






二进制编码
程序 = 算法 + 数据结构
算法-各种计算机指令,数据结构-二进制数据
字符串表示
ASCII码:8位二进制
Unicode
定点数:没办法同时表示很大的数字和很小的数字
浮点数(Floating Point)

数字电路
门电路:创建 CPU 和内存的基本逻辑单元
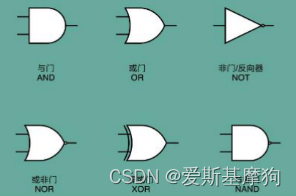
半加器(Half Adder): 异或门计算个位,与门计算是否进位
解决个位的加法问题
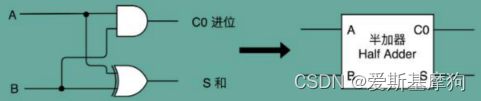
两个半加器和一个或门,组合成一个全加器
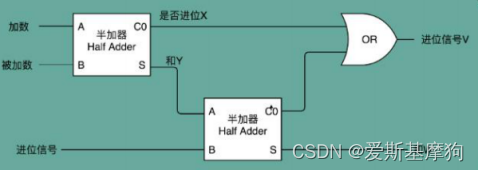
8 位加法器
乘法:加法+位移
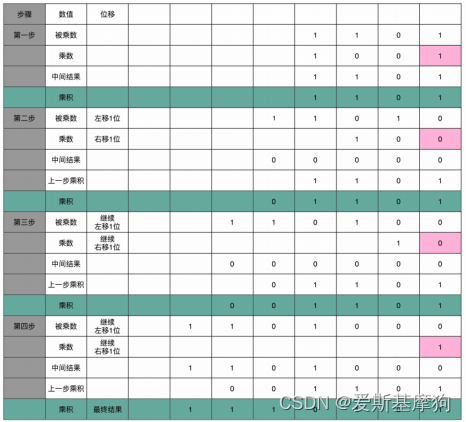
并行加速方法:把 O(N) 的时间复杂度,降低到 O(logN),N为乘法位数
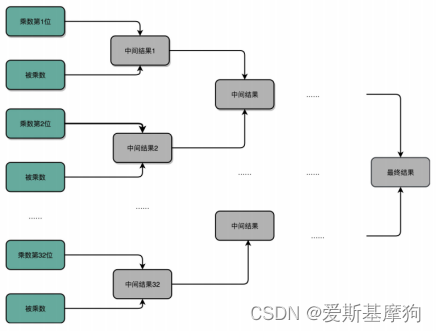
门延迟(Gate Delay):以全加器为例,每一个全加器都要等待上一个全加器把对应的输入结果算出来,才能算下一位输出,位数越多,等待时间越长
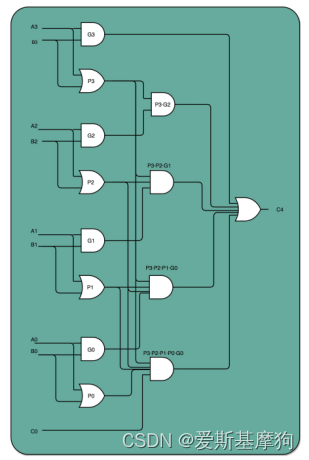
超前进位加法器:通过复杂电路解决延迟问题
处理器设计
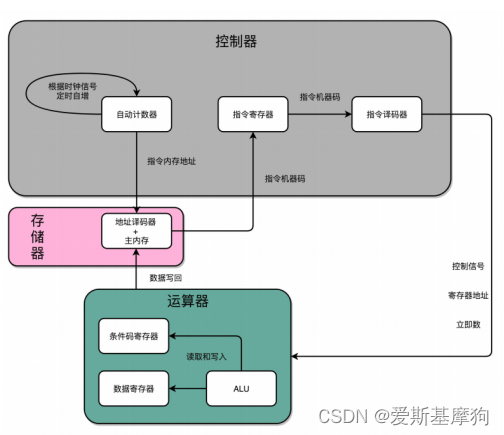
建立数据通路:指令+运算=CPU
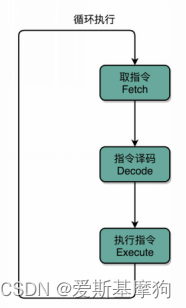
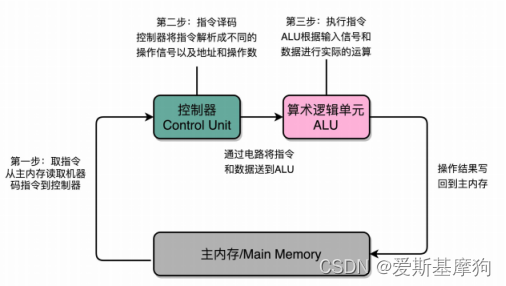
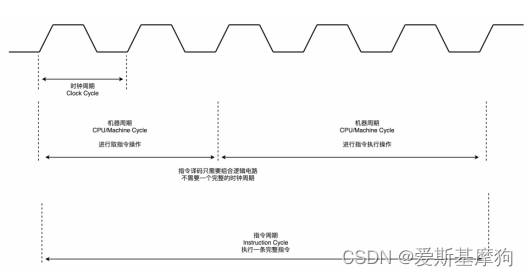
指令周期(Instruction Cycle)
1.Fetch取指令:从 PC 寄存器里找到对应的指令地址,根据指令地址从内存里把具体的指令加载到指令寄存器中,然后PC寄存器自增
2.Decode 指令译码
3.Execute 执行指令
4.重复1~3
控制器(Control Unit)通过 PC 寄存器和指令寄存器取出指令
算术逻辑单元(ALU)执行指令,简单的无条件地址跳转可以直接在控制器里面完成
Instruction Cycle
Machine Cycle,机器周期或者 CPU 周期:从内存里面读取一条指令的最短时间
Clock Cycle,时钟周期,机器的主频
数据通路-处理器单元
组合逻辑元件(Combinational Element):在特定输入下产生特定输出
存储元件:状态元件(State Element)
通过数据总线连接,完成数据的存储、处理和传输
CPU 所需要的硬件电路
1.ALU
2.能够进行状态读写的电路元件-寄存器,存储计算结果,
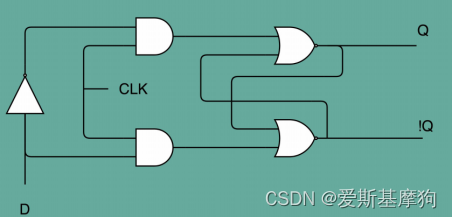
D触发器(Data/Delay Flip-flop)
