







InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617)
目录
3.2 整流流(Rectified Flow)和回流(Reflow)
0. 摘要
扩散模型以其卓越的质量和创造力彻底改变了文本到图像的生成。 然而,众所周知,其多步采样过程很慢,通常需要数十个推理步骤才能获得满意的结果。 之前通过蒸馏提高采样速度并降低计算成本的尝试未能成功实现功能性一步模型。 在本文中,我们探索了一种名为 “整流流(Rectified Flow)” [1, 2] 的最新方法,迄今为止,该方法仅应用于小型数据集。 整流流的核心在于其回流(reflow)过程,它拉直概率流的轨迹,细化噪声和图像之间的耦合,并促进学生模型的蒸馏过程。 我们提出了一种新颖的文本条件管道,将稳定扩散(Stable Diffusion,SD)转变为超快的一步模型,其中我们发现回流在改善噪声和图像之间的分配方面发挥着关键作用。 据我们所知,利用我们的新管道,我们创建了第一个基于单步扩散的文本到图像生成器,具有 SD 级图像质量,在 MS COCO 2017-5k 上实现了 23.3 的 FID(Fréchet 起始距离),大大超越了之前最先进的技术——渐进式蒸馏 [3](FID 中为 37.2 → 23.3)。 通过利用具有 1.7B 参数的扩展网络,我们进一步将 FID 提高到 22.4。 我们将我们的一步模型称为 InstaFlow。 在 MS COCO 2014-30k 上,InstaFlow 在短短 0.09 秒内产生了 13.1 的 FID,这是 ≤ 0.1 秒范围内的最佳结果,优于最近的 StyleGAN-T [4](0.1 秒内为 13.9)。 值得注意的是,InstaFlow 的训练仅花费 199 个 A100 GPU 天。 项目页面:https://github.com/gnobitab/InstaFlow。
1. 简介

现代文本到图像(text-to-image,T2I)生成模型,例如 DALL-E [7, 8]、Imagen [9, 10]、Stable Diffusion [5]、StyleGAN-T [4] 和 GigaGAN [11],展示了根据文本描述合成逼真、艺术和详细图像的卓越能力。 这些进步是通过大规模数据集 [12] 和模型 [5,7,11] 的帮助实现的。
然而,尽管它们的生成质量令人印象深刻,但这些模型通常会受到过多的推理时间和计算消耗的影响 [5,7,8,9,10]。 这可以归因于这样一个事实:大多数模型要么是自回归模型 [13, 14, 15],要么是扩散模型 [16, 17]。 例如,稳定扩散,即使使用最先进的采样器 [18,19,20],通常也需要 20 多个步骤才能生成可接受的图像。 因此,先前的工作 [3,21,22] 提出对这些模型采用知识蒸馏来减少所需的采样步骤并加速其推理。 不幸的是,这些方法在小步机制中举步维艰。 特别是,一步大规模扩散模型尚未开发出来。 现有的一步式大规模 T2I 生成模型是 StyleGAN-T [4] 和 GigaGAN [11],它们依赖于生成对抗训练,需要仔细调整生成器和判别器。
在本文中,我们提出了一种源自开源稳定扩散(SD)的新颖的一步生成模型。 我们观察到,直接蒸馏 SD 会导致彻底失败。 主要问题源于噪声和图像的次优耦合,这极大地阻碍了蒸馏过程。 为了应对这一挑战,我们利用整流流 [1, 2],这是利用概率流的生成模型的最新进展 [17, 23, 24]。 在整流流中,采用了一种称为回流的独特程序。 回流逐渐拉直概率流的轨迹,从而降低噪声分布和图像分布之间的转移成本。 这种耦合的改进显着促进了蒸馏过程。
因此,我们成功训练了第一个一步 SD 模型,能够生成具有出色细节的高质量图像。 值得注意的是,这是第一次采用纯监督学习的精炼单步 SD 模型的性能与 GAN 相当。
2. 相关作品
扩散模型和基于流的模型。扩散模型 [16,17,25,26,27,28,29,30,31] 在各种生成建模任务中取得了前所未有的成果,包括图像/视频生成 [9,32,33, 34, 35],音频生成 [36],点云生成 [37,38,39,40],生物生成 [34,41,42,43] 等。大多数工作都是基于随机微分方程(stochastic differential equations,SDE),研究人员已经探索了将它们转换为边际保留概率流常微分方程(ordinary differential equations,ODE)的技术 [17, 20]。 最近,[1,2,23,24,44] 提出通过在两个分布之间构造线性或非线性插值来直接学习概率流 ODE。 这些 ODE 获得了与扩散模型相当的性能,但需要的推理步骤要少得多。 在这些方法中,整流流 [1, 2] 引入了一种特殊的回流程序,该程序增强了分布之间的耦合,并将生成式 ODE 压缩为一步生成。 然而,回流的有效性仅在 CIFAR10 等小型数据集上进行了检验,因此引发了对其在大规模模型和大数据上的适用性的质疑。 在本文中,我们证明了 Rectified Flow 管道确实可以在大规模文本到图像扩散模型中实现高质量的一步生成,从而带来具有纯监督学习的超快速 T2I 基础模型。
大规模文本到图像生成。文本到图像生成的早期研究主要集中在小规模数据集,例如花卉和鸟类 [45,46,47]。 后来,该领域将注意力转向更复杂的场景,特别是在 MS COCO 数据集 [48] 中,导致训练和生成方面的进步 [49,50,51]。 DALL-E [7] 是基于 Transformer 的开创性模型,通过扩大网络规模和数据集规模,展示了令人惊叹的零样本文本到图像生成功能。 随后出现了一系列新方法,包括自回归模型 [14,52,53,54],GAN 逆映射 [55,56],基于GAN的方法 [57] 和扩散模型 [8,9,58,59] 。 其中,Stable Diffusion 是一个基于潜在扩散模型(LDM)的开源文本到图像生成器 [5]。 它在 LAION 5B 数据集 [12] 上进行训练,并实现了最先进的泛化能力。 此外,基于 GAN 的模型(如 StyleGAN-T [4] 和 GigaGAN [11])经过对抗性损失训练,可以快速生成高质量图像。 我们的工作提供了一种新颖的方法来产生超快速、一步式、大规模的生成模型,而无需精细的对抗性训练。
扩散模型的加速。尽管生成质量令人印象深刻,但由于需要多次迭代才能达到最终结果,扩散模型在推理过程中速度很慢。 为了加速推理,有两类算法。 第一类侧重于快速事后(post-hoc)采样器 [19,20,29,60,61,62]。 这些快速采样器可以将预训练扩散模型的推理步骤数减少到 20-50 个步骤。 然而,仅仅依靠推理来提高性能有其局限性,需要对模型本身进行改进。 蒸馏 [63] 已应用于预训练的扩散模型 [64],将推理步骤数压缩到10以下。渐进蒸馏(progressive distillation) [21] 是专门为扩散模型量身定制的蒸馏过程,并已成功生成 2/4- 步稳定扩散 [3]。 一致性模型 [22] 是一类新的生成模型,自然地以一步的方式运行,但它们在大规模文本到图像生成上的性能仍不清楚。 我们没有像以前的工作那样采用直接蒸馏,而是采用整流流 [1, 2],它利用回流过程来细化噪声分布和图像分布之间的耦合,从而提高蒸馏的性能。

