







Baichuan-M1: Pushing the Medical Capability of Large Language Models
目录
1. 引言
近年来,LLM 的快速发展在自然语言理解、机器翻译、文本生成等领域取得了显著成果。然而,现有的通用 LLM 在医学等垂直领域的应用仍面临挑战,主要由于医学知识的复杂性和高质量医学数据的稀缺性。医学语言的精确性、术语的多样性以及隐私法规的限制,导致传统 LLM 在医学领域的表现受限。
为了解决这些问题,本文提出 Baichuan-M1。
- 该系列模型专为医学领域优化,旨在提升大语言模型(LLM)的医学能力。
- 与仅在通用模型基础上微调的传统方法不同,Baichuan-M1 从零开始训练,专注于医学知识的深度学习。
- 该模型使用 20T tokens 进行训练,并采用多种有效的训练策略,以平衡通用能力和医学专业性。
- 此外,Baichuan-M1 采用改进的 Transformer 架构,并通过渐进式训练提升模型性能。
结果显示,Baichuan-M1 在通用领域(如数学和编程)和医学领域都表现出色。
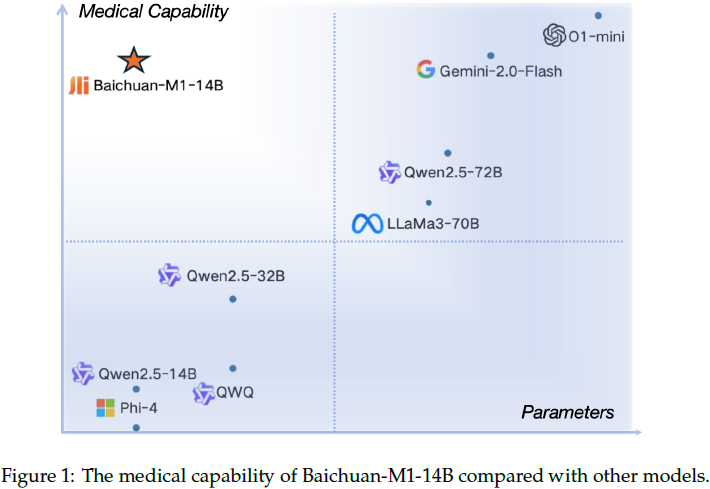
2. 数据
2.1 通用数据
数据总量:20 万亿 tokens,涵盖英文(12T)、中文(4T)、多语言(2T)和代码(2T)。

数据处理策略:
1)全局去重与上采样:减少数据冗余,提升数据质量。
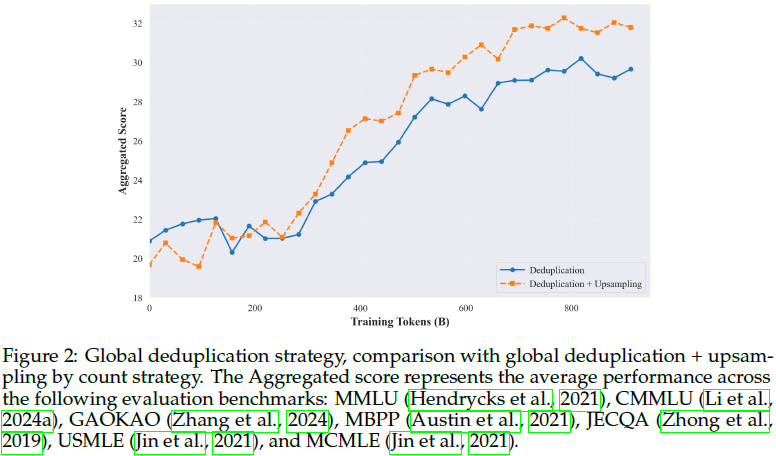
2)多维度数据质量评估:使用小模型对数据进行因果性、教育性、推理密度和知识密度等评估,并通过消融实验确定最优上采样策略。
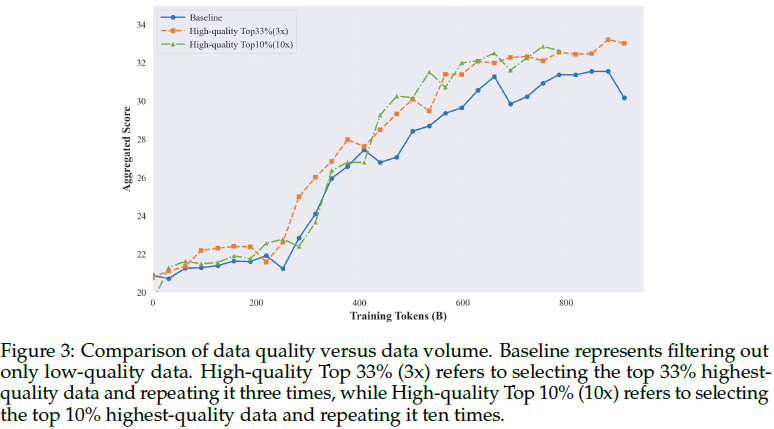
3)数据分类与比例优化
- 为了确保数据集平衡且信息丰富,我们对网络规模数据中代表性过高的(overrepresented)领域(如娱乐、电子商务、新闻和社交媒体)进行了下采样,同时对代表性不足的(underrepresented)领域(如科学、技术、工程和数学)进行了上采样,这些领域包含高质量的信息。
- 此外,我们使用一系列小模型进行大规模数据比率实验,以适应最佳数据比率策略,从而最大限度地提高模型在各个领域的性能。
4)合成数据
- 利用现有模型生成高质量的推理和问题解决数据,特别是在数学和编程领域。
- 为了确保高质量,我们使用在语言模型上训练的通用奖励模型进行严格过滤。
