







⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计8501字,阅读大概需要3分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
根据伊利亚特文本预测翻译者
根据伊利亚特文本预测翻译者
实验描述
伊利亚特是荷马史诗的一部分,是重要的古希腊文学作品,也是整个西方的经典之一,因此流传于世并被翻译为多种语言和多个版本。本节实验中,我们将对英语版本的是三个翻译版本进行分类预测,根据文本内容,对翻译者进行预测。
实验环境
- Oracle Linux 7.4
- TensorFlow 2
- Python 3
实验目的
- 掌握如何使用tf.data.TextLineDataset读取数据
- 掌握如何使用TextVectorization将语句进行词向量化
- 掌握如何使用神经网络模型的建模、编译和训练
知识点
- 相对于text_dataset_from_directory读取数据,tf.data.TextLineDataset方法更灵活
- TextVectorization词向量化有多种输出方式,如binary、int等
- 文本需向量化后,转化为高维向量才能作为神经网络模型的输入
实验分析

任务实施过程
一、打开Jupyter,并新建python工程
1.桌面空白处右键,点击Konsole打开一个终端
切换至/experiment/jupyter目录
cd experiment/jupyter
2.启动Jupyter,root用户下运行需加’–allow-root’
jupyter notebook --ip=127.0.0.1 --allow-root
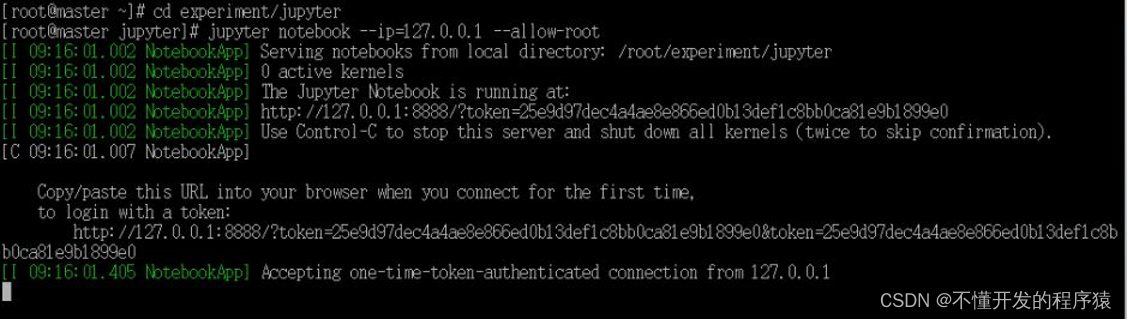
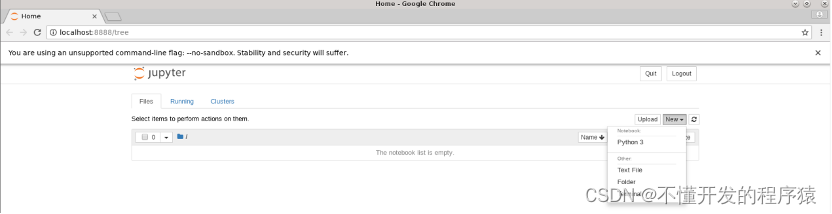
3.依次点击右上角的 New,Python 3新建python工程
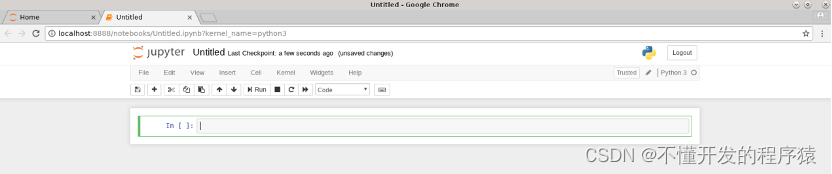
4.点击Untitled,在弹出框中修改标题名,点击Rename确认
二、读取数据并建模预测
- 加载工具,查看数据文件结构,初步了解数据内容
import collections
import pathlib
import re
import string
import tensorflow as tf
from tensorflow.keras import layers,losses,preprocessing,utils
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
import tensorflow_datasets as tfds
import tensorflow_text as tf_text
# 定义数据路径
data_path = '/root/experiment/datas/nlp/'
dataset_dir = pathlib.Path(data_path+'illiad')
# 查看数据路径下的文件结构
list(dataset_dir.iterdir())
# 自定义函数,将序号转化为整型
def labeler(example, index):
return example, tf.cast(index, tf.int64)
# 遍历三个翻译版本,将标签使用labeler函数转换为整型,并将文本和标签提取到列表labeled_data_sets
labeled_data_sets = []
FILE_NAMES = ['cowper.txt', 'derby.txt', 'butler.txt']
for i, file_name in enumerate(FILE_NAMES):
lines_dataset = tf.data.TextLineDataset(str(dataset_dir/file_name))
labeled_dataset = lines_dataset.map(lambda ex: labeler(ex, i))
labeled_data_sets.append(labeled_dataset)

# 接下来我们要将这些标记的数据集合并为一个数据集,并对其进行shuffle。
BUFFER_SIZE = 50000
BATCH 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