3.自动的电路,按照固定的周期,不停地实现 PC 寄存器自增,自动地去执
行“Fetch - Decode - Execute“的步骤
4.译码电路
时序逻辑电路(Sequential Logic Circuit)
1.自动运行问题
2.存储问题
3.各个功能按照时序协调问题
时钟信号硬件实现
CPU主频-晶体振荡器
反馈电路(Feedback Circuit) 反相器(Inverter)
通过 D 触发器实现存储功能
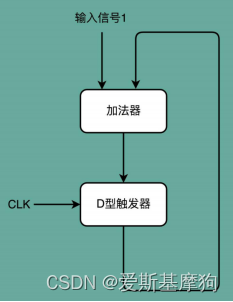
PC寄存器:时钟信号+D触发器+加法器
每过一个时钟周期,固定自增1
译码器:读写数据
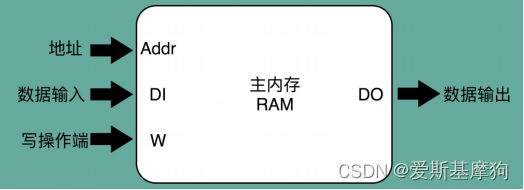
1.自动计数器会随着时钟主频不断地自增,来作为 PC寄存器
2.自动计数器后连上一个译码器,译码器连着大量的 D 触发器组成的内存
3.自动计数器随时钟主频不断自增,从译码器当中,找到对应的计数器所表示的内存地址,读取出里面的 CPU 指令
4.读取出的 CPU 指令写入指令寄存器中
5.指令寄存器后跟一译码器,把拿到的指令解析成 opcode 和对应的操作数
6.输出线路连接 ALU,开始进行各种算术和逻辑运算,对应的计算结果,会再写回到 D 触发器组成的寄存器或者内存当中
面向流水线的指令设计
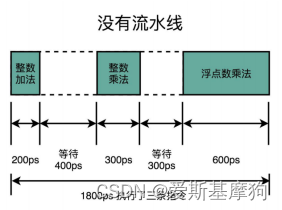
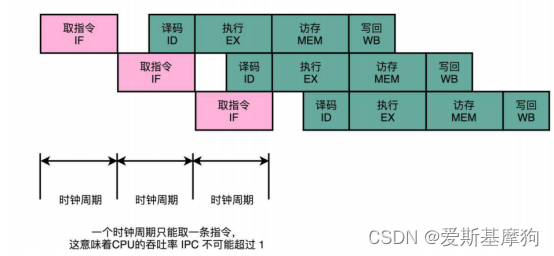
一整条指令的执行,在一个时钟周期内完成,CPI = 1,单指令周期处理器(Single Cycle Processor)
随着门电路层数的增加,由于门延迟的存在,位数多、计算复杂的指令需要的执行时间就越长-时钟周期和执行时间最长的那个指令设成一样的

时钟频率没法太高,太高的话,有些复杂指令没有办法在一个时钟周期内完成
指令流水线(Instruction Pipeline)技术
不用把时钟周期设置成整条指令执行的时间,而是拆分成完成一个一个小步骤需要的时间。
把一个指令拆分成“取指令- 指令译码 - 执行指令”三部分,三级的流水线,把“执行指令”拆分成“ALU 计算(指令执行) - 内存访问 - 数据写回”,五级流水线
提升CPU吞吐率
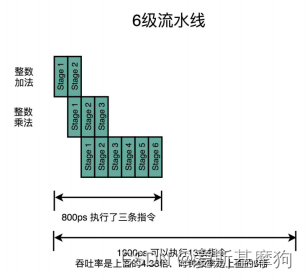
每一级流水线对应的输出,都要放到流水线寄存器(Pipeline Register)里面,每增加一级的流水线,就要多一级写入到流水线寄存器的操作
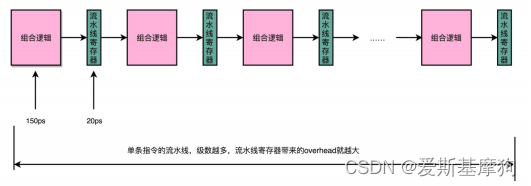
单纯增加流水线级数,不仅不能增加性能,反而会有更多的 overhead 的开销
冒险(Hazard)
IPC(Instruction Per Cycle)衡量 CPU 执行指令的效率
结构冒险(Structural Hazard):访问内存数据和取指令可能会用到同样的硬件电路,硬件层面的资源竞争
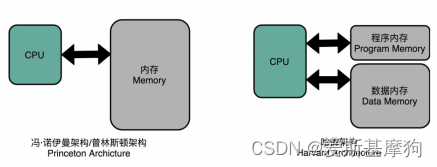