3. 方法
3.1 大规模文本到图像的扩散模型和高效推理的需要
最近,各种基于扩散的文本到图像生成器 [5,10,58] 已经出现,具有前所未有的性能。 其中,稳定扩散(SD)[5],一种在 LAION-5B [12] 上训练的开源模型,受到了艺术家和研究人员的广泛欢迎。 它基于潜在扩散模型 [5],这是在学习的潜在空间中运行的去噪扩散概率模型 (denoising diffusion probabilistic model,DDPM) [16, 17]。 由于扩散模型的循环性质,SD 通常需要 100 多个步骤才能生成令人满意的图像。 为了加速推理,提出了一系列事后采样器 [18,19,20]。 通过将扩散模型转换为边际保留概率流,这些采样器可以将必要的推理步骤减少到 20 个步骤 [19]。 然而,当推理步骤数小于 10 时,它们的性能开始明显下降。对于 ≤10 步的情况,提出渐进蒸馏 [3, 21] 将所需的推理步骤数压缩到 2-4。 然而,是否有可能将像 SD 这样的大型扩散模型转变为质量令人满意的一步模型,这仍然是一个悬而未决的问题。
3.2 整流流(Rectified Flow)和回流(Reflow)
Rectified Flow [1, 2] 是一个基于 ODE 的统一框架,用于生成建模和域转移。 它提供了一种根据经验观察学习 R^d 上两个分布 π_0 和 π_1 之间的转移映射 T 的方法。 在图像生成中,π_0 通常是标准高斯分布,π_1 是图像分布。
整流流学习通过常微分方程 (ODE) 或流模型将 π_0 转移到 π_1

![]()
v 是一个速度场(velocity field),通过最小化如下简单均方目标来学习:
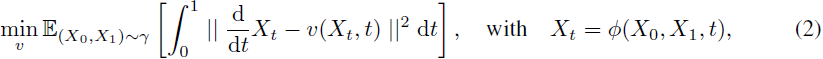
![]()
![]()
其中 X_t 是 X_0 和 X_1 之间的任意时间可微插值。 γ 是 (π_0, π_1) 的任意耦合。 γ 的一个简单例子是独立耦合 γ = π_0 × π_1,它可以根据经验从 π_0 和 π_1 的不配对观测数据中采样。 通常,v 被参数化为深度神经网络,并且等式(2)通过随机梯度方法近似求解。
插值过程 X_t 的不同具体选择导致不同的算法。 如 [1] 所示,常用的去噪扩散隐式模型(denoising diffusion implicit model,DDIM)[20] 和 [17] 的概率流 ODE 对应于
![]()
α_t,β_t 是专门选择的时间可微序列(参见 [1] 详细信息)。 然而,在整流流中,作者建议更简单的选择
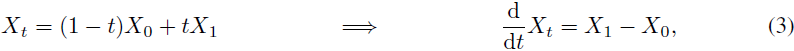
正如后续讨论的那样,它有利于在快速推理中发挥关键作用的直线轨迹(straight trajectories)。
直线流收获快速生成。 在实践中,(1) 中的 ODE 需要通过数值求解器进行近似。 最常见的方法是前向欧拉方法,它产生

我们以 ϵ = 1/N 的步长进行模拟,并以 N 个步骤完成模拟。

显然,N 的选择会产生成本与精度的权衡:大的 N 可以更好地逼近 ODE,但会导致较高的计算成本。
为了快速模拟,需要学习可以用小 N 准确且快速地仿真的 ODE。这导致 ODE 的轨迹是直线。 具体来说,我们说 ODE 是直线的(速度均匀),如果
![]()
在这种情况下,欧拉方法即使只有一步(N = 1)也能产生完美的模拟; 请参见图 4。因此,拉直 ODE 轨迹是降低推理成本的重要方法。
通过回流进行矫直。回流是一种迭代过程,可在不修改边缘分布的情况下矫直整流流的轨迹,从而允许在推理时进行快速模拟。 假设我们有一个 ODE 模型 dX_t = v_k(X_t, t)d_t,在回流过程的第 k 次迭代时速度场为 v_k; 用 X_1 = ODE [v_k] (X_0) 表示我们在 t = 1 时从 X_0 开始遵循 v_k-ODE 时获得的 X_t。 回流步骤将 v_k 转换为新的向量场 v_(k+1),产生更直接的 ODE,而
![]()
具有与 X_1 = ODE [v_k] (X_0) 相同的分布,