- 在模型退火阶段使用合成数据来进一步完善性能。
5)数据拼接优化:优化连接方案,以尽量减少不必要的长序列截断,从而持数据完整性,在训练时提高模型长上下文理解能力。
2.2 医学数据
数据来源:
- 网页数据:通过小模型分类与筛选,提取医学相关内容。
- 专家精选数据:涵盖医学学术论文、真实病例、医学教材、生物医学知识图谱、临床指南、医学百科等,共计 1T tokens。
- 数据质量过滤:开发医学质量评分与医学价值评分体系,确保数据的准确性和权威性。
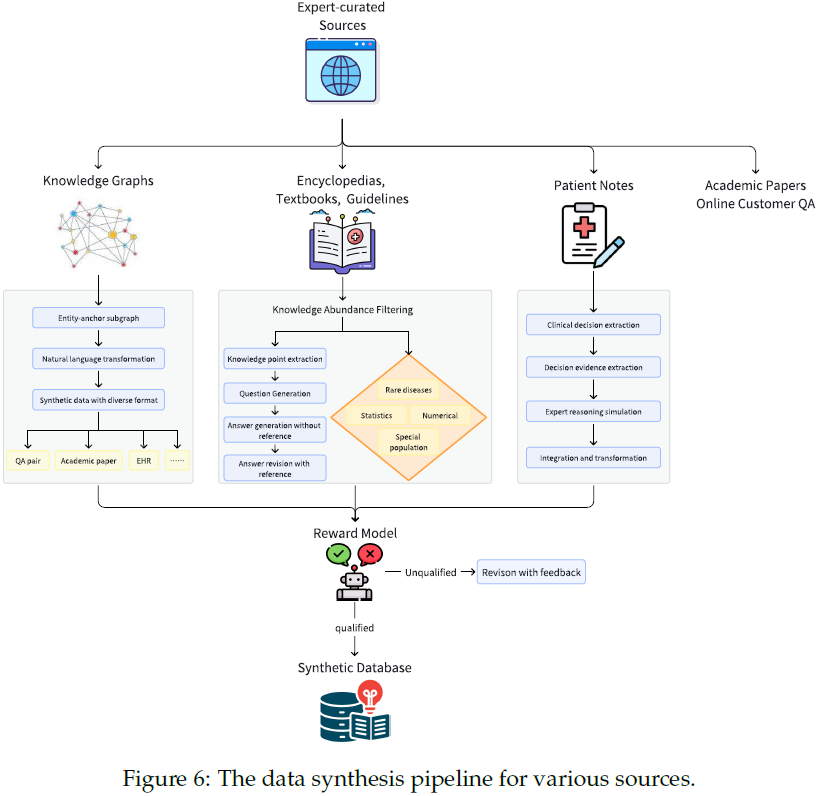
合成医学数据:针对不同数据源设计专用的合成管道(pipeline),例如:
1)百科/教材/指南:生成问答对,强调 Chain-of-Thought(CoT)推理。
- 将长文档拆分为较短的块(chunks),并执行一轮额外的过滤,重点是 “知识丰富度”。此步骤利用语言模型来消除未展示特定医学知识点的块
- 知识点提取:模型从文档中提取医学知识点(科学事实)。
- 问题生成:对于每个知识点,模型都会生成一个考试问题,可以是多项选择题或简答题。
- 无参考答案生成:对于每个生成的问题,模型都会提供答案而无需参考原始文档,重点是生成长思路 (CoT) 推理。此步骤保留了 LLM 的输出模式和完整的 CoT 结构,促进了学生模型的学习。
- 基于参考的答案修改:由于最初生成的答案可能不正确,我们进行了一个修改步骤,模型根据原始文档修改其答案。
2)真实病例:重构医生的推理过程,包括诊断、治疗和预后(prognosis)分析。
- 临床决策提取:该模型识别患者整个旅程中做出的关键临床决策,从初步诊断到预后预测。
- 决策证据提取:对于每个临床决策,该模型提取所有相关证据,包括支持该决策的正面和负面表现。
- 专家推理模拟:利用提取的证据,该模型模拟医学专家的推理过程,特别强调评估替代方案,例如鉴别诊断和治疗方案。
- 集成和转换:该模型集成上述组件,将原始笔记(特别是证据)转换为合适的格式,并编织出一个反映医学专家完整思维过程的综合推理过程。
3)知识图谱:将知识图谱中每一个实体(entity)的相关知识转换为自然语言
- 我们鼓励模型通过将实体锚定为答案而不是将其包含在问题中来生成反向推理问题。例如,对于疾病实体,我们鼓励提出诸如“以下哪种疾病可能导致......的症状?”之类的问题,而不是“......疾病的典型症状是什么?”
