






参考:warmup学习率
深度学习中的固定学习率衰减策略总结
在深度学习和其它一些循环迭代算法中,学习率都非常重要。在效率上,
它几乎是与算力同等重要的因素;在效果上,它也决定着模型的准确率。如果设置太小,则收敛缓慢,也有可能收敛到局部最优解;设置太大又导致上下摆动,甚至无法收敛。
设定学习率
下面总结了设置学习率的一些方法:
理论上,如果将学习率调大10倍,现在10次训练就可以达成之前100次的训练效果。
一般使用工具默认的学习率,如果收敛太慢,比如训练了十几个小时,在训练集和验证集上仍在收敛,则可尝试将学习率加大几倍,不要一下调成太大。
如果误差波动过大,无法收敛,则可考虑减小学习率,以便微调模型。
在测试阶段建议使用较大的学习率,在短时间内测算过拟合位置,尤其好用。
在预训练模型的基础上fine-tune模型时,一般使用较小的学习率;反之,如果直接训练,则使用较大的学习率。
对于不同层可使用不同学习率,比如可对新添加的层使用较大的学习率,或者“冻住”某些层。
下图展示了不同学习率的误差变化曲线。
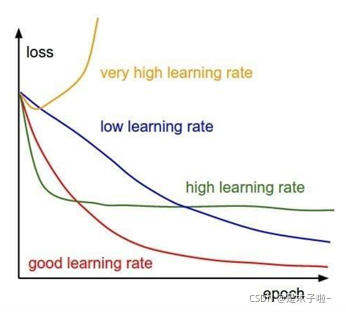
图片来自网络
手动调节学习率
Pytorch提供在迭代过程中修改学习率的方法。最简单的方法是手动修改学习率的值。优化器optimizer通过param_group提供对不同层使用不同的优化方法,其中每组参数保存了各自的学习率、动量等,如果只设置了一种优化方法,修改其第0组的lr即可,例如设置学习率加倍: optimizer.param_groups[0][‘lr’] *=2 在使用工具调整学习率的过程中,也可通过该值检测学习率的变化:
print(optimizer.state_dict()[‘param_groups’][0][‘lr’])
使用库函数调节
更为简便的方法是使用torch.optim.lr_scheduler工具,它支持三种调整方法:
有序调整
按一定规则调整,比如使用余弦退火(CosineAnnealing),指数衰减(Exponential),或者步长(Step)等事先定制的规则调整学习率。
自适应调整
通过监测某个指标的变化情况(loss、accuracy),当指标不再变好时,调整学习率 (ReduceLROnPlateau);
自定义调整
使用自定义的lambda函数调整学习率(LambdaLR)
示例
下面示例最简单的调整方法:每十次迭代,学习率减半
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
%matplotlib inline
# 构建一个简单的网络
class simpleNet(nn.Module):
def __init__(self, in_dim, n_hidden, out_dim):
super(simpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden)
self.layer2 = nn.Linear(n_hidden, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
model = simpleNet(5, 10, 8)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 学习率初值0.1
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) # 每十次迭代,学习率减半
arr = [] # 用于做图
for i in range(1,100):
scheduler.step() # 学习率迭代次数+1
arr.append(optimizer.state_dict()['param_groups'][0]['lr'])
#arr.append(scheduler.get_lr()) # 与上一句功能相同
plt.grid()
plt.plot(arr)
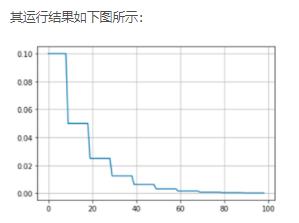














 7703
7703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









