







RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
部分图像上传缓慢,可看原论文或在 EDPJ 查看
目录
0. 摘要
强化学习(Reinforcement learning,RL)通过直接优化捕捉图像质量、美学和指令遵循能力的奖励,改进了扩散模型引导图像生成。然而,由此产生的生成策略继承了扩散模型的相同迭代采样过程,导致生成速度缓慢。为了克服这一限制,一致性模型提出了学习一种新的生成模型,直接将噪声映射到数据,从而产生一种可以在至少一个采样迭代中生成图像的模型。在这项工作中,为了针对任务特定的奖励优化文本到图像的生成模型,并实现快速训练和推断,我们提出了一个通过 RL进行细化的一致性模型的框架。我们的框架,称为一致性模型的强化学习(Reinforcement Learning for Consistency Model,RLCM),将一致性模型的迭代推理过程构建为 RL 过程。RLCM 在文本到图像生成能力上改进了 RL 细化的扩散模型,并在推理时交换计算以获得样本质量。在实验中,我们展示了 RLCM 能够将文本到图像一致性模型调整到使用提示难以表达的目标,例如图像可压缩性,以及从人类反馈中得出的目标,例如美学质量。与 RL 细化的扩散模型相比,RLCM 的训练速度显著更快,根据奖励目标测量的生成质量得到了提高,并通过在仅两个推理步骤中生成高质量图像加速了推理过程。
项目页面:https://rlcm.owenoertell.com/
3. 基础
3.1 强化学习
我们将我们的序贯决策过程建模为有限时间段的马尔可夫决策过程(MDP),M = (S, A, P, R, μ, H)。在这个元组中,我们定义了我们的状态空间 S,动作空间 A,转移函数 P: S × A → Δ(S),奖励函数 R: S × A → R,初始状态分布 μ 和时间段(horizon) H。在每个时间步 t,代理观察到一个状态 s_t ∈ S,根据策略 π(a_t | s_t) 采取一个动作,并过渡到下一个状态 s_(t+1) ∼ P(s_(t+1) | s_t, a_t)。经过 H 个时间步后,代理生成一个轨迹,作为状态和动作序列 τ = (s_0, a_0, s_1, a_1, . . . , s_H, a_H)。我们的目标是学习一个策略 π,最大化从 π 中采样的轨迹上的期望累积奖励。
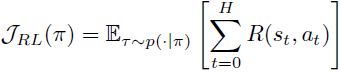
3.2 扩散模型与一致性模型
生成模型旨在将模型与数据分布匹配,这样我们就可以通过从分布中采样来随意合成新的数据点。扩散模型属于一种新颖的生成模型类型,它使用分数函数而不是密度函数来描述概率分布。具体而言,它通过逐渐修改数据分布然后通过连续去噪步骤从噪声中生成样本来产生数据。更正式地说,我们从数据分布 p_data(x) 开始,根据随机微分方程(SDE)(Song 等人,2020年)将其与噪声混合:
![]()
对于给定的 t ∈ [0, T],固定常数 T > 0,并且漂移(drift)系数 μ(·, ·)、扩散系数 σ(·),{w}_(t∈[0,T]) 是布朗运动。令 p_0(x) = p_data(x),p_t(x) 为由上述 SDE 引起的时间 t 的边际分布,如 Song 等人 (2020) 所示,存在一个 ODE(也称为概率流),其在时间 t 的引起(induced)分布也是 p_t(x)。特别地:
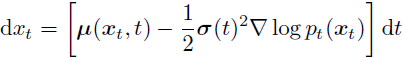
