







(一)AlphaGo Zero
1.前言
上一节我们介绍了AlphaGo,这一节我们介绍它的一个升级版本AlphaGo Zero,Zero在英语当中是0的意思,这里想强调的是它不需要专家数据。 它更是以100 - 0战胜了AlphaGo。AlphaGo Zero论文下载地址:Mastering the game of Go without human Knowledge

2.输入特征
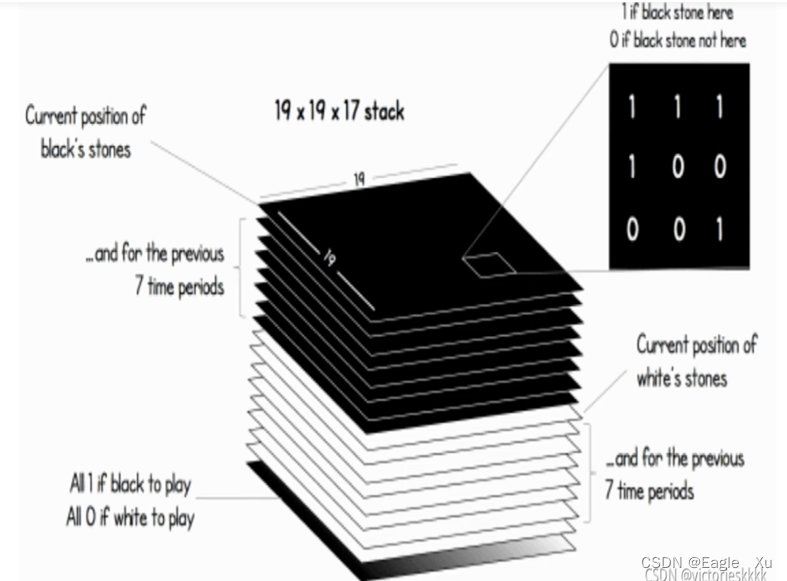
AlphaGo Zero 的输入特征向量和AlphaGo的输入19×19×48不同,如下图所示,是一个
19×19×17的一个向量矩阵。做了极大的简化。这里的特征设计便没有涉及围棋的知识,比如劫数,气等这些概念。一共有17个特征面,一个面表示当前的棋局情况,分别用7个面表示白旗和黑旗的前7步的位置。就还剩下两个面了。如过某个面全是1,轮到黑旗下,另一个面全是0,轮到白旗下。
3.神经网络fθ(s)
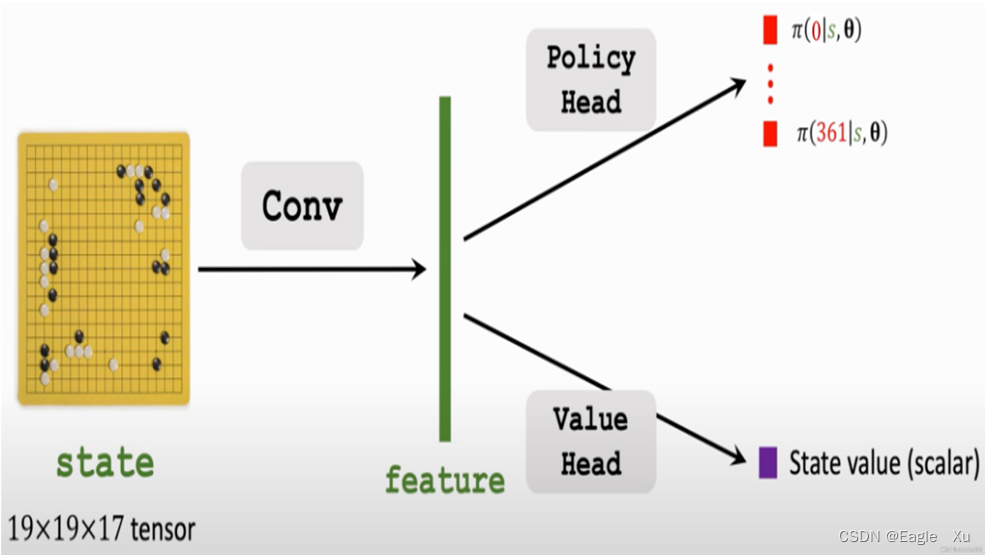
相比与AphaGo的要训练多个神经网络不同,AlphaGo Zero只需要训练fθ(s)这个神经网络。如下图所示:
import torch
from torch import nn
from torch.nn import functional as F
class Residual(nn.Module): #设计残差块
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, # 输出(num_channels,x,y)不变
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
class AphagoZero(nn.Module):
def __init__(self, game, args):
self.board_x, self.board_y = game.getBoardSize() # 获取游戏的行和列
self.action_size = game.getActionSize() # 获得最大动作空间
self.args = args # 输入参数
super(AphagoZero, self).__init__()
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block: # i=0且不是第一个blolk
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2)) # 步长为2
else:
blk.append(Residual(num_channels, num_channels)) # 步长为1
return blk
b1 = nn.Sequential(nn.Conv2d(17, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256), nn.ReLU())
b2 = nn.Sequential(*resnet_block(256, 256, 19, first_block=True))
b3=nn.Sequential(nn.Conv2d(256,2,kernel_size=1,stride=1),