哈佛架构(Harvard Architecture):内存分成两部分,存放指令的程序内存和存放数据的数据内存,各有各的地址译码器
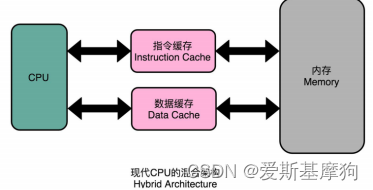
把高速缓存分成指令缓存(Instruction Cache)和数据缓存(Data Cache)
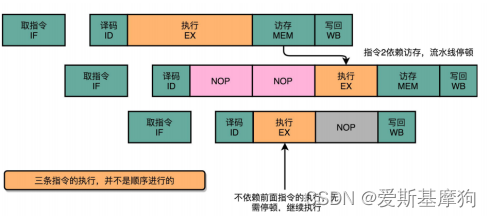
数据冒险(Data Hazard):指令 2依赖指令 1 的计算结果,不能在指令1的第一个stage执行完成后进行
乱序执行,把没有依赖关系的指令放到前面来执行
数据依赖:
先写后读(Read After Write,RAW)
int main() {
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + 2;
12: 83 45 fc 02 add DWORD PTR [rbp-0x4],0x2
b = a + 3;
16: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
19: 83 c0 03 add eax,0x3
1c: 89 45 f8 mov DWORD PTR [rbp-0x8],eax
}
1f: 5d pop rbp
20: c3 ret
内存地址为12的机器码把 0x2 添加到 rbp-0x4 对应的内存地址里,内存地址为 16 的机器码要从 rbp-0x4 内存地址里把数据写入到 eax 寄存器里,需要保证在内存地址为 16 的指令读取 rbp-0x4 里面的值之前,内存地址 12 的指令写入到 rbp-0x4 的操作必须完成
先读后写(Write After Read,WAR)
int main() {
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = b + a;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
b = a + b;
18: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
1b: 01 45 f8 add DWORD PTR [rbp-0x8],eax
}
1e: 5d pop rbp
1f: c3 ret
在内存地址为 15 的汇编指令里要把 eax寄存器里面的值读出来,再加到 rbp-0x4 的内存地址里,在内存地址为 18 的汇编指令里,要再写入更新 eax 寄存器里面。
写后再写(Write After Write,WAW)
int main() {
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
a = 2;
b: c7 45 fc 02 00 00 00 mov DWORD PTR [rbp-0x4],0x2
}
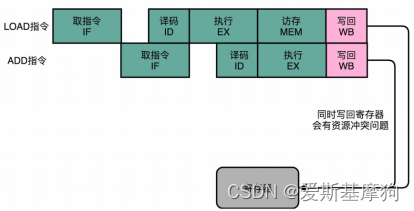