- 知识图谱中丰富的关系通常会聚集需要仔细区分的相似实体。因此,我们利用这些相似的实体作为多项选择题的选项,并生成关注它们之间细微差异的问题,例如“以下哪种维生素仅由动物来源提供?”
4)学术论文:提取证据和结论,生成推理路径。
5)在线问答:标准化用户提问并生成详细回答。
3. 模型架构
Baichuan-M1 的架构基于 Llama 等模型,进行了针对性改进:
核心组件:
- 使用基于 rmsnorm 的 pre-norm 层。
- FFN 层采用 SwishGlu 激活函数。
- 旋转位置编码(RoPE)基础值设为 1e6,以适应 32K 上下文长度。
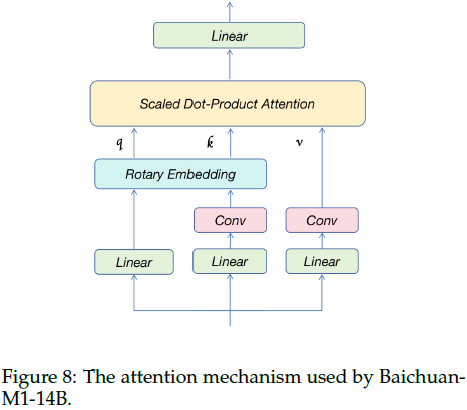
注意力机制改进:
- 交替使用全局注意力和滑动窗口注意力以降低推理成本。
- 增加全局注意力头的维度(从 128 提高到 256),提升长距离检索能力。
- 在注意力模块的 key 和 value 上应用时间短卷积操作,增强 in-context 学习能力。
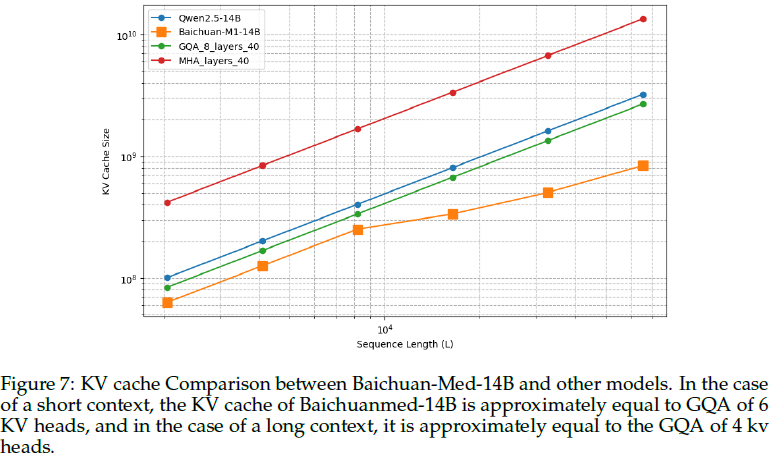
KV 缓存优化:
- 为了节省 KV 缓存,提高推理效率,我们还交替使用滑动窗口注意力机制。
- 全局注意力层有2个头,头维度为256,而滑动窗口注意力层有8个头,头维度为128。
- 采用这种交错结构的一个重要原因是,大型语言模型具有大量的层冗余,而具有长期检索能力的头数量相对较少。
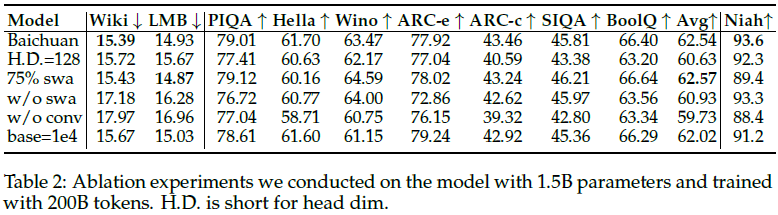
从表 2 可以看出,
- 全局注意力与滑动窗口注意力(sliding window attention,swa)混合使用不会显著影响长上下文基准的性能,但可以提高短上下文基准的性能。
- 这表明混合模型可能具有更好的性能,这与一些先前的研究一致。
4. 训练过程
4.1 Tokenizer
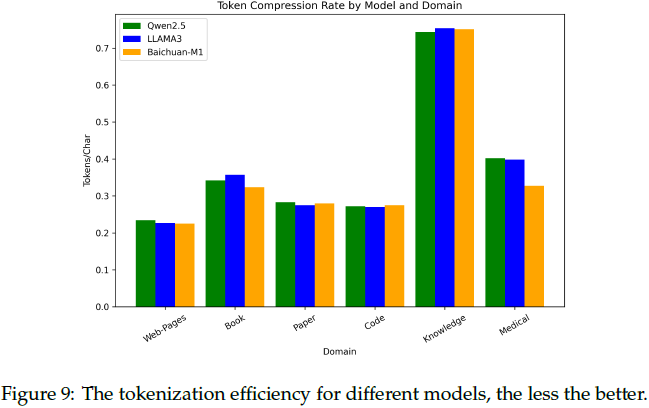
采用通用和医学领域双重词表构建策略,词表大小为 133,120。
结合通用语料和医学术语,优化了医学领域的分词(tokenization)效率。
4.2 训练细节
阶段性训练:
- 第一阶段:使用低难度、高质量数据进行预训练,以稳定模型初始性能。
