






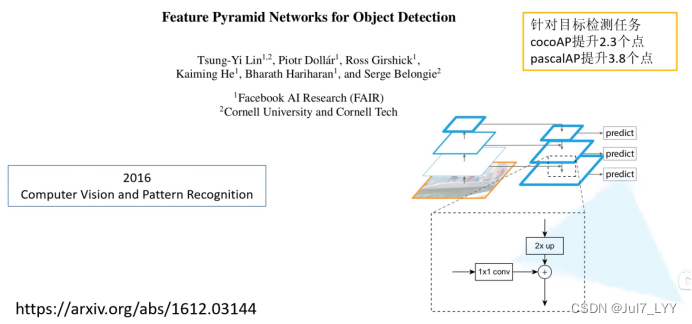
论文题目:Feature Pyramid Networks for Object Detection
论文链接:论文链接
文章目录
一、FPN的引入
1.FPN创新点
如何创建网络内的特征金字塔,可以用来取代特征图像金字塔,而不牺牲表征能力、速度或内存。
特点:高层feature map上采样后和低层feature map进行特征融合
1.FPN 构架了一个可以进行端到端训练的特征金字塔
2.通过CNN网络的层次结构高效的进行强特征计算
3.通过结合bottom-up(自底向上)与top-down(自上向下)方法获得较强的语义特征,提高目标检测和实例分割在多个数据集上面的性能表现 (这是最重要的创新点)
4.FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等
2.为什么需要构造特征金字塔?
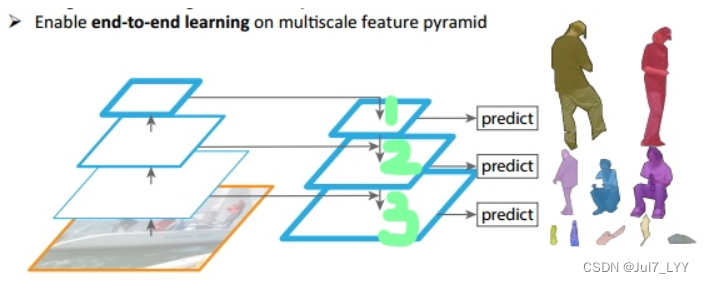
1.特征金字塔可以在速度和准确率之间进行权衡,可以通过它获得更加鲁棒的语义信息。
2.如上图所示,我们可以看到我们的图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。图中我们在第1层(请看绿色标注)输出较大目标的实例分割结果,在第2层输出次大目标的实例检测结果,在第3层输出较小目标的实例分割结果。检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
3.为什么要提出FPN算法?
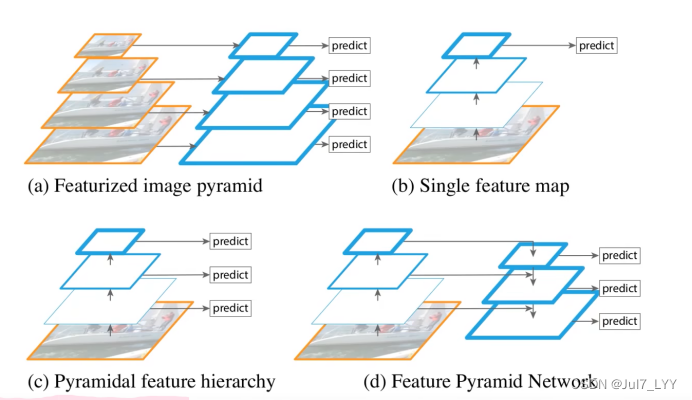
上述图片来自原论文:
(a)识别不同大小的物体是计算机视觉中的一个基本挑战,我们常用的解决方案是构造多尺度金字塔。如上图a所示,这是一个特征图像金字塔,整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测(BB的位置)。
缺点计算量大,需要大量的内存;优点可以获得较好的检测精度。
(b)典型例子Fast-RCNN这是一种改进的思路,学者们发现我们可以利用卷积网络本身的特性,即对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map,这样其实就类似于在图像的特征空间中构造金字塔。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。
优点速度快、需要内存少。缺点我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
(c)典型例子SSD同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。
优点在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。缺点获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
(d)FPN首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。这次我们使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