nn.BatchNorm2d(2),nn.ReLU(),nn.Flatten(),nn.Linear(722,362))
b4=nn.Sequential(nn.Conv2d(256,1,kernel_size=1,stride=1),
nn.BatchNorm2d(1),nn.ReLU(),nn.Flatten(),nn.Linear(361,256),nn.ReLU(),nn.Linear(256,1),nn.Tanh())
net = nn.Sequential(b1,b2)
def forward(self,x):
x=self.net(x)
return self.b3(x),self.b4(x)
X = torch.rand(size=(1, 17, 19, 19))
natrual=AphagoZero()
m,n=natrual(X)
print(m.shape,n.shape)
该神经网络将政策网络和价值网络的作用结合到一个单一的架构中。如上图所示,fθ(s)输出分为了两部分,一部分输出是361个位置的一个概率值,是一个向量。另一部分是这个状态的一个值,是一个标量。下面我们来看怎么训练fθ(s)。
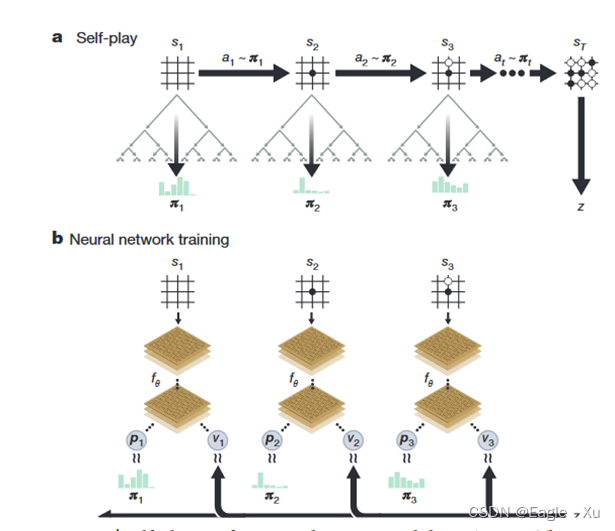
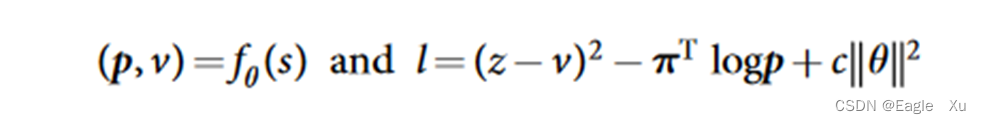
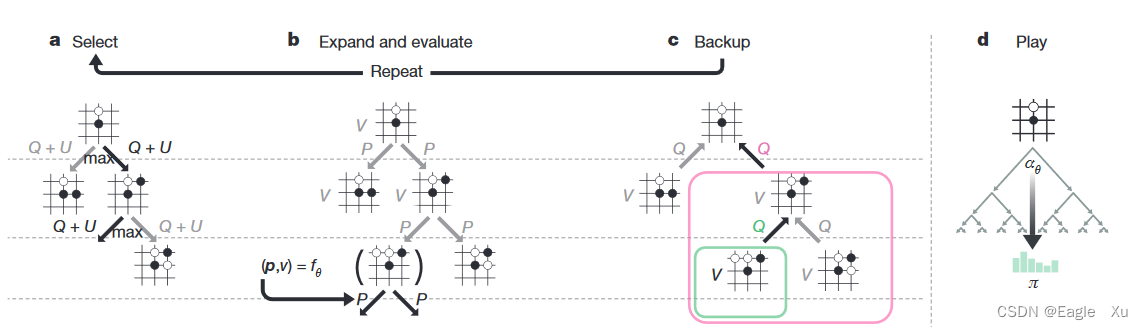
4.AlphaGo Zero的MCTS
AlphaGo Zero中的MCTS和AlphaGo中的MCTS有些不同的地方。主要是下图中的b部分和d部分。b部分当中没有rollout这个过程,它的v值直接代替了alphaGo中v值和z值的比例和。d的这部分,主要就是为了把总1600次的访问节点归一化成一个概率分布。
class MCTS():
"""
This class handles the MCTS tree.
"""
def __init__(self, game, nnet, args):
self.game = game
self.nnet = nnet
self.args = args
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited 访问边的次数
self.Ns = {} # stores #times board s was visited 状态被访问的次数
self.Ps = {} # stores initial policy (returned by neural net) 储存先验概率
self.Es = {} # stores game.getGameEnded ended for board s。如果游戏没结束存储0,结束player赢为1,输为-1
self.Vs = {} # stores game.getValidMoves for board s
def getActionProb(self, canonicalBoard, temp=1):
"""
This function performs numMCTSSims simulations of MCTS starting from
canonicalBoard.