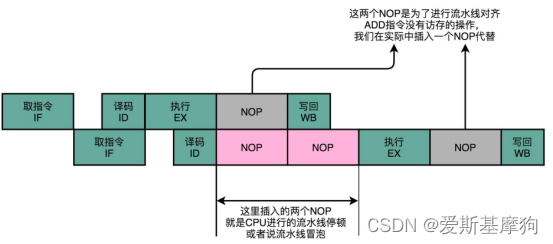
流水线停顿(Pipeline Stall)流水线冒泡(Pipeline Bubbling)
在进行指令译码的时候,会拿到对应指令所需要访问的寄存器和内存地址,能够判断出这个指令是否会触发数据冒险。如果会触发数据冒险,可以决定让整个流水线停顿一个或者多个周期
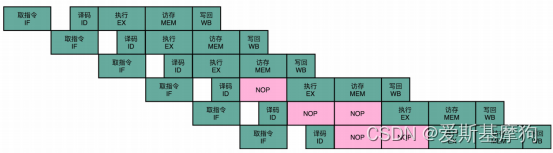
插入 NOP 这样的无效指令,等待之前的指令完成
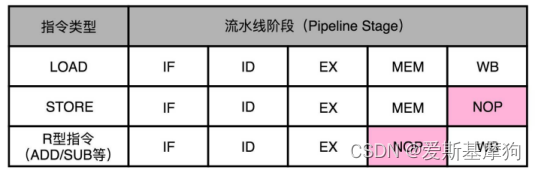
NOP 操作和指令对齐
取指令(IF)- 指令译码(ID)- 指令执行(EX)- 内存访问(MEM)- 数据写回(WB),有些指令没有对应的流水线阶段,运行一次 NOP 操作
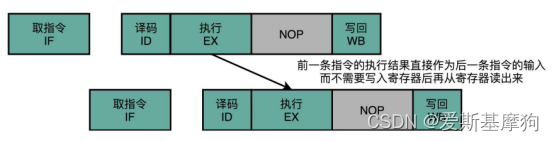
操作数前推(Operand Forwarding)操作数旁路(Operand Bypassing):通过在硬件层面制造一条旁路,让一条指令的计算结果,可以直接传输给下一条指令,而不再需要“指令 1 写回寄存器,指令 2 再读取寄存器“多此一举的操作
乱序执行(Out-of-Order Execution,OoOE):后面的指令不依赖前面的指令,就不用等待前面的指令执行,完全可以先执行
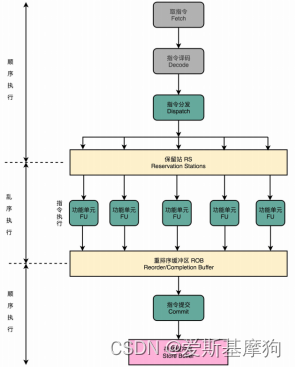
1.在取指令和指令译码的时候, CPU一级一级顺序地进行取指令和指令译码的工作
2.在指令译码完成之后,CPU进行一次指令分发,把指令发到一个叫作保留站(Reservation Stations)的地方。
3.指令等待它们所依赖的数据,传递给它们之后才会执行
4.指令就可以交到功能单元(Function Unit,FU),其实就是ALU,去执行
5.结果存放到重排序缓冲区(Re-Order Buffer,ROB)
6.CPU按照取指令的顺序,对指令计算结果重新排序
7.实际的指令的计算结果数据先写入存储缓冲区(Store Buffer),最终才会写入到高速缓存和内存里
遇到if…else条件分支或for/while循环,顺序执行假设就会不成立
控制冒险(Control Hazard):为了确保能取到正确的指令,而不得不进行等待延迟
条件跳转指令
1.条件比较
2.实际的跳转:指令译码(ID)的阶段进行
缩短分支延迟:在 CPU 里面设计对应的旁路,在指令译码阶段,就提供对应的判断比较的电路
分支预测(Branch Prediction):条件跳转后执行的指令,应该是哪一条
条件跳转一定不发生
预测正确:节省下来本来需要停顿下来等待的时间
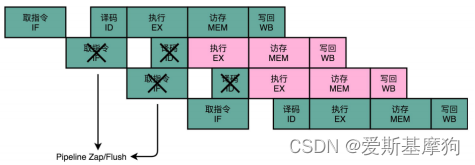
预测失败:把后面已经取出指令已经执行的部分给丢弃掉,Zap 或Flush
CPU 需要提供对应的丢弃指令的功能,通过控制信号清除掉已经在流水线中执行的指令
动态分支预测