二、FPN框架解析
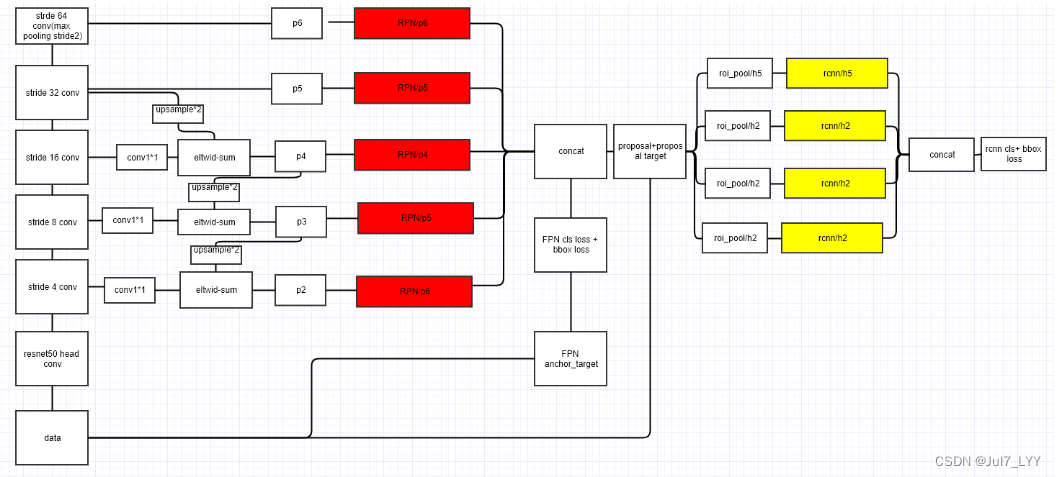
1. 利用FPN构建Faster R-CNN检测器步骤
1.首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
2.然后,将处理过的图片送入预训练的特征网络中(如ResNet50等),即构建所谓的bottom-up(自底向上)网络;
3.接着,如下图所示,构建对应的top-down网络(即对C5进行上采样操作,先用1x1的卷积进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作);
4.接着,在图中的p2-p6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
5.接着,将上一步获得的候选ROI分别输入到p2-p6层上面分别进行ROI Pool操作(固定为7x7的特征);
6.最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;
RPN在生成proposal时会用到p2-p6,进行预测。但是faster-rcnn只会在p2-p5上使用。后边的部分还是使用的faster-rcnn。(这一块结合着fasterr-cnn理解)
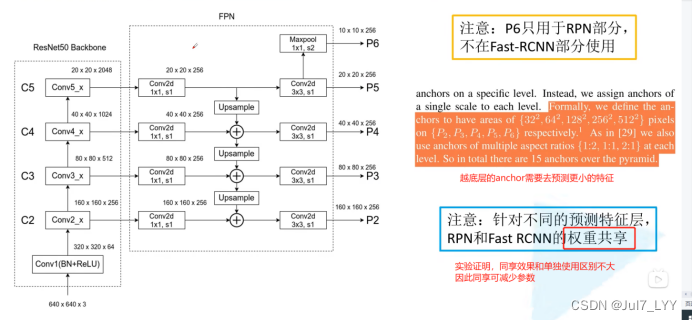
注:C2-C5对应的支路就是bottom-up网络,就是所谓的预训练网络,文中使用了ResNet网络;由于整个流向是自底向上的,所以我们叫它bottom-up;P2-P6对应的支路就是所谓的top-down网络,是FPN的核心部分。
2.为什么FPN能够很好的处理小目标?
首先要知道越底层的预测越能关注到小目标
Fast-RCNN不能检测小目标的原因:scale的问题,faster rcnn只在con5_3进行roi pooling,这一层的特征对应原图的scale都是很大的,因为进行了4次下采样,一个44的anchor对应原图6464的object,自然无法对小目标进行有效的特征提取了。
然而FPN不单单是对backbone上的特征图像进行预测,而是将不同的特征图像进行融合,融合后的特征图上进行预测。利用经过top-down模型后的那些上下文信息(高层语义信息)。
3.RPN预测到的proposal如何映射?
提出问题:
我们通过RPN预测到的proposal怎么映射到对应的预测特征层上呢?
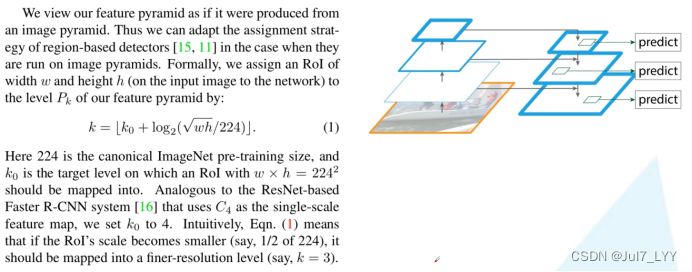
这里的k代表的是p2-p5,k0=4,w、h分别代表候选框在特征图上的宽和高。
4.FPN框架图
三、其他细节
1.为什么提出多尺度?
多尺度是目标检测与图像分类两个任务的一大区别。分类问题通常针对同一种尺度,如ImageNet中的224大小;而目标检测中,模型需要对不同尺度的物体都能检测出来
2.在RPN中放置FPN
我们的金字塔表示法大大提高了RPN对目标尺度变化的鲁棒性。
3.权重共享
在fasterrcnn上会用到rpn和fastrcnn模块,但是在rpn每个不同的预测特征层rpn(p2-p6)和fastrcnn(p2-p5)的权重共享
















 1325
1325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











