






笔记学习自《精通python网络爬虫》
学习人:ZRX_GIS
爬虫的概念
什么是爬虫?
按照我们的需求进行网页访问
为什么学爬虫?
更多的转票子
爬虫架构
网络爬虫由控制节点、爬虫节点、资源库构成
爬虫类型
网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型
爬虫实现原理
不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性在此,我们将以两种典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。
通用爬虫
1 ) 获取初始的 URL 初始的 URL 地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2) 根据初始的 URL 爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应 URL 地址中的网页,爬取了对应的 URL 地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL 地址存放到一个URL 列表中,用于去重及判断爬取的进程。
3) 将新的 URL 放到 URL 队列中。在第 步中,获取了下一个新的 URL 地址之后,会将新的 URL 地址放到 URL 队列中。
4) URL 队列中读取新的 URL ,并依据新的 URL 爬取网页,同时从新网页中获取新URL ,并重复上述的爬取过程。
5 )满足爬虫系统设置的停止条件时,停止爬取 在编写爬虫的时候,一般会设置相应的停止条件 如果没有设置停止条件,爬虫则会一直爬取下去,一直到无法获取新的 URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
聚焦爬虫
1)对爬取目标的定义和描述
2)获取初始URL
3)根据初始的URL爬取网页,并获得新的URL。
4)从新的URL中过滤掉与爬取目标无关的连接。
5)将过滤后的链接放到URL队列中。
6)从URL队列中根据搜索算法,确定URL的优先级,并确定下一步要爬取的URL地址。
7)从下一步要爬取的URL地址中,都区新的URL,然后依据新的URL地址爬取网页,并重复上述爬取过程。
8)满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。
爬行策略
在网络爬虫爬取的过程,在待爬取的 URL 列表中,可能有很多 URL 地址,那么这些URL 地址,爬虫应该先爬取哪个,后爬取哪个呢?这是后便需要去考虑爬行的策略。
爬行策略主要有深度优先爬行策略、广度优先爬行策略、大站优先策略、反链策略等,以下图为例。
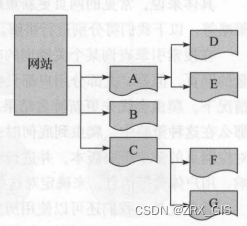
要爬取ABCDEFG全部,如果按照深度优先爬行策略去爬取,则此时会首先爬取一个网页,然后将这个网页的下层链接一次深入爬取完再返回上一层进行爬取,爬取顺序为ADEBCFG;如果按照广度优先,则爬行顺序变为ABCDEFG。除了以上两种爬行策略之外,我们还可以采用大站爬行策略 我们可以按对应网页所属的站点进行归类,如果某个网站的网页数量多,那么我们则将其称为大站,按照这种策略,网页数量越多的网站越大,然后,优先爬取大站中的网页 URL 地址。
网页更新策略
一个网站的更新对于爬虫来说是不利的,我们需要对这些网页进行重新爬取,那么怎么判断我们爬取的时机?常见的网页更新策略主要有3种:用户体验策略、历史数据策略、聚类分析策略等。
对于用户体验策略而言:在搜索引擎查询某一关键字的时候,会出现排名结果,在排名结果中,通常会有大量的网页,但是,大部分用户都只会关注排名靠前的网页,所以,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果靠前的网页。这种策略在实现上会保留对应网页的各个历史版本,并进行对应分析,依据这多个历史分析的内容更新、搜索质量印象概念股等信息来确定爬取周期。
对于历史数据策略而言:我们可以依据某一个网页的历史更新数据,通过泊松过程进行建模等手段,预测该网页下一次更新的时间,从而确定下一次对该网页爬取的时间,即确定更新周期。
但是上述两种方式都需要访问历史数据,这会增加访问压力,因此下面介绍一种聚类分析策略。在生活中,相信大家对分类已经非常熟悉,比如我们去商场,商场中的商品一般都分好类了,方便顾客去选购相应的商品,此时,商品分类的类别是固定的,是已经拟定好的。但是,假如商品的数量巨大,事先无法对其进行分类,或者说,根本不知道将会拥有哪些类别的商品,此时,我们应该如何解决将商品归类的问题呢?这时候我们可以用聚类的方式解决,依据商品之间的共性进行相应分析,将共性较多的商品聚为类,此时,商品聚集成的类的数目是不一定的,但是能保证的是,聚在一起的商品之间 定有某种共性,即依据"物以类聚"的思想去实现。在网页更新中我们也可以使用这种策略,具体操作如下所示。
1)首先,经过大量研究发现,网页可能具有不同的内容,但是一般而言,具体类似属性的网页,其更新频率类似。这是聚类分析算法运用在爬虫网页的更新上的一个前提指导思想。
2)我们可以首先对海量的网页进行聚类分析,在聚类后,会形成很多的类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。
3)聚类完后,我们可以对同一个聚类中的网页进行抽样,然后求该抽样结果的平均更新值,从而确定对每个类别的爬取频率
网页分析算法
在搜索引擎中,爬虫爬取对应的网页之后,会将网页存储到服务器的原始数据库中,之后,搜索引擎会对这些网页进行分析并确定各网页的重要性,即会影响用户检索的排名结果。搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法、基于网页内容的网页分析算法。
1)基于用户行为的分析算法:该算法会根据用户对这些网页的访问行为,对这些网页进行评价,比如,依据用户对该网页的访问频率、用户对网页的访问时长、用户的单击频率等信息对网页进行综合评价。
2)基于网络拓扑的网页分析算法:该算法是依靠网页的链接关系、结构关系、已知网页或数据等对网页进行分析的一种算法,所谓拓扑,简单的来说结构关系的意思。基于拓扑的网页分析又可以被定义为:基于网页粒度的分析算法、基于网页块粒度的分析算法、基于网页粒度的分析算法。
PageRank算法是一种比较典型的基于网页粒度的分析算法。他是谷歌搜索引擎的核心算法,简单来说,它会根据网页之间的链接关系对网页的权重进行计算,并可以依靠这些计算出来的权重,对网页进行排名。
基于网页块粒度的分析算法中,也是依靠网页间链接关系进行计算的,但计算规则有所不同。我们知道,在一个网页中通常包含多个超链接,但是一般指向的外部链接并不是所有的链接都与网站主题相关,或者是,这些外部链接对该网页的重要程度是不一样的,所以若要给基于网页块粒度进行分析,则需要对一个网页中的一些外部链接进行划分层次,不同层次的外部链接对于该网页来说,其重要程度不同。这种算法的分析效率和准确率,会比传统的算法好一些。
基于网站粒度的分析算法,也与PagePank算法类似,但是,如果采用基于网站粒度进行分析,相应的,会使用SiteRank算法。此时我们会划分站点的层次和等级,而不再具体计算站点下的各网页的等级。所以其相对于基于网页粒度的算法来说,则更加简单高效,但是会带来一点缺点,如精度较低。
3)基于网页内容分析算法
在基于网页内容分析算法中,会依据网页的数据、文本等网页内容特征。对网页进行相应的评价。
Urllib库与URLError异常处理
快速使用Urllib爬取网页
# 导入模块
import urllib.request
# 将爬取的网页赋值给变量file
file = urllib.request.urlopen("http://www.baidu.com")
# 读取网页全部内容
data = file.read() # 读取文件钱不能容
# 读取一行内容
dataline = file.readline() # 读取文件首行
# 读取全部内容
datalines = file.readlines() # 读取文件首行
# 网页保存
fhandle = open('', 'wb')
fhandle.write(data)
fhandle.close()
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











