







LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models

目录
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
0. 摘要
视觉指令微调(Visual instruction tuning)在增强大型多模态模型(Large Multimodal Models,LMMs)能力方面取得了显著进展。然而,现有的开源 LMM 主要关注单图像任务,对于多图像场景的应用探索较少。此外,以往的 LMM 研究通常分别针对不同场景展开研究,这导致无法实现新兴能力的跨场景泛化。
为此,我们提出了 LLaVA-NeXT-Interleave,该模型同时处理多图像、多帧(视频)、多视角(3D)和多区域(单图像)场景的任务。
- 为了实现这些能力,我们将交错数据格式视为通用模板,并编译了 M4-Instruct 数据集,包含 117.76 万条样本,涵盖 4 个主要领域的 14 项任务和 41 个数据集。
- 同时,我们精心设计了 LLaVA-Interleave Bench,用于全面评估 LMMs 在多图像任务中的性能。
- 通过广泛的实验,LLaVA-NeXT-Interleave 在多图像、视频和 3D 基准测试中取得了领先的结果,同时保持了单图像任务的性能。
- 此外,我们的模型还展现了一些新兴能力,例如跨不同设置和模态传递任务的能力。
2. 相关工作
2.1 交错图像-文本训练数据
作为一种更通用的格式,交错图像-文本数据为 LMMs(大规模多模态模型)赋予了两种独特的能力:多模态上下文学习(in-context learning,ICL)能力和在真实世界多图像应用场景中的指令遵循(instruction-following)能力。
多模态上下文学习能力(ICL)。上下文场景会在提示中交错若干图像-文本示例作为任务演示,使 LMM 在推理阶段以小样本方式适应新任务。Flamingo [1] 是第一个展示这一能力的模型,因此被视为多模态领域的 “GPT-3 moment”。通常,多模态 ICL 能力是在对网页规模的原始交错图像-文本序列进行预训练后涌现的。
在开源社区中:
- MMC4 [68] 引入了一个公开的包含 1.012 亿条交错数据的数据集,涵盖日常话题。
- OBELICS [22] 提供了一个过滤后的数据集,包括 1.41 亿条交错网页。
- Kosmos-1 [18] 构建了一个包含 7100 万条多模态语料的数据集,其中包含任意交错的文档。
- 为了显式启用 ICL 能力,MIMIC-IT [25] 在指令微调阶段提出了一条自动化流程,创建了 280 万条多模态样本。
多图像场景能力。另一类多图像场景则旨在应对涉及多张图像的多样化真实世界应用场景。
- VPG-C [27] 使用 ChatGPT 收集了 4 个新数据集。
- Mantis-Instruct [19] 整合了 11 个现有交错数据集并创建了 4 个新数据集。
- M4-Instruct [19] 整合了 41 个现有交错数据集并创建了 6 个新数据集,涵盖的场景多样性远超 Mantis-Instruct。
2.2 交错式 LMMs
- 作为代表性闭源 LMM,GPT-4V [42] 和 Gemini [12] 都支持真实世界中的多图像应用场景,并表现出领先性能。
- 借助各种公开数据集,研究社区已开发出具备显著多图像能力的开源LMMs。
- ICL 性能通常被用来评估多模态预训练,这一方法已被多个知名 LMM 采用,如 OpenFlamingo [2]、IDEFICS 系列 [22, 23]、VILA [33]、MM1 [41]和 Emu2 [51]。
- Otter [25] 以 OpenFlamingo 为基础,在 MIMIC-IT 数据集上进行微调,通过指令微调进一步提升 ICL 能力。
- 相比之下,尽管 Mantis [19] 探索了相关方向,但在 LMM 中利用指令微调实现各种真实世界多图像应用的研究仍然较少。
- 我们提出的 LLaVA-NeXT-Interleave 不仅通过改进实验结果拓展了多图像场景的范围,还实现了一个模型在多种场景中的泛化,例如视频、3D 和单图像。跨场景训练带来了新兴能力,使模型能够在新的多图像上下文中实现零样本任务组合。
2.3 交错基准测试(Benchmark)
为了评估 LMM 在交错多图像任务中的能力,已有多个高质量基准测试覆盖了各种场景。
ICL 基准测试。ICL 基准测试 [20, 49] 为 LMM 提供从小样本到多样本的评估方案,全面评估其交错能力。
更具挑战性的多图像场景。以往的工作主要关注特定领域的评估,包括:
- NLVR2 [50]:用于日常生活场景的视觉问答(VQA)。
- MMMU [61]:针对大学水平问题求解。
- MathVerse-mv [65] 和 SciVerse-mv [13]:评估数学和科学推理能力。
- BLINK [10]:挑战 LMM 在多图像处理中的表现。
- Mantis-Eval [19]:专注于多图像理解。
DEMON 基准。为进一步评估多图像场景中的 LMM 性能,DEMON [27] 是第一个集合数十个数据集(共 47.7 万条样本)的基准测试。凭借数据量大且多样性高的特点,DEMON 为多图像研究奠定了良好基础。然而,它也继承了现有数据集中大量低质量样本的问题。
LLaVA-Interleave Bench。为优化评估质量,本文提出的 LLaVA-Interleave Bench 精心筛选了高质量样本,涵盖特定(合成、数学、低级)和通用(日常、真实场景、文本丰富)多图像场景。该基准测试包含 9 个新策划的数据集和 13 个现有数据集,按照领域划分为:
- 域内评估:12.9 K样本,评估在训练中 “见过” 的场景。
- 域外评估:4.1K 样本,评估 LMM 在新场景中的泛化能力。
当前其他多图像评估基准包括 Muir-Bench [54] 和 ReMI [21]。

