







0 问题引入
举一个最简单的例子,在二维坐标系中存在散放的红豆和绿豆。
提出两个问题:
第一,怎么找到一条直线将其分开?
第二,怎么保证这条直线尽量准确,不会出现很多豆子分错的情况?
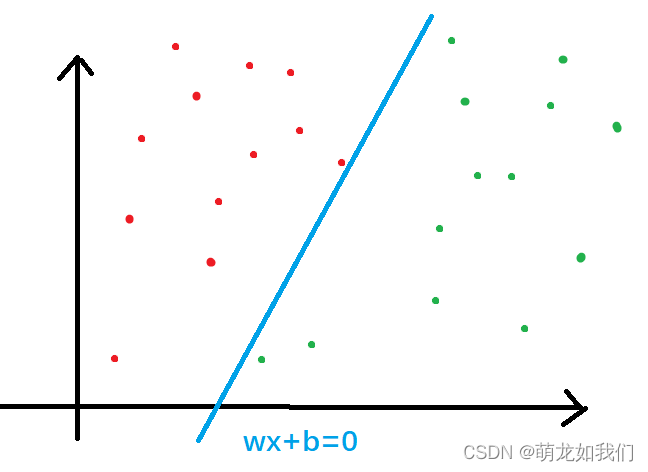
感知机就是解决这类问题的一种方法,它是二类分类的线性分类模型(分离超平面是线性的),旨在求出线性划分的分离超平面。
1.感知机模型
1.1 问题定义
代表输入向量,
代表输出结果,因为是二分类问题,故
。
- 感知机模型(输入空间到输入空间的函数关系):
其中w为权值,b为偏置,表示w和x的内积,sign为符号函数,即
关于超平面S: 超平面是指n维线性空间中维度为n-1的子空间。它可以把线性空间分割成不相交的两部分。比如二维空间中,一条直线是一维的,它把平面分成了两块;三维空间中,一个平面是二维的,它把空间分成了两块。当
,
;当
,
.
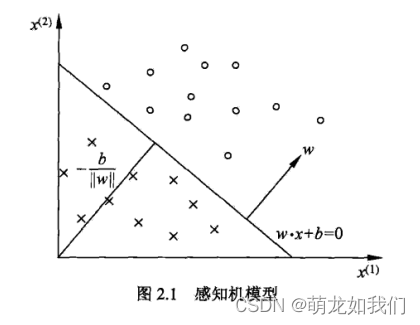
- 感知机学习,就是用训练数据集
根据某种策略得到求得参数w,b,即求得感知机模型
.
2.感知机学习策略(定义损失函数)
与用最小二乘法拟合回归直线类似,它的损失函数为所有点到直线的距离和,而感知机不是要拟合直线,它是要找到一个超平面可以将正负类样本点刚好分布在该超平面的两侧。对于最小二乘法来说,我们找到的直线最好能过所有点,不在直线上的点就会产生“损失”,计算损失的方式是计算不在直线上的点到直线的距离;同样地对于感知机来说,我们需要找到分类错误的点产生的“损失”。

定义分类错误的点产生的损失是计算这些点和超平面S之间的距离,则输入空间中任一点到超平面S之间的距离为:
其中||w||为w的
范数。
这点可以联想一点
到Ax+By+C=0的距离d,
,高维空间也是如此。
对于误分类点来说,
和
是异号的,则误分类点到超平面S的距离是
进而可以求出所有误分类点到超平面S的距离为,M为误差点集合:
此时可以不考虑,看可得到损失函数:
因为误差的出现是因为存在误分类点,但存在超平面时,就不存在误分类点。目的不是找到最小的误差,只需要沿着误差减少的方向进行更新参数。
接下来就是求极小化损失函数:
接下来介绍感知机的两种参数更新方式:原始形式、对偶形式
2.1 感知机学习算法的原始形式
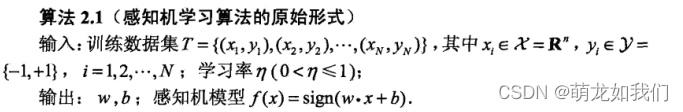
(1)选择初始值w0,b0确定一个超平面;
(2) 在训练集中选取数据;
(3) 如果,用随机梯度下降法(SGD)更新参数,极小化目标函数.
损失函数L(w,b)的梯度:
更新参数:
(4) 执行(2),直至训练集中没有误分类点
2.2 感知机学习算法的对偶形式

对偶形式相比原始形式的参数更新方式不同,对偶形式是累加式的。w,b是在不断更新的,设更新次数为n,
,则

(1);
(2) 在训练集中选取数据;
(3) 如果 时,更新参数。
更新时,则
更新参数:
(4) 执行(2),直至训练集中没有误分类点















 3163
3163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









