习。
下面我们来推理一下上面,我们提到的梯度公式怎么来的。


以上推理结束。理解这个公式是怎么来的,对于这个强化学习的训练过程很有帮助。
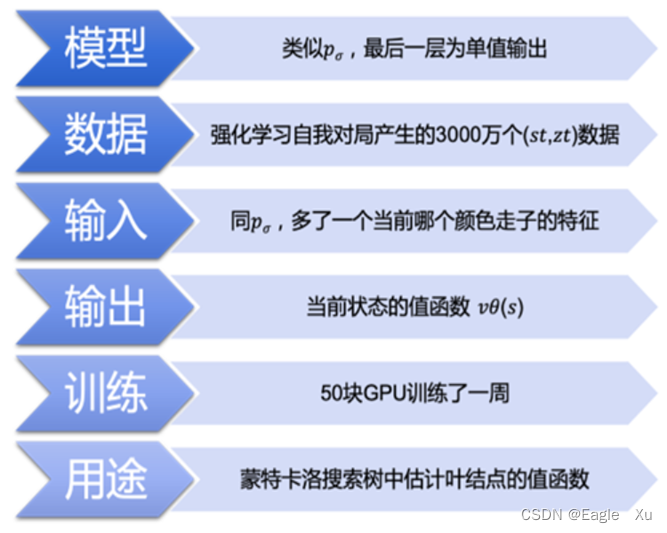
5.价值网络Vθ
这个网络的训练就比较简单了。监督学习的训练。用于评估棋盘状态的价值。会在也是在MCTS过程中用到。
6.蒙特卡洛搜索(MCTS)
到目前为止我们已经训练好了3个神经网络。卷积神经网络Pσ,线性神经网络Pπ,以及价值神经网络Vθ。值得注意的是Pρ神经网络不用在MCTS的过程当中,它主要是用于生成训练神经网络Vθ的数据。这三个神经网络是先训练好的,便不是在比赛的过程中训练的。在真正的比赛过程中,apha的搜索选取依赖的其实是MCTS,这三个网络被用到MCTS搜索当中。AlphaGo其实用到的是APV-MCTS,它依旧有selection,expansion,额evaluation,backup四个步骤。下面我将介绍这四个步骤,看看alphaGo在下棋的过程中具体做了什么。
1.selection
APV-MCTS搜索树中的每条连边(s,a)都包含三个状态:决策收益Q(s,a),访问次数N(s,a),和一个先验概率P(s,a)。这三个状态共同决定了对一个节点下行为的选择。依据的公式如下:
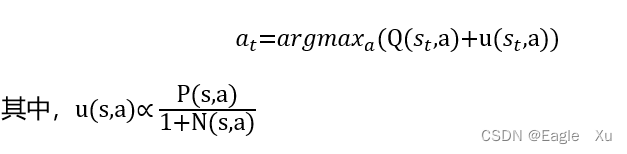
3.Evaluation(也叫rollout过程)
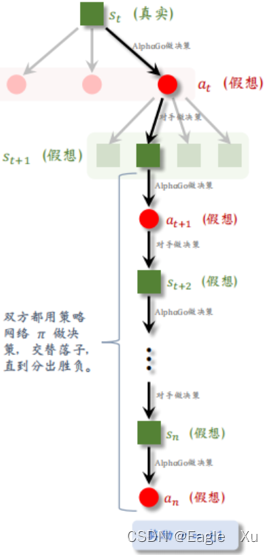
如上图所示,alphaGo看见st+1后,把st+1输入Pπ网络(注意,这里是pπ网络,我们训练的第二个神经网络),得到一个动作a,棋局会变成另一个状态,继续把这个状态输入pπ,又得到一个动作a,这样一直到游戏结束,如果赢为1,输为-1。
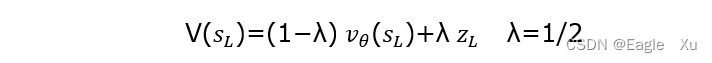
上面这个公式是用来计算节点的V值的,上面的例子当中右边动作a有st+1有四个状态。Vθ(SL)是我们价值网络的输出。ZL是r值,赢就是1,输就是-1.需要注意的是,这里的V值只是这一轮模拟的一个记录。如下图所示:
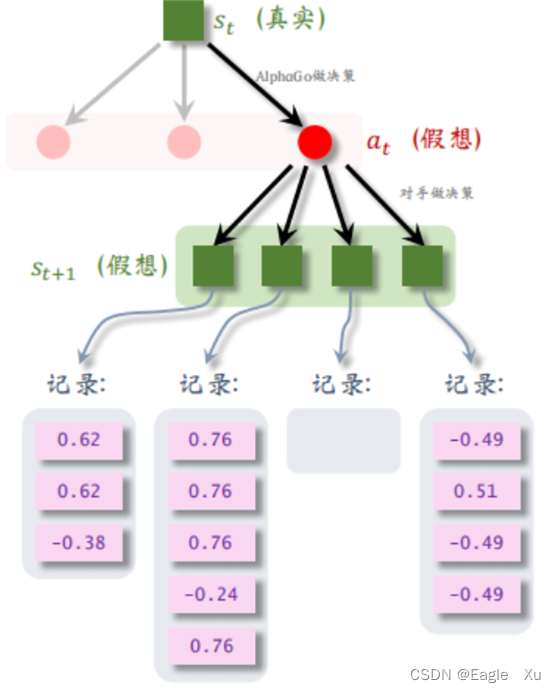
每一个状态s(t+1) 下面都有多条记录。每条记录就是一个V( st+1) 。
在AphaGO的模式过程中,这个过程进行了1600次模拟,为了方便理解过程,上图中,只是画出了最右边动作的图,事实上,随着模拟次数的增加,每个动作都有可能被选中,只是那些更好的动作,被选中的次数会更多。模拟结束后。alphago才会在真实世界做出一个动作。
backup
更新这一轮模拟中所有范围到的路径的状态。上面的例子中树的节点比较少,当层数变多时,更容易理解下面的公式。

每模拟一次,N(s,a)就增加一次,Q(s,a)也重新更新一次。
2.expansion
expansion的过程在大多的步骤顺序上,都是第二步,但是我觉得放在最后一步或许更加的能理解到底什么是expansion.在根节点的时候,我们会进行一次expansion。所谓的expansion就是用pσ计算出叶子节点上每个行为的概率,并作为先验概率P(sL,a)存储下来,在rollout过程中是没有用到expansion的。在AlphaGo中只有对某条边的访问次数超过某个阈值时,才会进行expansion,而这个阈值是动态调整的。
7.总结
AlphaGo首次将神经网络深度学习,强化学习,和MCTS用于围棋,并且取得了很大的成就。尽管AlphaGo成绩优异,但是由于AlphaGo的强大依靠了大量的专家数据和强大的计算资源。在是否智能这上面AlphaGo还是备受争议。下一节介绍AlphaGo Zero,它的升级版, AlphaGo Zero没有借鉴人类的任何经验,就通过纯粹的强化学习,从0在很短的时间内就达到了很高的棋力水平,真的很让人期待!!!

















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