其中 v_(k+1) 是使用相同的修正流目标 (2) 学习的,但使用从先前的 ODE[v_k] 构造的 (X0,X1) 对的线性插值 (3)。
回流的关键特性是它保留了终端分布,同时拉直了轨迹并降低了转移映射的转移成本:
1)ODE [v_(k+1)] (X_0) 和 ODE [v_k] (X_0) 的分布重合; 因此,如果 v_k 将 π_0 转移到 π_1, 则 v_(k+1) 也如此。
2) ODE[v_(k+1)] 的轨迹往往比 ODE[v_k] 的轨迹更直(k 是整流次数,k 越大,轨迹越直)。 这表明模拟 ODE[v_(k+1)] 需要比 ODE[v_k] 更小的欧拉步数 N。 如果 v_k 是回流不动点,即 v_(k+1) = v_k,则 ODE[v_k] 必须是完全直线的。
3) (X_0, ODE[v_(k+1)](X_0)) 形成比 (X_0, ODE[v_k](X_0)) 更好的耦合,因为它产生较低的凸转移成本,即,对于所有凸函数 c : R^d → R,
![]()
这表明新的耦合可能更容易让网络学习 。
文本条件回流。在文本到图像的生成中,速度场 v 应另外依赖于输入文本提示 T 来生成相应的图像。 带文本提示的回流目标是

其中 D_T是文本提示的数据集,并且,
![]()
在本文中,我们将 v_1 设置为预训练的概率流ODE模型(例如稳定扩散,v_SD)的速度场,并将 v_k(k≥2)表示为 k-整流流。
蒸馏。理论上,需要无数次回流步骤 (5) 才能获得具有精确直线轨迹的 ODE。 然而,由于计算成本高以及优化和统计误差的积累,回流太多步骤是不切实际的。 幸运的是,在 [1] 中观察到,即使经过一两步回流,ODE[v_k] 的轨迹也几乎(尽管不完全)变得笔直。 对于这种近似笔直的 ODE,提高单步模型性能的一种方法是通过蒸馏:
![]()
其中我们学习单个欧拉步骤 x+v(x|T),通过最小化图像之间的可微相似性损失 D(·,·) 来压缩从 X0 到 ODE[v_k] (X_0|T) 的映射。 遵循 [1,21,22],我们采用学习感知图像块相似度(LPIPS)损失 [65] 作为相似度损失,因为它会带来更高的视觉质量和更好的定量结果。 通过蒸馏学习一步模型可以避免对抗性训练 [4,11,66] 或特殊的可逆神经网络 [67,68,69]。