- 第二阶段:逐步引入更复杂的数据,增加医学数据占比。
- 第三阶段(退火阶段):强化模型的医学专业能力,并提高对复杂应用场景的适应性。
优化器与超参数:
- 使用 AdamW 优化器(β1=0.9, β2=0.95, weight decay=0.1)。
- 学习率策略:warm-up(2000 步)-稳定-余弦退火(从 4e-4 降至 2e-5)。
- 总训练 tokens:20T(包括 2T 的退火阶段)。
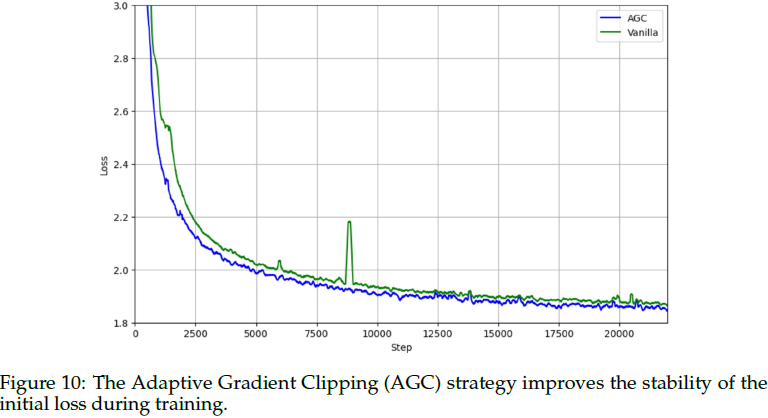
梯度截断策略:
- 采用自适应梯度截断(AGC)方法,提高早期训练的稳定性。
- 动机在于,在训练过程中,有时梯度大是由于当前参数在参数空间中达到陡峭点,有时是由于特殊数据导致的,我们希望消除后者的影响。

5. 对齐策略
5.1 监督微调(SFT)
数据构建:
- 通用数据:涵盖常规任务(如数学、编程)以保持通用能力。
- 医学数据:细分为五大类(医学知识,医学语言理解,医学推理,医学长文档处理,医学安全性)以覆盖多样的临床医学场景
答案质量:
- 数据增强:依靠现实世界的患者案例,例如 MIMIC 和 PMC-Patient,作为主要数据源,以生成具有足够难度、现实世界复杂性和覆盖所有临床场景的问题。
- 候选答案生成:将每个标签的安全原则与高级 LLM 相结合,为每个提示生成多个候选答案。
- 人工专家验证:领域专家审查和完善候选答案,以确保它们符合安全性和准确性标准,并保留关键的医疗背景。
训练策略:
- 五轮微调,采用余弦衰减学习率(起始值 2e-5)。
- 当将多个样本打包成单个训练序列时,使用 “样本掩码(sample masking)” 策略确保不同样本间的独立性。
5.2 强化学习(RLHF)
奖励模型(RM):
- 基于规则的 RM:用于可验证问题(如医学诊断、编程题)。
- 基于模型的 RM:自 Baichuan-M1 的一个检查点,通过偏好数据集训练,用于处理复杂推理问题
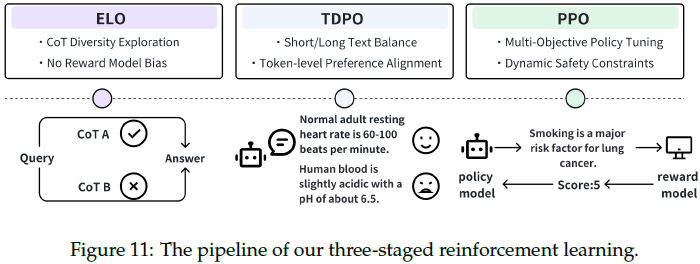
三阶段强化学习流程:
- ELO(Exploratory Log-likelihood Optimization):直接优化生成连贯、合乎逻辑的推理路径的可能性,从而生成多样化、高质量的思路链 (CoT) 推理路径。