3. 交错多图像任务与数据
3.1 任务概览
我们观察到,不同的计算机视觉场景通常可以用交错的多图像格式进行统一表示,例如视频、3D和单图像数据。因此,为了赋予 LLaVA-Interleave 多样化的能力,如图 2 所示,我们采用交错多图像格式统一以下四类任务的数据输入:
多图像场景。包括视觉指令,这些指令结合了交错的视觉-语言输入与多张图像。此设置涵盖了训练数据中的 12 个具有挑战性的真实世界任务,例如找茬、视觉故事讲述、图像编辑指令生成、交错多图像对话、多图像拼图、低级多图像评估等。
多帧场景。将视频作为输入数据,并将其采样为多个帧,以保留多图像序列中的时间视觉线索。我们主要关注 2 个任务:视频详细描述生成和视频 VQA(视觉问答)。
多视角场景。通过从不同视角获取的多视角图像描绘 3D 环境,其中视觉对应性和视差可以指示 3D 世界中的空间信息。对于 3D 感知,我们包括 2 个任务:embodied VQA(对话与规划)和 3D 场景 VQA(描述生成与定位)。
多区域场景。表示传统的单图像任务。在 LLaVA-NeXT [36] 设计的 “任意分辨率” 功能下,我们将高分辨率图像划分为多个低分辨率区域,以实现高效的视觉编码,并与我们的交错多图像格式兼容。
3.2 M4-Instruct
为了赋予全面的多图像能力,我们精心编制了一个综合训练数据集,命名为 M4-Instruct,包括 117.76 万条实例,广泛覆盖多图像、多帧和多视角场景的 14 项任务及 41 个数据集,并结合多区域数据以保留基础单图像性能。图 3 展示了前三类场景的任务示例,图 4 提供了 M4-Instruct 的数据概览,详细的数据统计见表 15。