在应用蒸馏之前,必须使用回流来获得良好的耦合。 值得注意的是蒸馏和回流之间的区别:虽然蒸馏试图诚实地近似从 X0 到 ODE[v_k](X_0|T) 的映射,但回流会产生一个新的映射 ODE[v_(k+1)](X_0|T),由于凸转移成本较低,因此可以更加规则和平滑。 在实践中,我们发现在应用蒸馏之前应用回流以使映射 ODE[v_k](X_0|T) 足够规则和平滑是至关重要的。
用于整流流的无分类器引导速度场。无分类器引导 [70] 对 SD 的生成质量有重大影响。 类似地,我们可以定义以下速度场以在学习的整流流上应用无分类器引导,
![]()
其中 α 权衡样本多样性和生成质量。 当 α = 1 时,v^α 变回原来的速度场 v(Z_t, t |T)。 我们在第 6 节中提供了对 α 的分析。
4. 稳定扩散 1.4 的初步观察
在本节中,我们使用稳定扩散 1.4 进行实验,以检查整流流框架和回流的有效性。
4.1 回流是改善蒸馏的关键
本节实验的目标是:
1) 检查直接蒸馏是否可以有效地从预训练的大规模 T2I 概率流 ODE 中学习一步模型;
2)检查文本条件回流是否可以增强蒸馏的性能。
我们的实验得出的结论是:回流显着简化了蒸馏的学习过程,并且回流后的蒸馏成功地产生了一步模型。
一般实验设置。在本节中,我们使用官方开源存储库(https://github.com/CompVis/stable-diffusion)中提供的预训练的 Stable Diffusion 1.4来初始化权重,否则收敛速度会慢得难以忍受。
在我们的实验中,我们将 D_T 设置为 laion2B-en [12] 中的文本提示的子集,并通过与 SD 相同的滤波器进行预处理。 ODE[v_SD] 被实现为具有 25 步 DPMSolver [19] 和固定指导尺度 6.0 的预训练稳定扩散。 我们将蒸馏的相似性损失 D(·,·) 设置为 LPIPS 损失[65]。 回流和蒸馏的神经网络结构均保留在 SD U-Net 中。 我们使用 32 个批量大小和 8 个 A100 GPU 来使用 AdamW 优化器 [71] 进行训练。 优化器的选择遵循 HuggingFace 中的默认协议 (https://huggingface.co/docs/diffusers/training/text2image) ,用于微调 SD。 我们采用指数移动平均线,比率为 0.9999。
4.1.1 直接蒸馏失败
实验协议。我们的研究从直接提取稳定扩散 1.4 的速度场 v1 = v_SD 与等式 (7) 开始,而不应用任何回流。为了实现最佳的经验性能,我们在计算资源的限制下对学习率和权重衰减进行网格搜索。 具体地,学习率选自 {10^(-5), 10^(-6), 10^(-7)},权重衰减系数选自{10^(-1), 10^(-2), 10^(-3)}。 对于所有 9 个模型,我们对它们进行 100,000 步的训练。 我们生成 32 × 100,000 = 3,200,000 对 (X_0, ODE[v_SD](X_0)) 作为蒸馏的训练集。 我们按照 [3] 中的评估协议计算了来自 MS COCO 2017 的 5, 000 个标题(captions)的 Fréchet 起始距离 (FID),然后我们在图 5 中显示了具有最低 FID 的模型。更多实验结果请参阅附录。
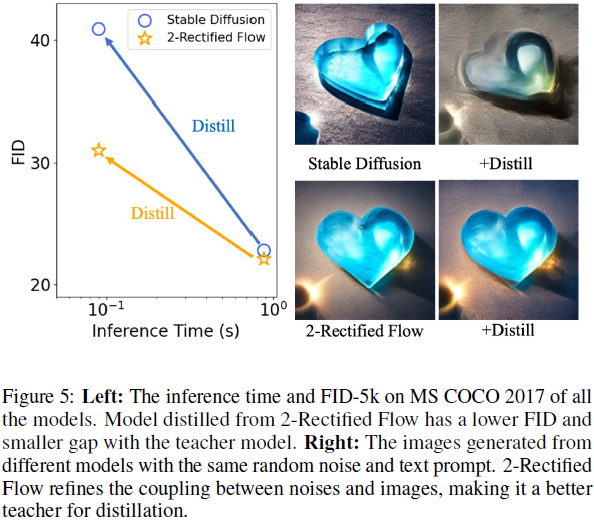
观察与分析。我们观察到,经过 100,000 个训练步骤后,所有九个模型都收敛了。 然而,所学习的一步生成模型还远远不能令人满意。 如图 5 所示,SD 和 SD+Distill 之间的 FID 存在巨大差距。 事实上,学生模型(SD+Distill)很难模仿教师模型(25步SD)。 图 5 右侧,在相同的随机噪声下,SD+Distill 生成的图像与教师 SD 有显着差异。 从实验中,我们得出的结论是:对于学生一步模型来说,直接从 SD 中蒸馏是一个棘手的学习问题,并且很难通过简单地调整超参数来缓解这一问题。
4.1.2 回流改善耦合并简化蒸馏
实验协议。为了与蒸馏进行公平比较,我们使用从预训练的 SD 初始化的权重训练 v_2 50, 000 个步骤,然后从获得的 v_2 继续执行另外 50, 000 个训练步骤的蒸馏。 回流的学习率为 10^(−6)。 为了从 2-整流流中提取,我们使用 25 步欧拉求解器生成 32 × 50,000 = 1,600,000 对 (X_0, ODE[v_2](X_0))。 结果也如图 5 所示,用于与直接蒸馏进行比较。 2-整流流的指导稀疏 α 设置为 1.5。
观察与分析。首先,得到的 2-整流流具有与原始 SD 相似的 FID,分别为 22.1 和 22.8。 它表明回流可用于学习具有可比性能的生成 ODE。 此外,2-整流流精练了噪声分布和图像分布之间的耦合,并简化了学生模型在蒸馏时的学习过程。 这可以从两个方面来推断。 (1) 2-整流流 + 蒸馏和 2-整流流之间的差距远小于 SD + 蒸馏和 SD。 (2) 在图 5 右侧,2-整流流 + 蒸馏生成的图像与原始生成的图像非常相似,表明学生更容易模仿。 这说明 2-整流流是比原始 SD 更好的提取学生模型的教师模型。
4.2 定量比较与补充分析
在本节中,我们提供额外的定量和定性结果以及进一步的分析和讨论。 2-整流流及其蒸馏版本按照与第 4.1.2 节中相同的训练配置进行训练。
扩大网络规模。对于蒸馏,我们考虑两种网络结构:(i)U-Net,它与 SD 的去噪 U-Net 完全相同的网络结构; (ii) Stacked U-Net,它是两个具有共享参数的 U-Net 直接串联的简化结构。 与两步推理相比,Stacked U-Net 通过删除一组不必要的模块,同时保持参数数量不变,将推理时间从 0.13 秒减少到 0.12 秒。 Stacked U-Net 比 U-Net 更强大,这使得它在蒸馏后能够获得更好的一步性能。 更多详细信息可以在附录中找到。
多次回流。根据等式 (6)、回流程序可重复多次。 我们再重复一次回流以获得 3-整流流 (v_3),它是从 2-整流流 (v_2) 初始化的。 3-整流流经过 50、000 步训练以最小化等式 (6) 。 然后,我们通过生成 1,600,000 个新的 (X_0, ODE[v_3](X_0)) 对来获得其蒸馏版本,并蒸馏另外 50,000 个步骤。 我们发现,为了稳定 3-整流流的训练过程及其蒸馏,我们必须将学习率从 10^(−6) 降低到 10^(−7)。
训练成本。由于我们的整流流是根据公开的预训练模型进行微调的,因此与其他大规模文本到图像模型相比,训练成本可以忽略不计。
- 在我们的平台上,当使用批量大小为 4 和 U-Net 进行训练时,A100 GPU 一天可以使用 L2 损失处理 100,000 次迭代,使用 LPIPS 损失处理 86,000 次迭代; 当生成批量大小为 16 的数据对时,A100 GPU 一天可以生成 200,000 个数据对。
- 因此,要得到 2-Rectified Flow + Distill(U-Net),训练成本约为 3,200,000/200,000(数据生成)+ 32/4×50,000/100,000(回流)+ 32/4×50,000/86,000(蒸馏) ≈ 24.65 A100 GPU 天。
- 作为参考,SD 1.4 从头开始的训练成本为 6250 A100 GPU 天 [5]; StyleGAN-T 是 1792 个 A100 GPU 天 [4]; GigaGAN 是 4783 个 A100 GPU 天 [11]。
- 在渐进式蒸馏中训练一步 SD 的下限估计为 108.8 A100 GPU 天 [3](估计的详细信息可以在附录中找到)。
MS COCO 上的比较。我们将模型的性能与 MS COCO 上的基线进行比较 [48]。
我们的第一个实验遵循 [3] 的评估协议,其中我们使用 MS COCO 2017 验证集中的 5,000 个标题(captions)并生成相应的图像。
- 然后我们使用 ViT-g/14 CLIP 模型 [72, 73] 测量 FID 分数和 CLIP 分数,以定量评估图像质量和与文本的对应性。
- 我们还记录了使用 NVIDIA A100 GPU 的不同模型生成一张图像的平均运行时间。为了公平比较,我们在渐进式蒸馏-SD 的计算平台上使用标准 SD 的推理时间,因为他们的模型不公开。 推理时间包含文本编码器和潜在解码器,但不包含 NSFW 检测器。
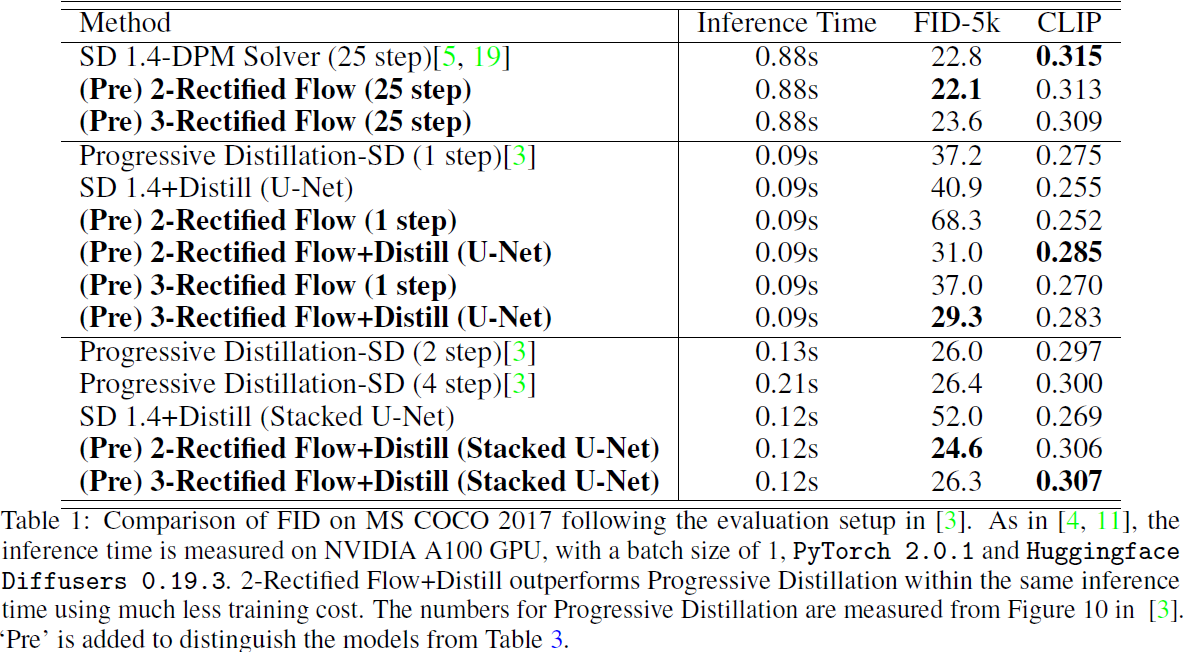
结果如表 1 所示。
- (pre)2-整流流和(pre)3-整流流可以生成逼真的图像,使用 SD 1.4 + DPMSolver 用 25 个步骤产生相似的 FID (22.1, 23.6 ↔ 22.8) 。
- 在 0.09 秒内,(pre)3-整流流+蒸馏(U-Net)的 FID 为 29.3,在 0.12 秒内,(pre)2-整流流+蒸馏(Stacked U-Net)的 FID 为 24.6, 超越了之前最好的蒸馏 SD 模型(分别为 37.2 和 26.0)[3]。