∇log pt(xt) 也被称为得分函数(Song & Ermon,2019年;Song 等人,2020年)。在这种设置下训练扩散模型时,使用一种称为得分匹配的技术(Dinh 等人,2016年;Vincent,2011年),其中训练一个网络来近似得分函数,然后使用 ODE 求解器采样轨迹。一旦我们学习到这样一个近似得分函数的神经网络,我们可以通过从 T 到 0 向后时间积分上述 ODE 来生成图像,其中 xT ∼ pT,这通常是一个可处理的分布(例如,在大多数扩散模型的公式中是高斯分布)。
这种技术明显受到一个事实的制约,在生成过程中,必须对 ODE 求解器进行大量步骤的反向(从 T 到 0)才能获得具有竞争力的样本(Song 等人,2023年)。为了缓解这个问题,Song 等人(2023年)提出了一致性模型,其目标是直接将噪声样本映射到数据。目标变成了在给定概率流上学习一致性函数。这个函数的目的是对于任意的 t,t′ ∈ [ϵ,T],概率流 ODE 上的两个样本,它们通过一致性函数映射到相同的图像:f_θ(xt, t) = f_θ(xt′ , t′) = x_ϵ,其中 x_ϵ 是时间 ϵ 处 ODE 的解。在高层次上,这个一致性函数通过取两个相邻的时间步长并在某个图像距离度量下最小化一致性损失 d(fθ(xt, t), fθ(xt′ , t′)) 来训练。为了避免一个恒定的平凡解,我们还将初始条件设置为 fθ(xϵ, ϵ) = xϵ。
一致性模型中的推理:在模型训练后,可以使用附录 A 算法 2 中给出的多步推理过程来将推理时间交换为生成质量。在高层次上,多步一致性采样算法首先将概率流分成 H + 1 个点(T = τ0 > τ1 > τ2 . . . > τH = ϵ)。给定一个样本 xT ∼ pT,然后在(xT,T)处应用一致性函数 fθ,得到 ^x0。为了进一步提高 ^x0 的质量,可以使用方程
![]()
再次将噪声添加到 ^x0 中,然后在(^x_(τn),τn)处应用一致性函数,得到 ^x0。可以重复这个过程几步,直到生成质量满意为止。在本文的其余部分,我们将引用使用多步程序进行采样。我们在稍后介绍 RLCM 时也会提供更多细节。
3.3 用于扩散模型的强化学习
Black 等人(2024年)和 Fan 等人(2023年)将条件扩散概率模型(Sohl-Dickstein 等人,2015年;Ho 等人,2020年)的训练和微调形式化为一个马尔可夫决策过程(MDP)。Black 等人(2024年)定义了一类算法,称为去噪扩散策略优化(DDPO),该算法优化任意奖励函数以改进使用 RL 对扩散模型进行引导微调。
扩散模型去噪作为 MDP 的条件扩散概率模型在上下文 c(在文本到图像生成的情况下,为提示)上进行条件。如 DDPO 所介绍的,我们将迭代去噪过程映射到 MDP M = (S, A, P, R, μ, H)。让 r(s, c) 为任务奖励函数。另外,注意概率流从 xT → x0 进行。将 T = τ0 > τ1 > τ2 . . . > τH = ϵ 划分为概率流间隔:
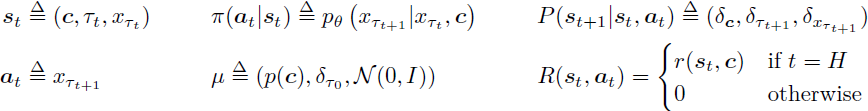
其中 δy 是在 y 处非零密度的狄拉克 delta 分布。换句话说,我们将图像映射为状态,并将去噪流中下一个状态的预测作为动作。此外,我们可以将确定性动态看作是让下一个状态成为策略选择的动作。最后,我们可以认为每个状态的奖励直到轨迹结束时都为 0,然后根据任务奖励函数评估最终图像。这种表述允许以下损失项:
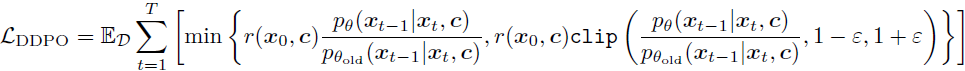