多图像数据。大部分数据集来自以往公开研究成果,并经过严格转换为我们的统一格式,配以任务特定指令,其中部分灵感来自 DEMON [27] 和 Mantis [19]。此外,我们利用 GPT-4V [43] 为 3 个新任务注释数据,以实现更广泛的能力,包括真实差异、合成差异和推文任务。
视频数据。我们从 LLaVA-Hound [63] 中收集了 25.5 万条数据子集,其中包含 24 万条视频 VQA 和 1.5 万条视频详细描述。同时,加入了 NExT-QA [57] 和 STAR [55] 数据集,进一步扩展视频训练数据。
3D数据。我们广泛收集了来自 nuScenes QA [6]、ALFRED [48]、ScanQA [3] 和 3D-LLM [16] 的数据,覆盖了室外和室内场景。
单图像数据。我们从 LLaVA-NeXT [24] 的阶段 2 微调数据中随机抽取了 40%,以保留单图像处理能力。
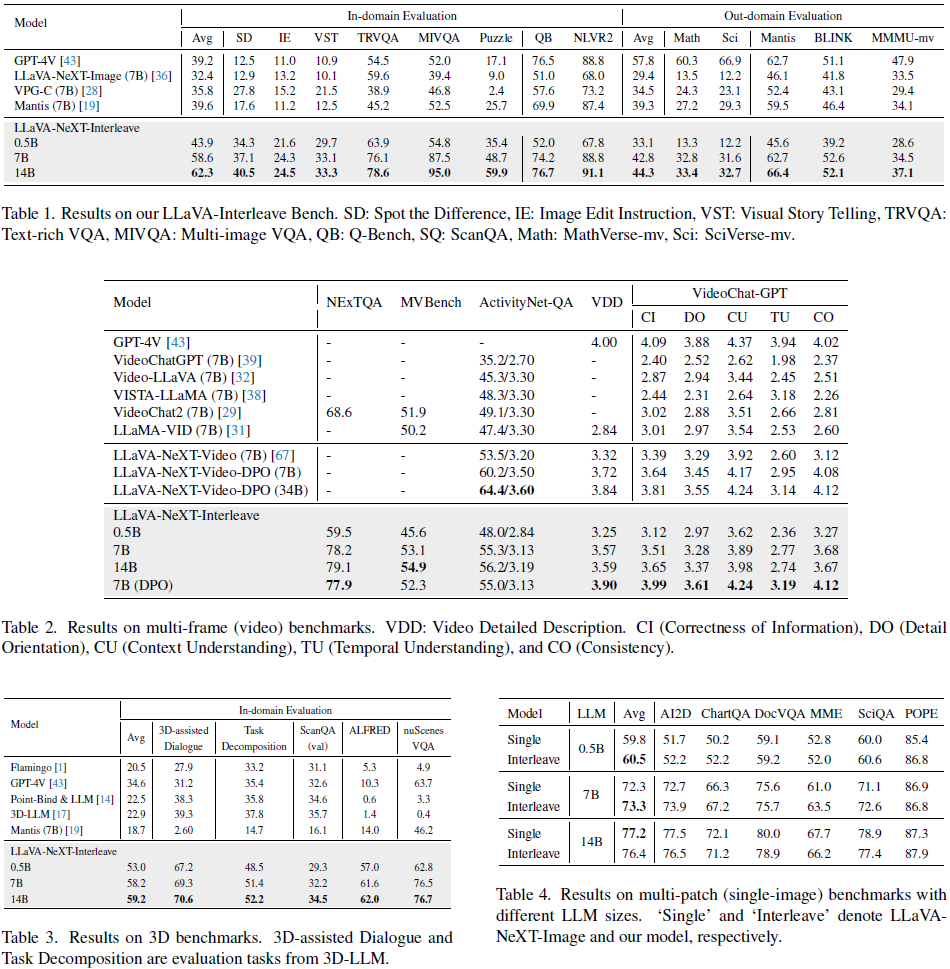
为了全面评估交错多图像性能,我们提出了 LLaVA-Interleave Bench,包括 13 项具有挑战性的任务,总计 1.7 万条实例。图 3 展示了基准测试的数据概览,详细的数据统计见表 16。具体而言,我们将多图像任务分为两类:
-
域内评估。包含训练中 “见过” 的任务,旨在验证模型在熟悉场景中的性能。我们采用 5 项新策划的多图像任务对应训练数据集,以及 2 个现有基准测试(QBench [56] 和 NLVR2 [50]),共计 12,900 条实例。
-
域外评估。涉及训练场景中未出现的任务,旨在揭示 LMM 的泛化能力。我们为多图像数学(MathVerse [65])和科学(SciVerse [13])理解构建了 2 项新任务,并利用 3 个现有基准(Mantis-Eval [19]、BLINK [10] 和 MMMU [60]),共计 4,100 条实例。
4. 交错视觉指令微调
在本节中,我们介绍 LLaVA-NeXT-Interleave 进行交错视觉指令微调的几项关键技术。对于架构设计,我们遵循 LLaVA-NeXT [24] 的通用框架,包括:视觉编码器 [62],中间投影器,强大的 LLM [4]。在此基础上,我们采用以下三项技术来提升多图像任务的性能:
技术 1:从单图像模型继续训练。交错多图像任务可视为单图像场景的扩展,其格式更加灵活且推理更具挑战性。因此,为更好地利用预训练的单图像能力,我们以现成的 LLaVA-NeXT-image [24] 模型作为基础模型。该模型已经历了两个阶段的训练:
- 第一阶段:图像-文本描述的预训练
- 第二阶段:单图像微调
在此基础上,我们利用 M4-Instruct 数据集进行交错多图像指令微调。
技术2:训练中混合交错数据格式。在交错多图像训练中,我们采用两种格式来安排图像 token 的位置:
- 前置格式:将所有图像 token 放置在提示的前部,同时在文本中保留占位符 〈image〉。
- 交错格式:将图像 token 保留在其原始位置,即 〈image〉 的位置。
通过这种方式,LLaVA-NeXT-Interleave 支持更灵活的推理模式,对不同的输入格式表现出更强的鲁棒性。
技术 3:结合不同数据场景提升单任务性能。大多数现有研究仅使用单一数据源进行监督微调,例如 Mantis [19] 的多图像微调和 LLaMA-VID [31] 的多帧微调。相较之下,我们利用 M4-Instruct 同时进行四种不同任务(多图像、多帧、多视角、多区域)的指令微调。在统一的交错格式下,不同的数据场景可以提供互补的语义信息和指令遵循能力,从而提升模型在单一任务中的表现。
5. 实验