在我们的第二个实验中,我们使用 MS COCO2014 中的 30,000 个标题(captions),并在 FID 上执行相同的评估。结果如表 2 所示。
- 我们观察到(pre)2-整流流+蒸馏(Stacked U-Net)获得的 FID 为 13.7,这比使用 Stacked U-Net 的 SD+蒸馏(41.5)要好得多。
- 我们凭经验发现,在两个实验中,SD+Distill 在使用较大的 Stacked U-Net 时具有较差的 FID,尽管它具有更好的视觉质量。 这可能是由于当图像与真实图像严重偏差时 FID 指标不稳定造成的。
回流的矫直效果。我们凭经验检查文本到图像生成中回流的特性。 为了定量测量直线度,我们使用沿着 [1, 2] 轨迹的速度导数,即
![]()
S(Z) 越小意味着轨迹越直,当 ODE 轨迹都是完全直的时,S(Z) = 0。我们随机生成 1, 000 条轨迹来估计 S(Z)。 结果如图 6 和图 7 所示。在图 6 中,每次回流都会降低估计的 S(Z),验证了回流的矫直效果。 此外,稳定扩散和 2-整流流之间的差异对于人类来说是显而易见的。 稳定扩散中的像素沿着弯曲的轨迹行进,而 2-整流流则具有更直的轨迹。 真实图像中也存在拉直效应。 图 7 表明,在稳定扩散上应用回流可以显着拉直 ODE 轨迹,使 2-整流流一步生成可识别的图像,并简化蒸馏。