其中使用修剪来确保当我们优化 pθ 时,新策略保持接近 pθold,这是一个由著名算法 Proximal Policy Optimization (PPO)(Schulman 等人,2017年)推广的技巧。
在扩散模型中,通常将 horizon H 设置为 50 或更大,时间 T 设置为 1000。选择小的步长用于 ODE 求解器以最小化误差,确保生成高质量图像,正如 Ho 等人 (2020年) 所展示的那样。由于长时间跨度和稀疏奖励,使用强化学习训练扩散模型可能具有挑战性。
4. 一致性模型的强化学习
为了解决在扩散模型的 MDP 制定过程中发生的长期推理时间跨度,我们将一致性模型重新构建为一个 MDP。我们也让 H 表示此 MDP 的时间跨度。就像我们对 DDPO 所做的一样,我们将整个概率流 ([0, T]) 划分为段,T = τ0 > τ1 > . . . > τH = ϵ。在本节中,我们将 t 表示为 MDP 中的离散时间步长,即 t ∈ {0, 1, . . . ,H},而 τt 是连续时间区间 [0, T] 中的相应时间。我们现在提出一致性模型 MDP 公式。
一致性模型推理作为MDP。我们将一致性模型中的多步推理过程(算法2)重新制定为 MDP:
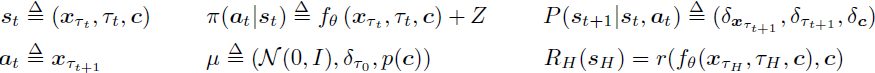
![]()
其中 Z 是算法 2 中第 5 行的噪声。此外,r(·, ·) 是我们用来对齐模型的奖励函数,RH 是时间步 H 的奖励。在其他时间步上,我们让奖励为 0。我们可以在图 2 中可视化从多步推理到 MDP 的转换。将 MDP 建模为策略
![]()
而不是将 π(·) 定义为一致性函数本身,这有一个重要的好处,即这使我们得到一个随机策略而不是确定性算法(例如 DPG (Silver 等人,2014年),我们发现这种算法不稳定且通常不是无偏的。因此,策略由两部分组成:一致性函数和加入高斯噪声。一致性函数采用图 2 中红色箭头的形式,而噪声则是绿色箭头。换句话说,我们的策略是一个高斯策略,其均值由一致性函数 fθ 模拟,方差为 (τ^2_t −ϵ^2)·I(这里的 I 是单位矩阵)。注意,根据算法 2 中的采样过程,我们只对轨迹的一部分加入噪声。请注意,轨迹的最后一步略有不同。特别地,为了计算最终奖励,我们只需使用一致性函数进行过渡(红/黄色箭头),然后在那里获得最终奖励。
策略梯度 RLCM。我们可以使用策略梯度优化器来实例化 RLCM,与 Black等人(2024年);Fan等人(2023年)的精神相一致。我们的算法描述如算法 1 所示。在实践中,我们会对每个提示的奖励进行归一化。也就是说,我们为每个提示创建一个运行均值和标准差,并将其用作归一化器,而不是在每批次中计算。这是因为在某些奖励模型下,每个提示的平均分数可能会有很大的变化。
5. 实验
6. 结论和未来方向
我们提出了 RLCM,这是一个快速高效的 RL 框架,可以直接优化各种奖励来训练一致性模型。我们在实证上展示了 RLCM 在大多数任务上都比扩散模型 RL 基线 DDPO 表现更好,同时享受一致性模型的快速训练和推理时间优势。最后,我们提供了微调模型的定性结果,并测试了它们的下游泛化能力。
仍然有一些未探索的方向,我们将其留给未来的工作。特别是,所提出的特定策略梯度方法使用了稀疏奖励。可以考虑使用密集奖励,利用一致性模型始终预测到 x0 的属性。另一个未来的方向是创建一个进一步强化一致性属性的损失,进一步提高 RLCM 策略的推理时间能力。

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