Returns:返回MCTS N次模拟后的分布概率
probs: a policy vector where the probability of the ith action is
proportional to Nsa[(s,a)]**(1./temp)
"""
for i in range(self.args.numMCTSSims): # 模拟次数
self.search(canonicalBoard)
s = self.game.stringRepresentation(canonicalBoard) # 改变数据类型
counts = [self.Nsa[(s, a)] if (s, a) in self.Nsa else 0 for a in range(self.game.getActionSize())]
if temp == 0:
bestAs = np.array(np.argwhere(counts == np.max(counts))).flatten() # 返回选择次数最多的索引,可能是一个数组
bestA = np.random.choice(bestAs) # 如果有多个随机选取一个
probs = [0] * len(counts)
probs[bestA] = 1 #概率唯一
return probs
counts = [x ** (1. / temp) for x in counts]
counts_sum = float(sum(counts))
probs = [x / counts_sum for x in counts]
return probs
def search(self, canonicalBoard):
"""
This function performs one iteration of MCTS. It is recursively called
till a leaf node is found. The action chosen at each node is one that
has the maximum upper confidence bound as in the paper.
Once a leaf node is found, the neural network is called to return an
initial policy P and a value v for the state. This value is propagated
up the search path. In case the leaf node is a terminal state, the
outcome is propagated up the search path. The values of Ns, Nsa, Qsa are
updated.
NOTE: the return values are the negative of the value of the current
state. This is done since v is in [-1,1] and if v is the value of a
state for the current player, then its value is -v for the other player.
Returns:
v: the negative of the value of the current canonicalBoard
"""
s = self.game.stringRepresentation(canonicalBoard) # 把状态快速转换成字符串格式
if s not in self.Es: # 此状态是否被访问过
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0: # 此状态是终节点,游戏结束
# terminal node
return -self.Es[s]
if s not in self.Ps: # 没计算过先验概率
# leaf node
self.Ps[s], v = self.nnet.predict(canonicalBoard) # 神经网络预测,返回动作分布概率和v值
valids = self.game.getValidMoves(canonicalBoard, 1) # 当前玩家在当前状态做动作是否有效移动,返回动作数量大小的二进制向量
self.Ps[s] = self.Ps[s] * valids # masking invalid moves动作无效的为0.
sum_Ps_s = np.sum(self.Ps[s]) # 把所有有效移动的概率加起来
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # renormalize 标准化
else:
# if all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
self.Vs[s] = valids # 保存这个状态所有合法移动信息
self.Ns[s] = 0 # 这是一个新状态,被访问次数先设置为0
return -v
# 计算过先验概率
valids = self.Vs[s] # 查看此状态的所有合法走子
cur_best = -float('inf')
best_act = -1
# pick the action with the highest upper confidence bound 选择置信上限最高的动作
for a in range(self.game.getActionSize()): # 遍历所有的动作
if valids[a]: # 如果动作合法
if (s, a) in self.Qsa: # 如果(s,a)在Qsa中,之前访问过
u = self.Qsa[(s, a)] + self.args.cpuct * self.Ps[s][a] * math.sqrt(self.Ns[s]) / (
1 + self.Nsa[(s, a)])
else:
u = self.args.cpuct * self.Ps[s][a] * math.sqrt(self.Ns[s] + EPS) # Q = 0 ,N=0为什么要加一个很小的值
if u > cur_best:
cur_best = u # 找到最大的U
best_act = a # 最大u值动作
a = best_act # 获取当前状态u值最大的动作
next_s, next_player = self.game.getNextState(canonicalBoard, 1, a) # 获取下一个状态,返回下一个状态和该下的player
next_s = self.game.getCanonicalForm(next_s, next_player) # 角色转换
v = self.search(next_s) # 递归调用
if (s, a) in self.Qsa:
self.Qsa[(s, a)] = (self.Nsa[(s, a)] * self.Qsa[(s, a)] + v) / (self.Nsa[(s, a)] + 1)
self.Nsa[(s, a)] += 1
else: # 第一次访问到这条边
self.Qsa[(s, a)] = v
self.Nsa[(s, a)] = 1
self.Ns[s] += 1
return -v
(二)AlphaZero
从名字上来看,去掉了Go。AlphaZero是DeepMind 2020推出的AlphaGo Zero的通用版本,让AlphaGo Zero不仅仅可以下围棋,还可以下其他比如象棋,西洋棋等棋类。

(三)总结
在棋类领域AlphaZero已经取得了超越人类的成绩,但这并不代表就已经是顶点了。而且AlphaZero只适用于基于规则的,完美信息博弈环境。或许它的下一版本MuZero能给我们想要的答案。

















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