5. 迈向更好的一步生成:稳定扩散 1.5 的扩展
我们使用稳定扩散 1.4 的初步结果证明了采用回流程序在提炼一步生成模型中的优势。 不过,由于 A100 GPU 仅花费了 24.65 个 GPU 天进行训练,因此很有可能通过更多资源来进一步提升性能。 因此,我们用更大的批量大小来延长训练时间,以检查扩大规模是否对结果产生积极影响。 答案是肯定的。 通过 199 个 A100 GPU 天,我们获得了第一个一步 SD,可以在 0.09 秒内生成具有复杂细节的高质量图像,与最先进的 GAN 之一 StyleGAN-T [4] 相当。
实现细节和训练流程。我们切换到稳定扩散 1.5,并保持与第 4 节中相同的 D_T。ODE 求解器仍使用 25 步 DPMSolver [19] 来实现 ODE[v_SD]。 引导比例稍微减小到 5.0,因为较大的引导比例会使 2-整流流生成的图像过饱和。 由于从 2-整流流中提取得到了令人满意的结果,因此 3-整流流没有经过训练。 我们仍然分别为回流和蒸馏生成 1,600,000 对数据。 为了将批量大小扩大到大于 4 × 8 = 32,应用了梯度累积。 2-Rectified Flow+Distill (U-Net) 的整体训练流程总结如下:
- 回流(第 1 阶段):我们使用回流目标等式 (6) 训练模型,批量大小为 64,迭代次数为 70,000 次。 该模型根据预训练的 SD 1.5 权重进行初始化。 (11.2 A100 GPU 天)
- 回流(第 2 阶段):我们继续使用回流目标等式 (6) 训练模型,并将批量大小增加到 1024,进行 25,000 次迭代。 最终模型是 2-整流流。 (64 A100 GPU 天)
- 蒸馏(第 1 阶段):从 2-整流流检查点开始,我们固定神经网络的时间 t = 0,并使用蒸馏目标等式 (7) 对其进行微调,批量大小为 1024,迭代次数为 21,500 次。 教师模型 2-Rectified Flow 的指导尺度 α 设置为1.5,相似度损失 D 为 L2 损失。 (54.4 A100 GPU 天)
- 蒸馏(第 2 阶段):我们将相似性损失 D 切换为 LPIPS 损失,然后继续使用蒸馏目标等式 (7) 和批量大小 1024 训练模型,进行另外 18,000 次迭代。 最终模型是 2-整流流+蒸馏(U-Net)。 我们将其命名为 InstaFlow-0.9B。 (53.6 A100 GPU 天)
InstaFlow-0.9B 的总训练成本为 3,200,000/200,000(数据生成)+ 11.2 + 64 + 54.4 + 53.6 = 199.2 A100 GPU 天。
用于一步生成的更大神经网络。扩大模型大小是构建现代基础模型的关键一步 [5,6,74,75,76]。 为此,我们采用第 4 节中的 Stacked U-Net 结构,但放弃参数共享策略。 这给了我们一个具有 1.7B 参数的 Stacked U-Net,几乎是原始 U-Net 的两倍。 从 2-整流流开始,通过以下蒸馏步骤训练 2-整流流+蒸馏(Stacked U-Net):
- 蒸馏(第 1 阶段):Stacked U-Net 根据 2-整流流检查点中的权重进行初始化。 然后我们固定神经网络的时间 t = 0,并使用蒸馏目标等式 (7) 对其进行微调,批量大小为 64,迭代次数为 110,000 次。 相似度损失 D 是 L2 损失。 (35.2 A100 GPU 天)
- 蒸馏(第 2 阶段):我们将相似性损失 D 切换为 LPIPS 损失,然后继续使用蒸馏目标等式 (7) 和批量大小 320 训练模型,进行另外 2,500 次迭代。 最终模型是2-整流流+蒸馏(Stacked U-Net)。 我们将其命名为 InstaFlow-1.7B。 (4.4 A100 GPU 天)
讨论 1(实验观察)。在训练过程中,我们进行了以下观察:
- 2-整流流模型没有完全收敛,其性能可能会受益于更长的训练时间;
- 与回流相比,蒸馏表现出更快的收敛性;
- LPIPS 损失对提高蒸馏一步模型的视觉质量有直接影响。
- 基于这些观察,我们相信,通过更多的计算资源,可以进一步改进一步模型。
讨论 2(一步 Stacked U-Net 和两步渐进蒸馏)。虽然一步 Stacked U-Net 和两步渐进蒸馏(PD)需要相似的推理时间,但它们有两个关键区别:
- 两步 PD 另外,还最大限度地减少了 t = 0.5 时的蒸馏损失,这对于从 t = 0 开始的一步生成来说可能是不必要的;
- 通过将连续的 U-Net 作为一个模型,我们能够检查并删除这个大型神经网络中的冗余组件,进一步将推理时间减少约 8%(从 0.13 秒减少到 0.12 秒)。
6. 评价
在本节中,我们系统地评估 2-整流流和蒸馏一步模型。 我们将我们的一步模型 2-整流流+蒸馏 (U-Net) 命名为 InstaFlow-0.9B,将 2-整流流+蒸馏 (Stacked U-Net) 命名为 InstaFlow-1.7B。
6.1 与 MS COCO 上最新技术的比较
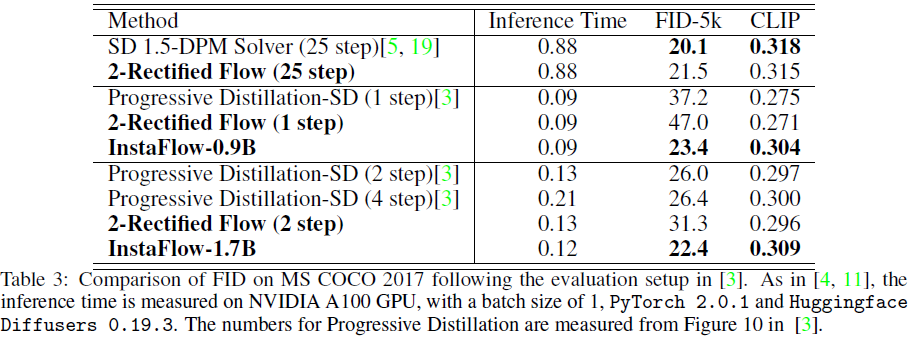
我们遵循 4.2 节中的实验配置。 教师模型 2-整流流的指导尺度 α 设置为 1.5。 在表 3 中,
- 我们的 InstaFlow-0.9B 的 FID-5k 为 23.4,推理时间为 0.09 秒,明显低于之前最先进的渐进蒸馏-SD(1 步)。
- Progressive Distillation-SD(1 步)[3] 的训练成本≥ 108.8 A100 GPU 天,而 InstaFlow-0.9B 蒸馏步骤的训练成本为 54.4 + 53.6 = 108 A100 GPU 天。 在相似的蒸馏成本下,InstaFlow-0.9B 具有明显的优势。
- 实证结果表明,回流有助于改善噪声和图像之间的耦合,并且 2-整流流是更容易提取的教师模型。
- 通过增加模型大小,InstaFlow-1.7B 将 FID-5k 降低至 22.4,推理时间为 0.12 秒。