6. 新兴能力
本节通过示例展示我们模型的一些新兴能力。新兴能力指模型在推理过程中表现出的、训练时未明确训练过的能力。我们主要从以下三个方面展示:
从单图像到多图像的任务迁移:在单图像模型中,具备理解单图像并指出有趣部分的能力 [35]。此能力未包含在我们的多图像训练中。如表 8 所示,模型能够分析多张图像中的有趣部分。这种新任务可能是由单图像能力与多图像 VQA 训练相结合而涌现的。

从图像到视频的任务迁移:在 M4-Instruct 训练中,仅包含多图像推文生成任务。模型能够直接从视频生成推文,如表 9 所示。这种新任务可能由多图像推文生成和视频 VQA 任务的数据共同作用涌现。

实际应用场景:如表 10、11 和 12 所示,模型在三种未明确训练过的实际场景中表现出色:多图像绘画风格识别,PPT 摘要与问答,多文档 VQA。这些例子表明模型具有广泛实际应用的潜力,展现了卓越的泛化能力。



7. 结论
总之,我们的研究重点是展示 LLaVA-NeXT-Interleave 在统一和增强大型多模态模型(LMMs)多种视觉任务能力方面的变革性潜力:
- 整合多场景:通过利用交错数据格式,有效融合多图像、视频、3D以及单图像场景,提供处理多样挑战的统一方法。
- 全面数据与基准:引入的 M4-Instruct 数据集和 LLaVA-Interleave Bench 为 LMM 的训练和评估提供了坚实基础,确保在多个领域表现出高性能。
- 实验验证:大规模实验表明,LLaVA-NeXT-Interleave 不仅在多图像任务中设立了新的业界标杆,同时在单图像任务中也保持了卓越表现。
- 新兴能力:模型表现出跨任务迁移等令人振奋的能力,展现了更广泛应用的潜力。
这项工作为多模态人工智能和复杂视觉理解任务的未来发展开辟了新道路,树立了新的行业标准。
论文地址:https://arxiv.org/abs/2407.07895
项目页面:https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/
进 Q 交流群:922230617

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