- TDPO(Token-Level Direct Preference Optimization):在 token 级别上进行偏好优化,解决传统 DPO 的长度依赖问题。
- PPO(Proximal Policy Optimization):最终微调模型的生成策略,结合 RM 反馈优化性能。
6. 评估
6.1 基准测试
Baichuan-M1-14B-Instruct 在多个公开和私有医学基准上进行了评估,涵盖三个层级:
- 医学基础知识:MedNLI、MedCalc、MMLU 等。
- 医学考试:USMLE、CMExam、MediQ、MedBullets、Pubmedqa 等。
- 医学实践:CMBClin、ClinicalBench、RareArena、NEJMQA 等。
6.2 结果对比
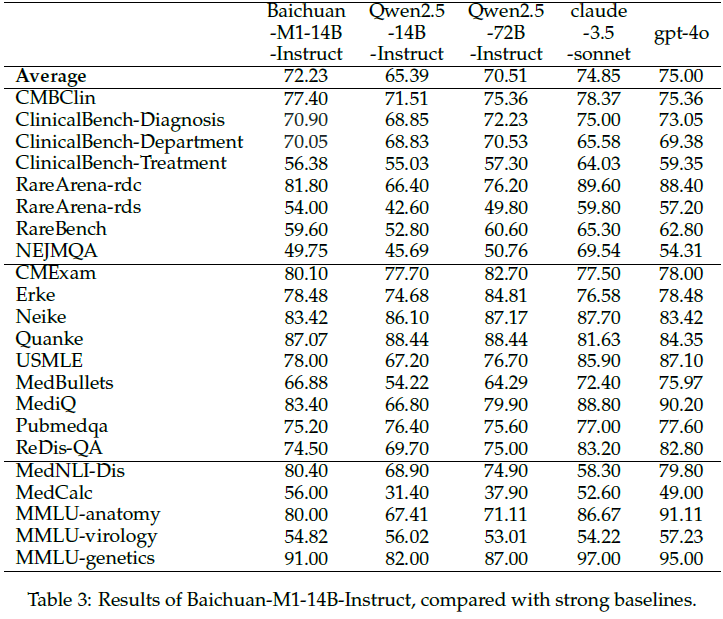
Baichuan-M1-14B-Instruct 在医学相关基准测试中超过 Qwen2.5-72B-Instruct,并与 GPT-4o、Claude-3.5-sonnet 等闭源模型差距缩小。
在 RareArena(罕见病诊断)等复杂任务中,Baichuan-M1 表现出色。

在编程(MBPP、HumanEval)和数学(MATH、CMATH)基准上的表现与同类模型持平或更优。
7. 讨论与结论
7.1 继续预训练 vs. 从零开始训练
实验表明,简单地在通用模型上继续训练难以显著提升医学能力,反而可能损害通用性能。
从零开始训练,专注于医学领域,可以更有效地掌握复杂的医学知识。
7.2 结论与未来工作
Baichuan-M1 是医学领域 LLM 的重要突破,在诊断支持、医学研究和治疗建议等方面展现出强大能力。
未来的工作将致力于提升模型在稀有病诊断、实际临床咨询等方面的表现,同时探索更高效的训练方法和数据利用策略。
论文地址:https://arxiv.org/abs/2502.12671
项目页面:https://github.com/baichuan-inc/Baichuan-M1-14B
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