在 MS COCO 2014 上,
- 我们的 InstaFlow-0.9B 在 0.09 秒内获得了 13.10 的 FID-30k,超过了 StyleGAN-T [4](0.1 秒内为 13.90)。 这是第一次一步蒸馏 SD 的性能与最先进的 GAN 相当。
- 使用具有 1.7B 参数的 Stacked U-Net,我们的一步模型的 FID-30k 达到了 11.83。 尽管这仍然高于 GigaGAN [11],但我们相信更多的计算资源可以缩小差距:GigaGAN 在训练中花费了超过 4700 个 A100 GPU 天,而我们的 InstaFlow-1.7B 仅消耗 130.8 个 A100 GPU 天。
6.2 2-整流流分析
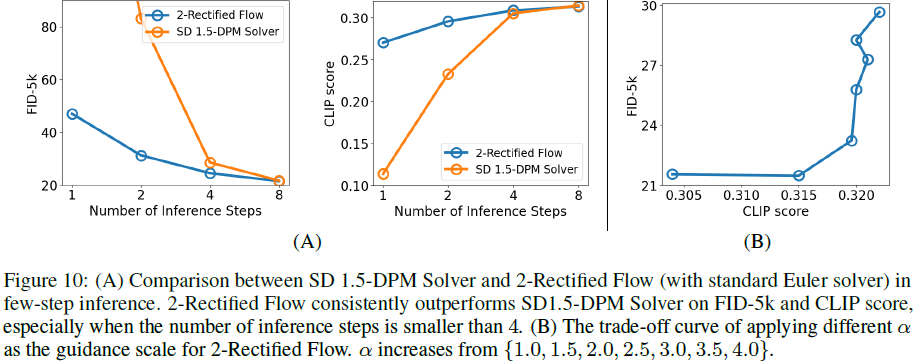

少步骤生成。2-整流流具有更直的轨迹,这使其能够以极少的推理步骤进行生成。 我们在 MS COCO 2017 上将 2-整流流与 SD 1.5-DPM 求解器 [61] 进行比较。2-整流流采用标准欧拉求解器。 推理步骤设置为 {1,2,4,8}。 图 10(A)清楚地显示了当推理步骤数 ≤4 时 2-整流流的优势。在图 11 中,2-整流流可以比具有 1,2,4 步的 SD 更好地生成图像,这意味着它具有比原始 SD 1.5 更直的 ODE 轨迹。

引导尺度 α。众所周知,引导尺度 α 是使用稳定扩散时的一个重要超参数 [5, 70]。 通过改变引导比例,用户可以改变语义对齐和生成质量。 在这里,我们研究了引导尺度 α 对 2-整流流的影响,它具有更直的 ODE 轨迹。
- 在图 10 (B) 中,将 α 从 1.0 增加到 4.0 会同时增加 MS COCO 2017 上的 FID-5k 和 CLIP 分数。 前一个度量表示图像质量的下降,后一个度量表示语义对齐的增强。
- 生成的示例如图 12 所示。虽然趋势与原始 SD 1.5 类似,但存在两个关键区别。
- (1) 即使当 α = 1.0(无指导)时,生成的图像也已经具有不错的质量,因为我们在 SD 1.5 上以 5.0 的指导比例进行回流,从而在训练中丢弃了低质量图像。 因此,可以避免在推理过程中使用无分类器指导以节省 GPU 内存。
- (2) 与原来的SD 1.5 不同,改变引导比例不会给生成的内容带来巨大的变化。 相反,它只会扰乱细节和基调。 我们将对这些新行为的解释作为未来的方向。

2-整流流和一步模型之间的对齐。生成模型学到的潜在空间具有有趣的特性。 通过正确利用其潜在结构,先前的工作成功地实现了图像编辑 [33,79,80,81,82,83,84],语义控制 [55,56,85],解耦控制方向发现 [86,87,88, 89] 等。一般来说,单步生成器(如 GAN)的潜在空间通常比多步扩散模型更容易分析和使用。 我们的管道的优点之一是它同时提供多步连续流和相应的单步模型。 图 13 显示我们精炼的一步模型的潜在空间与 2-整流流一致。 因此,一步模型可以很好地替代理解和利用连续流的潜在空间,因为后者具有更高的生成质量。
6.3 使用一步模型快速预览