用前一天的是不是下雨,直接来预测后一天会不会下雨,叫一级分支预测(One Level Branch Prediction),或者叫 1 比特饱和计数(1-bit saturating counter)
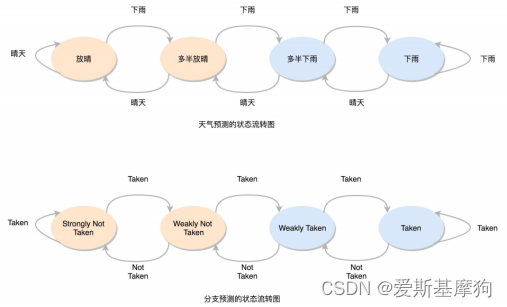
状态机(State Machine):4 个状态,需要 2 个比特来记录对应的状态,2 比特饱和计数,双模态预测器(Bimodal Predictor)

多发射(Mulitple Issue)和超标量(Superscalar):一次性从内存里面取出多条指令,分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元去处理。在一个时钟周期里,能够完成的指令不只一条,IPC 也就能做到大于 1 了
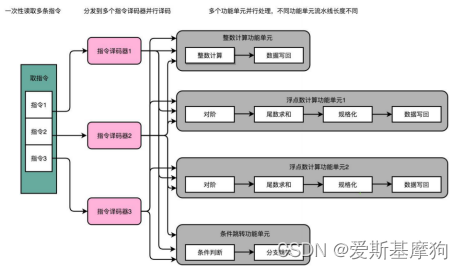
多发射(Mulitple Issue):同一个时间,可能会同时把多条指令发射(Issue)到不同的译码器或者后续处理的流水线中去
超标量(Superscalar):本来在一个时钟周期里面,只能执行一个标量(Scalar)的运算,在多发射的情况下,能够超越这个限制,同时进行多次计算,超标量的 CPU 里面,有很多条并行的流水线
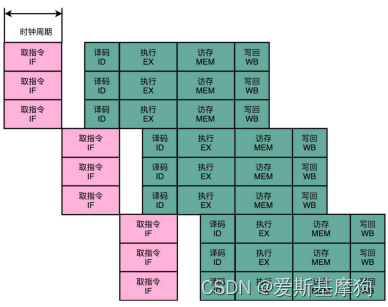
不同的功能单元的流水线长度不一样, 14 级流水线,指的通常是进行整数计算指令的流水线长度
超标量 CPU 的多发射功能,动态多发射处理器
超长指令字设计(Very Long Instruction Word,VLIW):让编译器来优化指令数,通过编译器,来优化 CPI
显式并发指令运算(Explicitly Parallel Instruction Computer)EPIC
在乱序执行和超标量的 CPU 架构里,指令的前后依赖关系,是由 CPU 内部的硬件电路来检测的,超长指令字的架构里面,这个工作交给了编译器
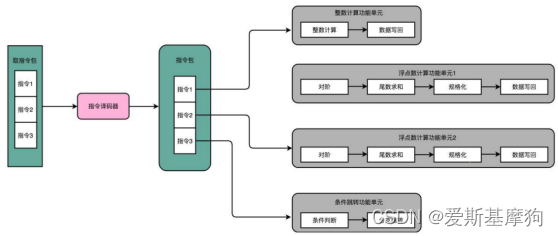
让编译器把没有依赖关系的代码位置进行交换,再把多条连续的指令打包成一个指令包
指令级并行(Instruction-level parallelism, IPL):过同一时间执行两条指令,来提升 CPU 的吞吐率
超线程(Hyper-Threading) 同时多线程(Simultaneous Multi-Threading,SMT)
在同一时间点上,一个物理的 CPU 核心只会运行一个线程的指令
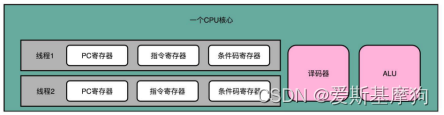
超线程的 CPU,是把一个物理层面 CPU 核心,“伪装”成两个逻辑层面的CPU 核心。这个 CPU,会在硬件层面增加很多电路,使得我们可以在一个 CPU 核心内部,维护两个不同线程的指令的状态信息














 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