我们的一步模型的一个潜在用例是用作预览器。 通常,大规模文本到图像模型以级联方式工作[90]:
- 用户可以从多个低分辨率图像中选择一个图像,然后扩展的超分辨率模型将所选的低分辨率图像扩展到更高分辨率。
- 在第一步中,低分辨率图像的构图/色调/风格/其他组成部分可能令用户不满意,甚至没有考虑细节。
- 因此,快速预览器可以加速低分辨率过滤过程,并在相同的计算预算下为用户提供更多的生成可能性。
- 然后,强大的后处理模型可以提高质量并提高分辨率。
我们使用 SDXL-Refiner [6] 验证了这个想法,SDXL-Refiner 是一种可以细化生成图像的最新模型。
- 一步模型 InstaFlow-0.9B 和 InstaFlow-1.7B 生成 512 × 512 图像,然后将这些图像插值到 1024 并通过 SDXL-Refiner 细化以获得高分辨率图像。
- 几个例子如图14所示。一步生成的低分辨率图像决定了图像的内容、构图等; 然后 SDXL-Refiner 精炼扭曲的部分,添加额外的细节,并协调高分辨率图像。
7. 最好的尚未到来
扩散模型的循环性质阻碍了它们在边缘设备上的部署 [91, 92],损害了用户体验,并增加了总体成本。 在本文中,我们证明可以使用文本条件整流流框架从预训练的稳定扩散(SD)中获得强大的一步生成模型。 根据我们的结果,我们提出了几个有前景的未来探索方向:
- 改进 One-Step SD:尽管投入了 75.2 个 A100 GPU 天,但 2-整流流模型的训练并未完全收敛。 这只是原始 SD(6250 A100 GPU 天)训练成本的一小部分。 通过扩大数据集、模型大小和训练持续时间,我们相信一步 SD 的性能将显着提高。 此外,SOTA 基础模型,例如 SDXL [6],可以用作教师来增强一步 SD 模型。
- 一步控制网络 [93]:通过应用我们的管道来训练控制网络模型,可以获得能够在几毫秒内生成可控内容的一步控制网络。 唯一需要的修改包括调整模型结构并纳入控制模态作为附加条件。
- 一步模型的个性化:通过以扩散模型和 LORA [94] 的训练目标对 SD 进行微调,用户可以定制预训练的 SD 以生成特定的内容和风格 [95]。 然而,由于一步模型与传统扩散模型有很大区别,确定微调这些一步模型的目标仍然是一个需要进一步研究的课题。
- 用于一步生成的神经网络结构:研究界普遍认为, U-Net 结构在图像生成中扩散模型的令人印象深刻的性能中,发挥着至关重要的作用 [16,17,30]。 随着使用文本条件回流和蒸馏创建一步 SD 模型的进展,出现了几个有趣的方向:(1)探索替代的一步结构,例如 GAN 中使用的成功架构 [4,11,96,97], 在质量和效率方面有可能超越 U-Net; (2) 利用剪枝、量化和其他构建高效神经网络的方法等技术,使一步生成在计算上更加经济实惠,同时最大限度地减少潜在的质量下降。
参考
Liu X, Zhang X, Ma J, et al. InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation[J]. arXiv preprint arXiv:2309.06380, 2023.
附录
A. 神经网络结构
我们的文本到图像生成模型的整个流程由三部分组成:文本编码器、潜在空间中的生成模型和解码器。 我们使用与稳定扩散相同的文本编码器和解码器:文本编码器采用 CLIP ViT-L/14,潜在解码器采用下采样因子为 8 的预训练自动编码器。在训练期间,文本编码器和潜在解码器中的参数被冻结。 平均而言,要在批量大小为 1 的 NVIDIA A100 GPU 上生成 1 张图像,文本编码需要 0.01 秒,潜在解码需要 0.04 秒。

默认情况下,潜在空间中的生成模型是 U-Net 结构。 对于回流,我们不改变任何结构,只是微调模型。 为了进行蒸馏,我们测试了三种网络结构,如图 15 所示。第一个结构是 SD 中原始的 U-Net 结构。 第二种结构是通过直接连接两个具有共享参数的 U-Net 获得的。 我们发现第二种结构显着降低了蒸馏损失并提高了蒸馏后生成图像的质量,但它使计算时间增加了一倍。
为了减少计算时间,我们通过删除第二个结构中的不同块来测试一系列网络结构。 通过这个,我们可以在蒸馏中检查该级联网络中不同块的重要性,删除不必要的块,从而进一步减少推理时间。 我们进行了一系列消融研究,包括:
- 删除 “下采样块 1(左侧的绿色块)”
- 删除 “上采样块 1(左侧的黄色块)”
- 删除中间的 “输入+输出块”(中间的蓝色和紫色块)。
- 删除 “下采样块 2(右侧的绿色块)”
- 删除 “上采样块 2(右侧的黄色块)”
唯一不会损害性能的是结构 3,它使我们的推理时间减少了 7.7% ( (0.13−0.12)/0.13 = 0.0769)。 第三种结构,Stacked U-Net,如图 15 (c) 所示。
S. 总结
S.1 主要思想
扩散模型以其卓越的质量和创造力彻底改变了文本到图像的生成。 然而,其多步采样过程很慢,通常需要数十个推理步骤才能获得满意的结果。通过蒸馏提高采样速度并降低计算成本的尝试未能成功。主要问题源于噪声和图像的次优耦合,这极大地阻碍了蒸馏过程。
本文的主要贡献:
- 提出了 InstaFlow,这是源自稳定扩散(SD)的第一个基于单步扩散的文本到图像生成器。利用整流流(Rectified Flow,概率流的生成模型的最新进展) 来解决蒸馏 SD 的失败。整流流采用回流(Reflow)拉直概率流的轨迹,细化噪声和图像之间的耦合,并促进学生模型的蒸馏过程。
- 使用扩展的 Stacked U-Net 可进一步提升性能(虽然伴随着接近双倍的参数)。
S.2 方法
整流流(Rectified Flow)和回流(Reflow)。整流流学习通过常微分方程 (ODE) 或流模型将高斯分布 π_0 转移到图像分布 π_1。
- ODE 需要通过数值求解器进行近似。 最常见的方法是前向欧拉方法,以 N 个步骤实现分布转移。
- 如图 2 所示,Z_0 ~ π_0,Z_1 ~ π_1。大的 N 可以更好地逼近 ODE,但会导致较高的计算成本。
- 为了用小 N 准确且快速地模拟的 ODE,这需要 ODE 的轨迹是直线。
- 回流是一种迭代过程,可在不修改边缘分布的情况下矫直整流流的轨迹,从而允许在推理时进行快速模拟。
- 在文本到图像的生成中,可以基于文本提示,用文本条件回流来生成图像。
- 理论上,需要无数次回流才能获得具有精确直线轨迹的 ODE。 然而,由于计算成本高以及优化和统计误差的积累,回流太多步骤是不切实际的。 幸运的是,即使经过一两步回流,ODE 的轨迹也几乎(尽管不完全)变得笔直。
蒸馏。对于这种近似笔直的 ODE,提高单步模型性能的一种方法是通过蒸馏。














 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









